【OpenCV教程】特征工程
@TOC
1.模板匹配
1.1 原理
模板图像在原图像上从原点开始移动,计算模板与原图被模板覆盖的地方的差别程度,计算方法有几种,然后将每次计算的结果放进输出矩阵。若原图像为A*B大小,模板为a*b大小,则 输出矩阵为(A-a+1)*(B-b+1) 大小。
1.2 API
CV_EXPORTS_W void matchTemplate( InputArray image, InputArray templ,
OutputArray result, int method, InputArray mask = noArray() );参数如下
image
输入图像,数据类型Mat
templ(template)
模板图像,数据类型Mat
result
输出矩阵,深度为CV_32FC1。若原图像为A*B大小,模板为a*b大小,则 输出矩阵为(A-a+1)*(B-b+1) 大小。
method
模板匹配计算方法。详见下文
mask
掩码图像。其大小与模板图像必须相同,且必须为灰度图。匹配时,对于掩码中的非0像素匹配算法起作用,掩码中的灰度值为0的像素位置,匹配算法不起作用。
1.3 模板匹配计算方法
enum TemplateMatchModes {
TM_SQDIFF = 0,
TM_SQDIFF_NORMED = 1,
TM_CCORR = 2,
TM_CCORR_NORMED = 3,
TM_CCOEFF = 4,
TM_CCOEFF_NORMED = 5
};method可选值如下
TM_SQDIFF
计算平方误差,计算出来的值越小,则匹配得越好
Rsq_diff=∑x′,y′[T(x′,y′)−I(x+x′,y+y′)]2
TM_SQDIFF_NORMED
计算归一化平方误差,计算出来的值越接近0,则匹配得越好
Rsq_diff_normed=∑x′,y′T(x′,y′)2⋅∑x′,y′I(x+x′,y+y′)2∑x′,y′[T(x′,y′)−I(x+x′,y+y′)]2
TM_CCORR
计算相关性,计算出来的值越大,则匹配得越好
Rccorr=∑x′,y′T(x′,y′)⋅I(x+x′,y+y′)
TM_CCORR_NORMED
计算归一化相关性,计算出来的值越接近1,则匹配得越好
Rccorr_normed=∑x′,y′T(x′,y′)2⋅∑x′,y′I(x+x′,y+y′)2∑x′,y′T(x′,y′)⋅I(x+x′,y+y′)
TM_CCOEFF
计算相关系数,计算出来的值越大,则匹配得越好
Rccoff=∑x′,y′T′(x′,y′)⋅I′(x+x′,y+y′),T′(x′,y′)=T(x′,y′)−w⋅h∑x′,y′T(x′′,y′′),I′(x′,y′)=I(x′,y′)−w⋅h∑x′,y′I(x′′,y′′)
TM_CCOEFF_NORMED
计算归一化相关系数,计算出来的值越接近1,则匹配得越好
Rccoeff_normed=∑x′,y′T′(x′,y′)2⋅∑x′,y′I′(x+x′,y+y′)2∑x′,y′T′(x′,y′)⋅I′(x+x′,y+y′)
1.4 掩码的使用
在进行特征匹配时,我们有时并不需要用整个图片作为模板,因为模板的背景可能会干扰匹配的结果。因此,我们需要加入掩码,就可以屏蔽掉背景进行模板匹配
获得掩码
模板图像转灰度图
二值化屏蔽背景
1.5 效果


