@TOC
Introduction
在计算机视觉三维重建中,求解3D场景的表示和定位给定的相机帧的相机位姿是两个非常重要的任务,这两个问题互为依赖,一方面,恢复3D场景的表示需要使用已知的相机位姿进行观察;另一方面,定位相机需要来自特征点的可靠对应。
错误的相机位姿会对重建的输出和性能产生一系列负面影响,包括:
图像合成质量下降:
当相机位姿不准确时,生成的视角合成图像可能会出现明显的畸变或模糊,导致最终图像的质量较差。
三维场景表示不准确:
错误的位姿会导致三维场景中的几何结构和深度信息的错误重建,使得模型无法正确理解场景的空间布局。
影像重叠和视差问题:
不准确的位姿可能会造成图像重叠区域的视差不一致,进而导致合成图像中的物体位置、大小等出现明显的不自然或错位现象。
优化过程的困难:
由于相机位姿的误差,优化算法(如Adam)可能会在优化过程中陷入局部最优解,无法收敛到正确的场景表示和相机位置。
训练效率降低:
不准确的相机位姿会使得训练过程变得更加复杂,模型需要更多的迭代才能调整出合理的场景表示,从而延长训练时间。
潜在的视觉伪影:
由于误差,合成图像可能出现视觉伪影(artifacts),如不连贯的阴影、错误的光照等,使得生成的图像看起来不真实。
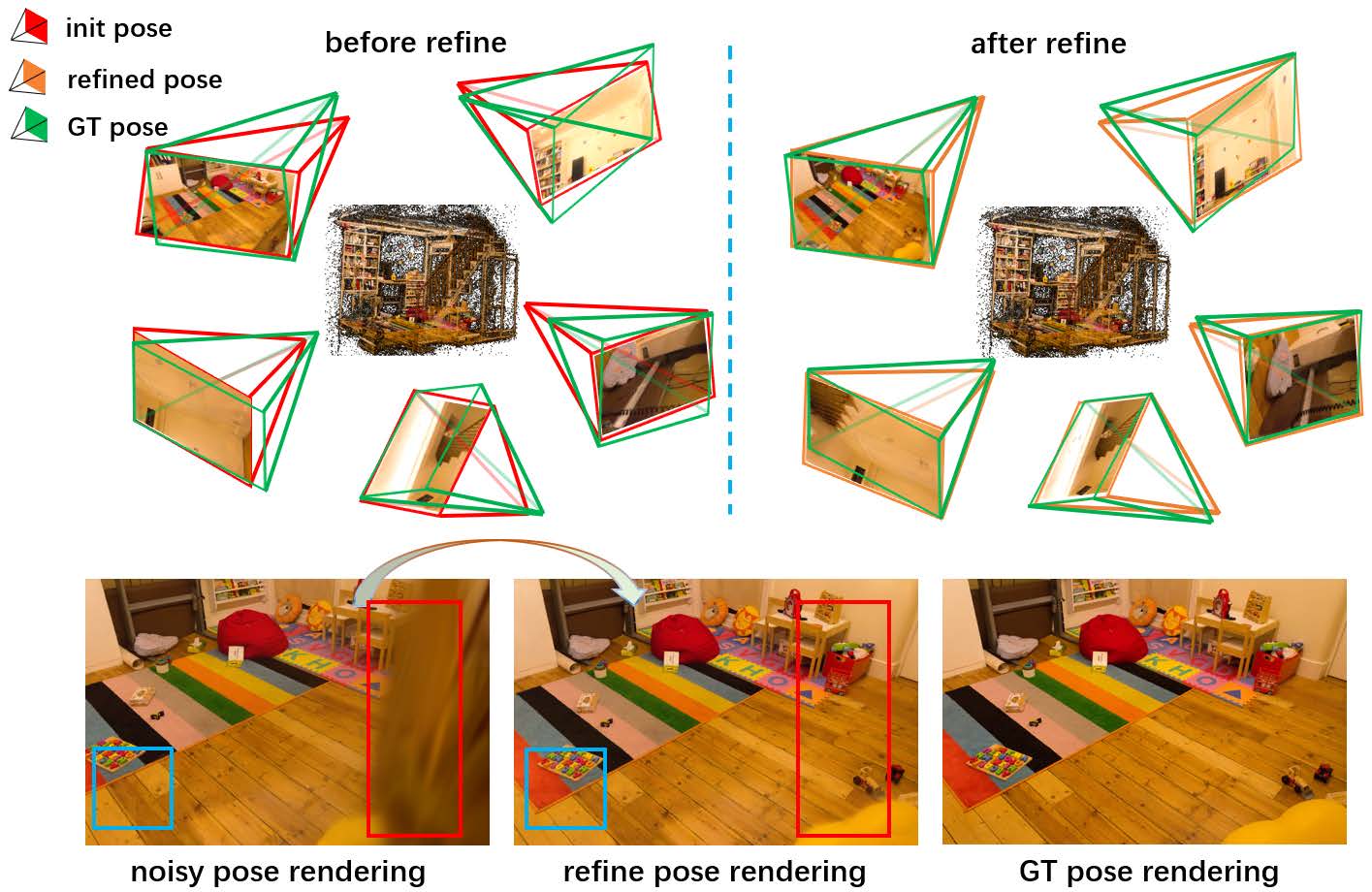
红框是伪影,蓝框是错位。