1.5 模板匹配的缺陷
无法应对旋转

无法应对缩放

2.cornerHarris(对灰度图)
2.1 角点的描述
一阶导数(即灰度的梯度)的局部最大所对应的像素点;
两条及两条以上边缘的交点;
图像中梯度值和梯度方向的变化速率都很高的点;
角点处的一阶导数最大,二阶导数为零,指示物体边缘变化不连续的方向。
2.2 原理(前置知识要求:线性代数)(以下为bolcksize=2的情况)
使用一个固定窗口在图像上进行任意方向上的滑动,比较滑动前与滑动后两种情况,窗口中的像素灰度变化程度,如果存在任意方向上的滑动,都有着较大灰度变化,那么我们可以认为该窗口中存在角点。考虑到一个灰度图像,使用划动窗口(with displacements在x方向和y方向) 计算像素灰度变化。
其中:
w(x,y) is the window at position (x,y)
I(x,y) is the intensity at (x,y)
I(x+u,y+v) is the intensity at the moved window (x+u,y+v)、
为了寻找带角点的窗口,搜索像素灰度变化较大的窗口。于是, 我们期望最大化以下式子:
泰勒展开:
Ix,Iy是通过sobel算子计算的一阶导数
矩阵化:
得二次型:
因此有等式:
每个窗口中计算得到一个值。这个值决定了这个窗口中是否包含了角点。
其中,det(M) = 矩阵M的行列式,trace(M) = 矩阵M的迹
R为正值时,检测到的是角点,R为负时检测到的是边,R很小时检测到的是平坦区域。
2.3 API
参数如下
src(source)
输入图片**(灰度图)**,深度要求:CV_8UC1或CV_32FC1
dst(destination)
输出图片,数据类型Mat
bolckSize
检测窗口的大小,越大则对角点越敏感,一般取2
ksize(kernal size)
使用sobel算子计算一阶导数时的滤波器大小,一般取3即可。
k
计算用到的系数,公认一般取值在0.02~0.06。
borderType
边界填充方式,默认为黑边。
2.4 流程
转灰度图
使用cornerHarris函数检测
使用normalize函数归一化处理和convertScaleAbs绝对化
遍历输出图像并筛选角点。不要使用迭代器的遍历方式,因为太慢!
经过实测,以下这种用行数调用ptr函数的遍历方式是最快的

2.5 优点与缺点
测试代码
图片旋转,角点不变


图片缩放,角点改变


3.Shi-Tomasi(对灰度图)
3.1 原理
由于cornerHarris角点检的稳定性与k密切相关,而k是个经验值,难以设定最佳值,Shi-Tomasi在这一点上进行了改进
计算角点分数
3.2 API
参数如下
image
输入图片**(灰度图)**,深度要求:CV_8UC1或CV_32FC1
corners
输出角点的点集,数据类型vector<Point2f>
maxCorners
控制输出角点点集的上限个数,即控制corners.size()。输入0则表示不限制上限
qualityLevel
质量系数(小于1.0的正数,一般在0.01-0.1之间),表示可接受角点的最低质量水平。该系数乘以输入图像中最大的角点分数,作为可接受的最小分数;例如,如果输入图像中最大的角点分数值为1500且质量系数为0.01,那么所有角点分数小于15的角都将被忽略。
minDistance
角点之间的最小欧式距离,小于此距离的点将被忽略。
mask
掩码图像。其大小与输入图像必须相同,且必须为灰度图。计算时,对于掩码中的非0像素算法起作用,掩码中的灰度值为0的像素位置,算法不起作用。
blockSize
检测窗口的大小,越大则对角点越敏感。
useHarrisDetector
用于指定角点检测的方法,如果是true则使用Harris角点检测,false则使用Shi Tomasi算法。默认为False。
k
默认为0.04,只有useHarrisDetector参数为true时起作用。
3.3 流程
转灰度图
使用Shi-Tomasi函数检测
遍历角点集合即可
3.4 效果
Shi-Tomasi同样具有旋转不变性和尺度可变性
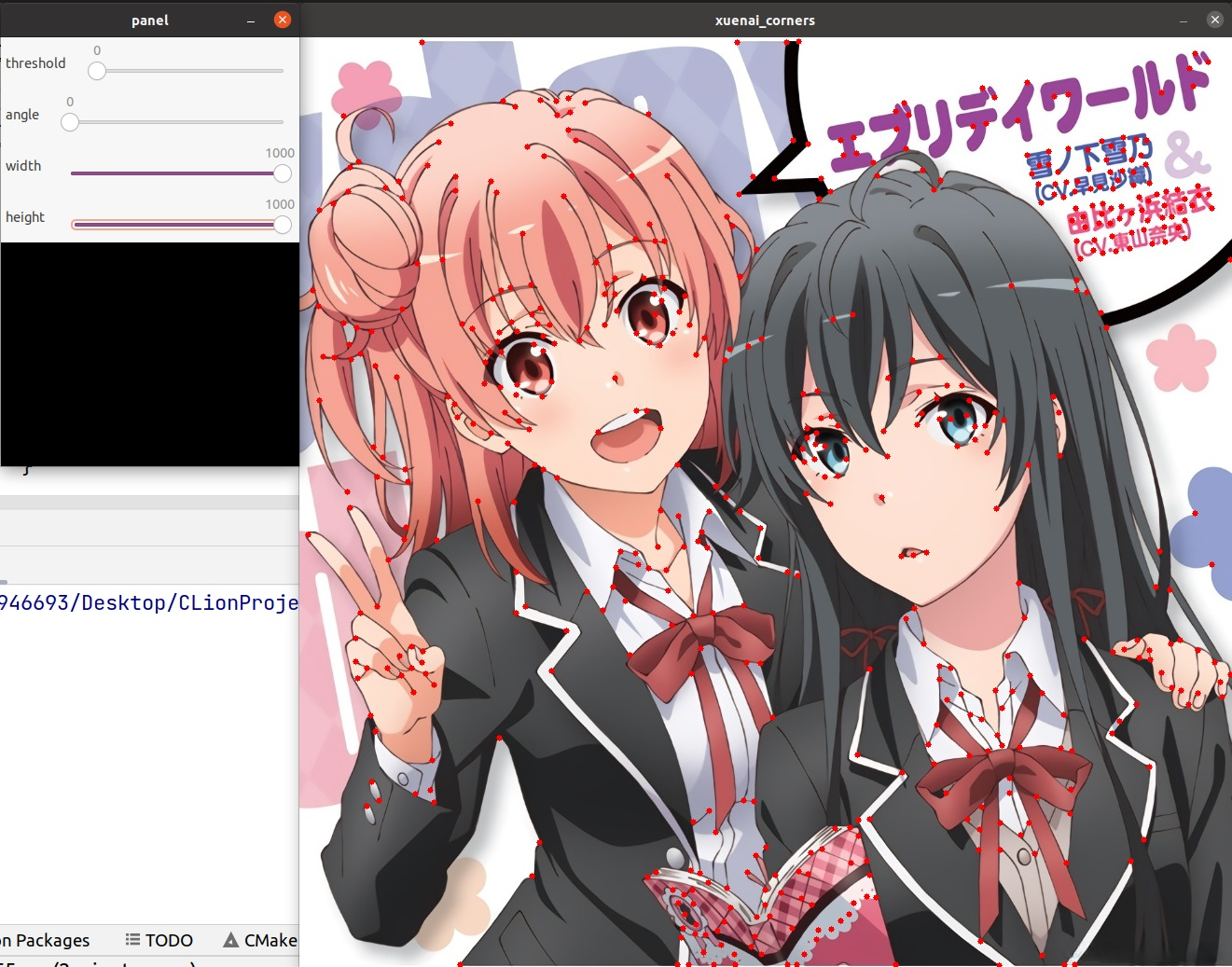