在《3D Gaussian Splatting for Real-Time Radiance Field Rendering》发布后,很多重建方法都尝试在3D表征上进行创新,它们普遍使用预输入的相机位姿进行重建,而不同时考虑相机位姿的校准,这些预输入的相机位姿通常是由colmap软件估计得到的。此次介绍的两篇文章《BARF》和《HGSLoc》在进行场景重建的同时进行相机位姿的优化,它们使用一些来自不同视角的图像和这些图像的粗略位姿作为输入,并且在相机位姿优化的方法上做出了改进。
Approach
Planar Image Alignment(2D)
首先,BARF考虑2D的平面图像对齐问题。
设x∈R2为像素坐标系下的一个坐标,W:R2→R2是与相机参数p有关的几何变换,I:R2→R3是我们的图像生成过程(图像的3个通道,所以是R2→R3), 我们的目标是使得生成的图片与原图片尽可能地相似,这个联合优化的目标用最小二乘来表达,就是:
pminx∑∥I1(W(x;p))−I2(x)∥22. 相机参数的维度可以记作
p∈RP. 这个最小二乘问题的基础迭代步骤可以记作:
Δp=−A(x;p)x∑J(x;p)⊤(I1(W(x;p))−I2(x)). 其中,
J是从输出到待优化变量求导的雅克比矩阵,I2是给定的groundtruth,I1是我们想要优化的。而A(x;p)取决于我们选择的优化策略。 J(x;p)=∂W(x;p)∂I1(W(x;p))∂p∂W(x;p). 残差:
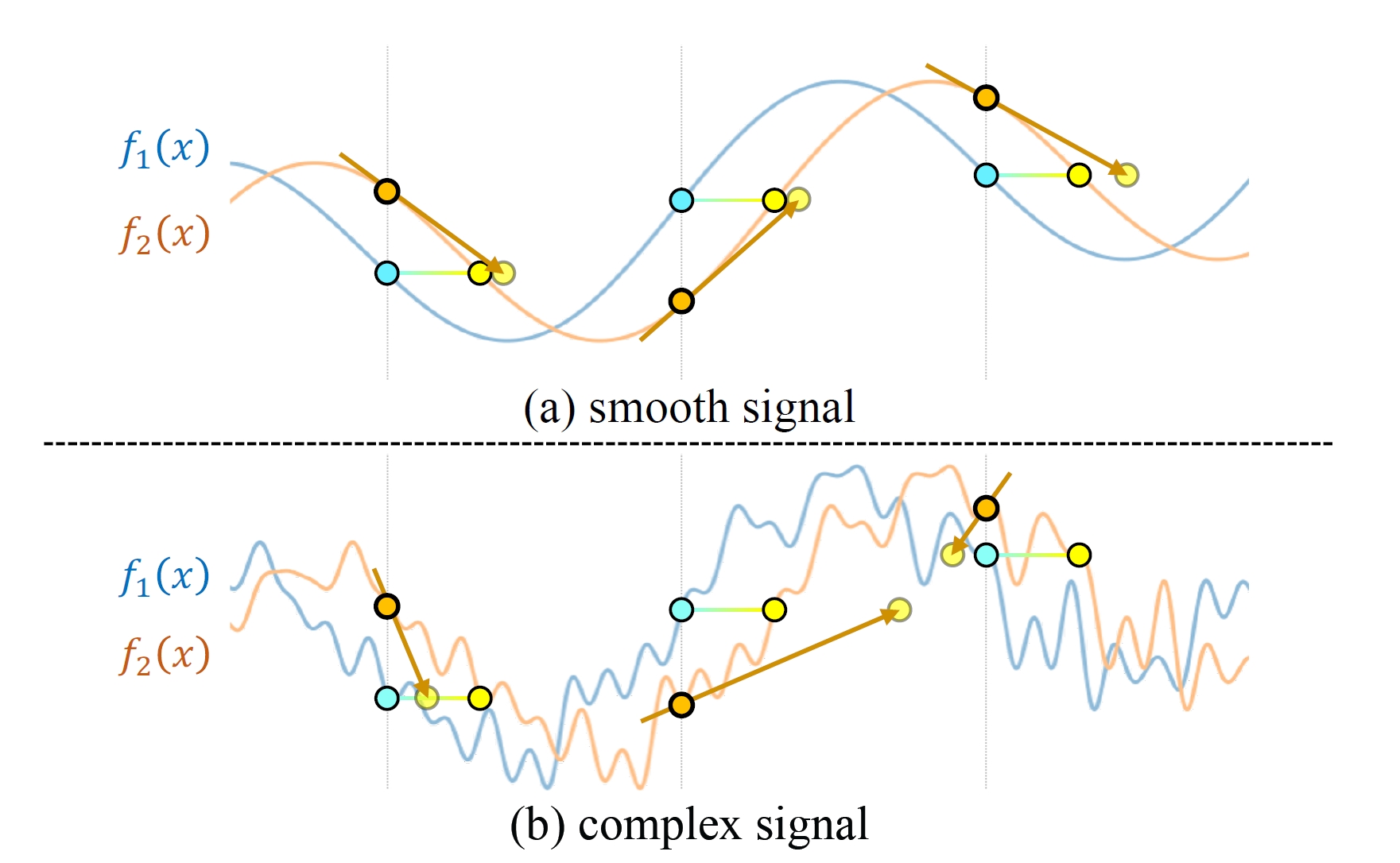