4.SIFT与SURF(对灰度图)
4.1 概述
cornerHarris和Shi-Tomasi都没能保证角点在尺度上的稳定性,因此SIFT和SURF针对这一特点进行了优化。由于其数学原理较为复杂,请自行查阅相关论文和文献,本文不再赘述。 相较于cornerHarris和Shi-Tomasi,SIFT和SURF的优点是显著的,其检测出的角点对旋转、尺度缩放、亮度变化等保持不变性,对视角变换、仿射变化、噪声也保持一定程度的稳定性,是一种非常优秀的局部特征描述算法。 需要注意的是,SIFT和SURF的计算量较为庞大,难以做到实时运算。SIFT和SURF两者相比,SIFT更为精确,SURF更为高效。
4.2 API
构造函数
构造函数的参数设计复杂的数学原理,在此不进行解释,在使用时进行默认的构造即可。
关键点检测
参数如下
image
输入图像**(灰度图)**,深度要求:CV_8UC1或CV_32FC1
keypoints
含多个关键点的vector<KeyPoint>。使用detect时作为输出,使用compute时作为输入,使用detectAndCompute时可以作为输入也可以作为输出。
mask
掩码图像。其大小与输入图像必须相同,且必须为灰度图。计算时,对于掩码中的非0像素算法起作用,掩码中的灰度值为0的像素位置,算法不起作用。
描述子计算
参数如下
image
输入图片**(灰度图)**,深度要求:CV_8UC1或CV_32FC1
keypoints
含多个关键点的vector<KeyPoint>。使用detect时作为输出,使用compute时作为输入,使用detectAndCompute时可以作为输入也可以作为输出。
descriptors
描述子,数据类型Mat。在进行特征匹配的时候会用到。
useProvidedKeypoints
false时,keypoints作为输出,并根据keypoints算出descriptors。true时,keypoints作为输入,不再进行detect,即不修改keypoints,并根据keypoints算出descriptors。
drawKeypoints绘制关键点
参数如下
image
输入图像,数据类型Mat
keypoints
含多个关键点的vector<KeyPoint>
outImage
输出图像,数据类型Mat
color
绘制颜色信息,默认绘制的是随机彩色。
flags
特征点的绘制模式,其实就是设置特征点的那些信息需要绘制,那些不需要绘制。详见下表
flags可选值如下
DrawMatchesFlags::DEFAULT
只绘制特征点的坐标点,显示在图像上就是一个个小圆点,每个小圆点的圆心坐标都是特征点的坐标。
DrawMatchesFlags::DRAW_OVER_OUTIMG
函数不创建输出的图像,而是直接在输出图像变量空间绘制,要求本身输出图像变量就是一个初始化好了的,size与type都是已经初始化好的变量。
DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS
单点的特征点不被绘制
DrawMatchesFlags::DRAW_RICH_KEYPOINTS
绘制特征点的时候绘制的是一个个带有方向的圆,这种方法同时显示图像的坐标,size和方向,是最能显示特征的一种绘制方式。
4.3 流程
实例化SIFT或SURF对象
将输入图像转灰度图
根据需要,调用detect函数或compute函数或detectAndCompute函数,检测关键点和计算描述子
调用drawKeypoints函数绘制关键点
4.4 效果

进行缩放和旋转


可以看到,无论是旋转还是缩放,关键点都保持得非常稳定。
5.FAST到OBR(对灰度图)
5.1 概述
前文已经阐述,SIFT和SURF已经做到了角点在旋转和缩放下的稳定性,但是它们还有一个致命的缺陷,就是它们难以做到实时运算,因此,FAST和OBR应运而生了。
FAST原理
从图片中选取一个坐标点P,获取该点的像素值,接下来判定该点是否为特征点。
选取一个以选取点P坐标为圆心的半径等于r的Bresenham圆(一个计算圆的轨迹的离散算法,得到整数级的圆的轨迹点),一般来说,这个圆上有16个点:

p在图像中表示一个被识别为兴趣点的像素。令它的强度为 Ip;
选择一个合适的阈值t;
考虑被测像素周围的16个像素的圆圈。 如果这16个像素中存在一组ñ个连续的像素的像素值,比 Ip+t 大,或比 Ip−t小,则像素p是一个角点。ñ被设置为12。
使用一种快速测试(high-speed test)可快速排除了大量的非角点。这个方法只检测在1、9、5、13个四个位置的像素,(首先检测1、9位置的像素与阈值比是否太亮或太暗,如果是,则检查5、13)。如果p是一个角点,则至少有3个像素比 Ip+t大或比 Ip−t暗。如果这两者都不是这样的话,那么p就不能成为一个角点。然后可以通过检查圆中的所有像素,将全部分段测试标准应用于通过的对候选的角点。这种探测器本身表现出很高的性能,但有一些缺点:
它不能拒绝n <12的候选角点。当n<12时可能会有较多的候选角点出现
检测到的角点不是最优的,因为它的效率取决于问题的排序和角点的分布。
角点分析的结果被扔掉了。过度依赖于阈值
多个特征点容易挤到一起。
前三点是用机器学习方法解决的。最后一个是使用非极大值抑制来解决。具体不再展开。
FAST算法虽然很快,但是没有建立关键点的描述子,也就无法进行特征匹配
OBR简介
ORB 是 Oriented Fast and Rotated Brief 的简称,从这个简介就可以看出,OBR算法是基础FAST算法的改进。其中,Fast 和 Brief 分别是特征检测算法和向量创建算法。ORB 首先会从图像中查找特殊区域,称为关键点。关键点即图像中突出的小区域,比如角点,比如它们具有像素值急剧的从浅色变为深色的特征。然后 ORB 会为每个关键点计算相应的特征向量。ORB 算法创建的特征向量只包含 1 和 0,称为二元特征向量。1 和 0 的顺序会根据特定关键点和其周围的像素区域而变化。该向量表示关键点周围的强度模式,因此多个特征向量可以用来识别更大的区域,甚至图像中的特定对象。 关于Brief算法的具体原理本文不再赘述,请自行查阅相关论文和文献。
5.2 API
构造函数
threshold:进行FAST检测时用到的阈值,阈值越大检测到的角点越少
5.3 流程
实例化FAST或OBR对象
将输入图像转灰度图
根据需要,调用detect函数或compute函数或detectAndCompute函数,检测关键点和计算描述子
调用drawKeypoints函数绘制关键点
5.4 效果
调整threshold


进行缩放和旋转

错误
前文已经提及,FAST算法不支持描述子的计算
6.Brute-Force与FLANN特征匹配
6.1 概述
Brute-Force
暴力匹配(Brute-force matcher)是最简单的二维特征点匹配方法。对于从两幅图像中提取的两个特征描述符集合,对第一个集合中的每个描述符Ri,从第二个集合中找出与其距离最小的描述符Sj作为匹配点。 暴力匹配显然会导致大量错误的匹配结果,还会出现一配多的情况。通过交叉匹配或设置比较阈值筛选匹配结果的方法可以改进暴力匹配的质量。
如果参考图像中的描述符Ri与检测图像中的描述符Sj的互为最佳匹配,则称(Ri , Sj)为一致配对。交叉匹配通过删除非一致配对来筛选匹配结果,可以避免出现一配多的错误。
比较阈值筛选是指对于参考图像的描述符Ri,从检测图像中找到距离最小的描述符Sj1和距离次小的描述符Sj2。设置比较阈值t∈[0.5 , 0.9],只有当最优匹配距离与次优匹配距离满足阈值条件d (Ri , Sj1) ⁄ d (Ri , Sj2) < t时,表明匹配描述符Sj1具有显著性,才接受匹配结果(Ri , Sj1)。
FLANN
相比于Brute-Force,FLANN的速度更快
由于使用的是邻近近似值,所以精度较差
6.2 API
构造函数
参数如下
normType
计算距离用到的方法,默认是欧氏距离。详见下表
crossCheck
是否使用交叉验证,默认不使用。
normType可选值如下
NORM_L1
L1范数,曼哈顿距离
NORM_L2
L2范数,欧氏距离
NORM_HAMMING
汉明距离
NORM_HAMMING2
汉明距离2,对每2个比特相加处理。
NORM_L1、NORM_L2适用于SIFT和SURF检测算法
NORM_HAMMING、NORM_HAMMING2适用于OBR算法
描述子匹配
匹配方式一
参数如下
queryDescriptors
描述子的查询点集,数据类型Mat,即参考图像的特征描述符的集合。
trainDescriptors
描述子的训练点集,数据类型Mat,即检测图像的特征描述符的集合。
matches
匹配结果,长度为成功匹配的数量。
mask
掩码图像。其大小与输入图像必须相同,且必须为灰度图。计算时,对于掩码中的非0像素算法起作用,掩码中的灰度值为0的像素位置,算法不起作用。
特别注意和区分哪个是查询集,哪个是训练集
匹配方式二
参数如下
queryDescriptors
描述子的查询点集,数据类型Mat,即参考图像的特征描述符的集合。
trainDescriptors
描述子的训练点集,数据类型Mat,即检测图像的特征描述符的集合。
matches
vector<std::vector<DMatch>>类型,对每个特征点返回k个最优的匹配结果
k
返回匹配点的数量
mask
掩码图像。其大小与输入图像必须相同,且必须为灰度图。计算时,对于掩码中的非0像素算法起作用,掩码中的灰度值为0的像素位置,算法不起作用。
特别注意和区分哪个是查询集,哪个是训练集
Brute-Force与FLANN对输入描述子的要求
Brute-Force要求输入的描述子必须是CV_8U或者CV_32S
FLANN要求输入的描述子必须是CV_32F
drawMatches绘制匹配结果
参数如下
img1(image1)
源图像1,数据类型Mat
keypoints1
源图像1的关键点
img2(image2)
源图像2,数据类型Mat
keypoints2
源图像2的关键点
matches1to2
源图像1的描述子匹配源图像2的描述子的匹配结果
outImg(out image)
输出图像,数据类型Mat
matchColor
匹配的颜色(特征点和连线),默认Scalar::all(-1),颜色随机
singlePointColor
单个点的颜色,即未配对的特征点,默认Scalar::all(-1),颜色随机
matchesMask
掩码,决定哪些点将被画出,若为空,则画出所有匹配点
flags
特征点的绘制模式,其实就是设置特征点的那些信息需要绘制,那些不需要绘制。
6.3 流程
实例化BFMatcher对象
根据需要,调用match函数或knnMatch函数,进行特征匹配
调用drawMatches函数呈现原图,并且绘制匹配点
6.4 效果
不进行比率筛选