r(x)=I2(x)−I1(W(x;p)).有的资料中把J看作是残差对待优化变量的导数,即,∂p∂r,因此,Δp也可以写成: Δp=−A(x;p)x∑J(x;p)⊤r(x). 如果选择一阶优化方法,A就是一个标量,也就是学习率;如果选择二阶优化方法,有时A(x;p)=(∑xJ(x;p)⊤J(x;p))−1,这取决于具体的优化策略。 以上是对这个最小二乘问题的概述。这种基于梯度的优化策略的核心在于输入信号是否足够平滑,否则,很容易陷入局部次优解。输入信号的平滑程度等价于:
∂x∂I(x),亦即图像梯度。 为了避免局部最优,通常在优化的前期对图像进行模糊处理。图像梯度通过数值差分方法得出,而并非解析的。
BARF并没有采用模糊操作,它用神经网络作为I,优化目标就可以写成:minpi,Θ∑i=1M∑x∥f(W(x;pi);Θ)−Ii(x)∥22其中,f:R2→R3,Θ是网络的参数,M是图像个数。然后,图像梯度就变为可解析的∂x∂f(x),而不是数值差分的估计。 通过操纵网络f,还可以对对齐的信号平滑度进行更原则性的控制,而不必依赖于图像的启发式模糊,从而使这些形式可推广到3D场景表示。稍后,将会介绍barf如何操作f对信号进行平滑度控制。
Neural Radiance Fields (3D)
接下来,BARF将以上过程拓展为3D,具体如下:
多层感知机:f:R3→R4,MLP参数:Θ,3D点坐标:x∈R3,3D点坐标对应的颜色:c∈R3,体素密度:σ∈R,相机位姿变换:W,其有6个自由度x,y,z,ϕ,θ,ψ,故p∈R6,且,[c;σ]⊤=f(x;Θ),像素齐次坐标:uˉ=[u;1]⊤∈R3,深度:zi,xi=ziuˉ. 体渲染表达式:
I^(u)=∫znearzfarT(u,z)σ(zuˉ)c(zuˉ)dz,其中,znear和zfar是感兴趣的深度上下限,I仍然是R2→R3,表示这个像素坐标对应的RGB数值。T(u,z)=exp(−∫zmaxzσ(z′uˉ)dz′). T对应3dgs中的透射率。这两个式子和3dgs的体渲染公式也是极为接近的:
Ci=n≤N∑cn⋅αn⋅Tn, where Tn=m<n∏(1−αm),αn=on⋅exp(−σn),σn=21Δn⊤Σ′−1Δn. 区别在于,3dgs中的T是通过累乘得出,体素密度则取决于椭球投影到平面的形状再乘以不透明度。而nerf中的颜色值和体素密度是通过MLP直接得出。
令y=[c;σ]⊤=f(x;Θ).继续改写:I^(u)=g(y1,…,yN),g:R4N→R3.I^(u;p)=g(f(W(z1uˉ;p);Θ),…,f(W(zNuˉ;p);Θ)),W:R3→R3. 最后,这个联合优化问题变为:
p1,...,pM,Θmini=1∑Mu∑I^(u;pi,Θ)−Ii(u)22. Bundle-Adjusting Neural Radiance Fields
barf与Nerf差异最大的一点在于,barf需要在优化网络参数的同时考虑到相机参数。而barf认为直接使用nerf的位置编码方案使得相机参数优化变得困难,对此,barf做出了改进,提出了捆绑优化的动态调整策略,这也是这篇文献最大的贡献之一。
Nerf最初的位置编码方案为:
γ(x)=[x,γ0(x),γ1(x),…,γL−1(x)]∈R3+6L. 这里的L是超参数。
γk(x)=[cos(2kπx),sin(2kπx)]∈R6. 那么,k阶位置编码的雅克比矩阵为:
∂x∂γk(x)=2kπ⋅[−sin(2kπx),cos(2kπx)]. 它将来自MLP的梯度信号放大,并且其方向以相同频率变化。这使得预测有效更新Δp变得困难,因为来自采样的3D点的梯度信号在方向和幅度方面是不相干的,并且很容易相互抵消。因此,对于barf的联合优化来说,不能直接应用位置编码。
barf的做法是从低频段到高频段逐步激活位置编码:
γk(x;α)=wk(α)⋅[cos(2kπx),sin(2kπx)],wk(α)=⎩⎨⎧021−cos((α−k)π)1if α<kif 0≤α−k<1if α−k≥1.∂x∂γk(x;α)=wk(α)⋅2kπ⋅[−sin(2kπx),cos(2kπx)].α∈[o,L]是与优化进度成正比的可控的一个超参数。 从原始3D输入x(α=0)开始,barf逐渐激活较高频段的编码,直到启用完整位置编码(α=L),相当于原始 NeRF 模型。这使得 BARF 能够通过最初平滑的信号发现正确的Δp,然后将重点转移到学习高保真场景表示。
Experiment
平面图像对齐的定性实验
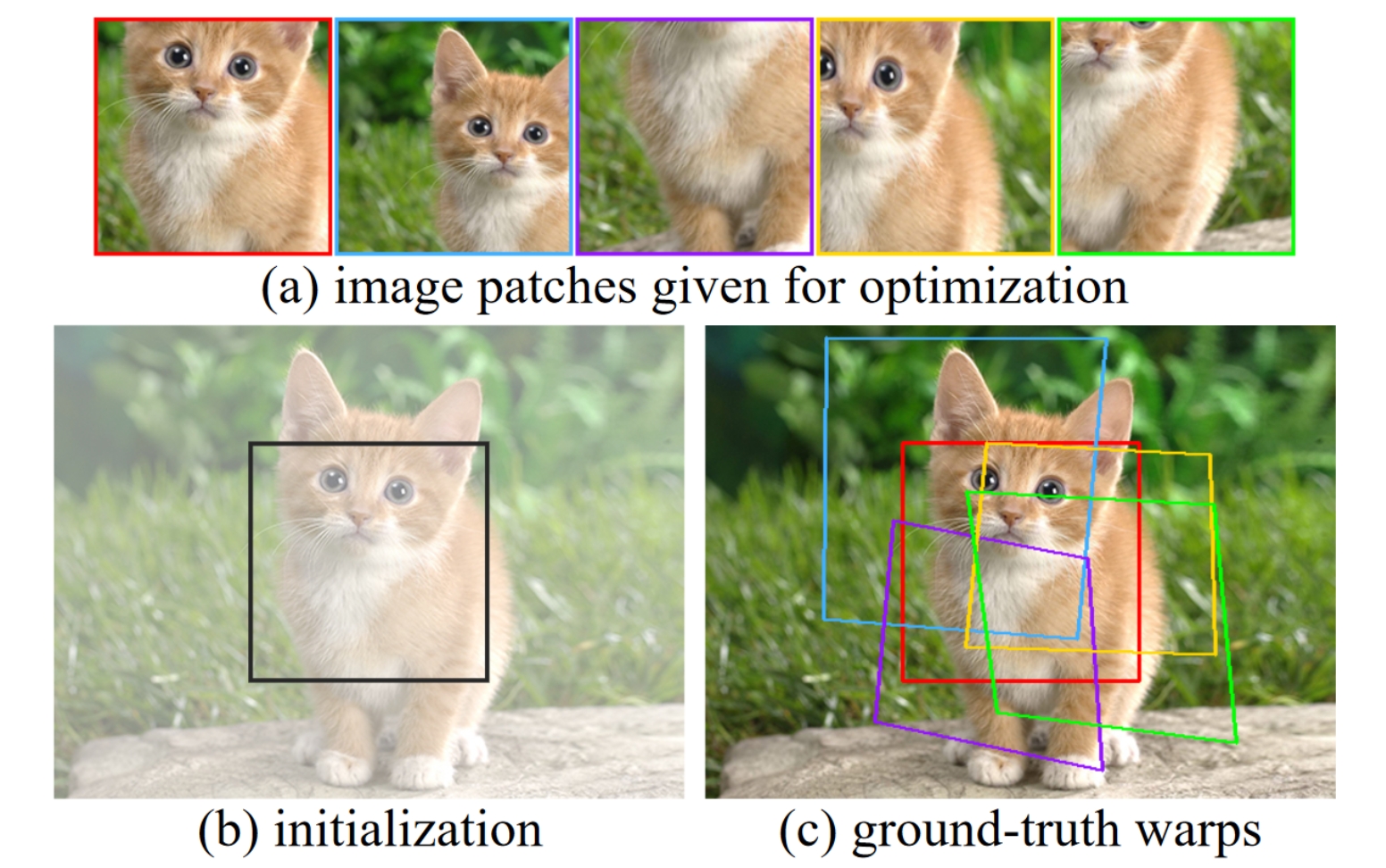
给定图像块,barf的目标是恢复整个图像的对齐和神经网络重建,其中初始化为(b)中所示的中心裁剪,而相应的真实变换(ground-truth warps)如(c)所示。
实验结果:(a)为直接使用位置编码,(b)为不使用位置编码,(c)是barf的结果。
合成场景上的定量实验
Scene
Camera pose registration
View synthesis quality
Last updated