进行比率筛选




7.单应性矩阵
7.1 概述
使用最小均方误差或者RANSAC方法,计算多个二维点对之间的最优单映射变换矩阵 H(3行x3列),配合perspectivetransform函数,可以实现对图片的矫正

7.2 API
findHomography
参数如下
srcPoints
源平面中点的坐标矩阵,可以是CV_32FC2类型,也可以是vector<Point2f>类型
dstPoints
目标平面中点的坐标矩阵,可以是CV_32FC2类型,也可以是vector<Point2f>类型
method
计算单应矩阵所使用的方法。不同的方法对应不同的参数,参考如下表格。
ransacReprojThreshold
将点对视为内点的最大允许重投影错误阈值(仅用于RANSAC和RHO方法)。若srcPoints和dstPoints是以vector<Point2f>为单位的,则该参数通常设置在1到10的范围内,建议选择5
mask
可选输出掩码矩阵。通常由鲁棒算法(RANSAC或LMEDS)设置。 请注意,输入掩码矩阵是不需要设置的。
maxIters
RANSAC算法的最大迭代次数,默认值为2000
confidence
可信度值,取值范围为0到1
method可选值如下
0
利用所有点的常规方法
RANSAC
基于RANSAC的鲁棒算法
LMEDS
最小中值鲁棒算法
RHO
基于PROSAC的鲁棒算法
perspectivetransform
perspectivetransform函数与warpPerspective函数的区别在于:
perspectivetransform是对
vector<Point2f>进行变换warpPerspective是对Mat进行变换
7.2 流程
通过特征检测算法检测关键点和计算描述子
通过特征匹配算法得到匹配结果
对匹配结果进行遍历,用DMatch.queryIdx成员变量和DMatch.trainIdx成员变量,分别对查询的关键点集合和训练的关键点集合进行索引,并用KeyPoint.pt成员变量得到其坐标,这样就得到了两个
vector<Point2f>调用findHomography函数获得单应性矩阵
调用perspectivetransform函数对查询图的四角对应坐标点集
vector<Point2f>进行变换,就得到了我们想要查找的图片在训练图中的四角对应坐标点集vector<Point2f>用polylines函数在训练图中画出结果
7.3 效果

最后更新于