三维视觉修复
@TOC
GSFix3D: Diffusion-Guided Repair of Novel Views in Gaussian Splatting (2024)
输入:
一个初始的、可能存在瑕疵的 3D高斯溅射 (3DGS) 模型。
一个对应的 3D网格 (Mesh) 模型 (作为几何先验)。
一个需要生成高质量图像的 新视角位姿。
输出:
一个经过优化和修复的 3D高斯溅射模型。
从新视角渲染出的 高质量、无瑕疵的2D图像。
解决的任务:
修复3D高斯溅射在新视角下的渲染瑕疵。当从训练时未见过的、视角较为极端的位置渲染图像时,3DGS会产生空洞、浮动块等问题。
GSFix3D利用一个定制的扩散模型(GSFixer)来“脑补”和修复单张2D图像的瑕疵,然后通过一种创新的蒸馏方法,将2D图像的修复结果“写回”到3D模型中,从而提升整个3D场景的质量和真实感。
Motivation
这篇文章的核心动机是为了解决3D高斯溅射(3DGS)方法的一个关键痛点。
3DGS的局限性: 3DGS作为一种新兴的、高效的3D场景表示方法,能够实现高质量的实时渲染。然而,它的效果严重依赖于密集且覆盖全面的输入视角。当从训练视角之外的极端新视角或在观测不足的区域进行渲染时,3DGS往往会产生各种视觉瑕疵(artifacts),例如:
空洞 (Holes):场景中由于缺乏观测数据而出现的黑色或空白区域。
浮动块 (Floaters):场景中出现的不符合几何逻辑的、漂浮在空中的彩色斑点或团块。
不完整的几何结构:物体表面残缺不全,几何形状不自然。 这些问题严重影响了渲染图像的真实感和质量,限制了3DGS在需要自由视角漫游或处理稀疏输入数据时的应用。
扩散模型的潜力与挑战: 与此同时,以Stable Diffusion为代表的扩散模型在图像生成领域取得了巨大成功。它们从海量数据中学习到了强大的生成先验(generative priors),能够生成极其逼真和多样化的图像内容。这使得它们具备了修复和内容补全的潜力。 然而,直接将通用的扩散模型应用于3D重建修复任务面临以下挑战:
缺乏场景特异性:预训练的扩散模型不了解特定3D场景的几何和纹理信息,修复结果可能与场景的真实内容不一致。
缺乏3D一致性:对单张2D图像的修复无法保证从不同视角看过去的3D结构是一致的。
输入-输出不一致:扩散模型主要用于生成,而非精确修复,可能会过度修改图像中本已正确的部分。
核心动机:本文旨在结合3DGS的快速渲染能力和扩散模型的强大生成先验,创建一个能够智能修复3DGS渲染瑕疵的框架。其目标是,在保留场景已有观测细节的基础上,利用扩散模型“脑补”出缺失或错误区域的合理内容,并最终将这种2D图像层面的修复结果 “蒸馏”回3D场景表示中,从而提升整个3D模型的质量。
Architecture
整个框架名为GSFix3D,其核心组件是一个经过特殊微调的扩散模型,名为GSFixer。整体流程如下图所示,可以分为三个主要阶段:
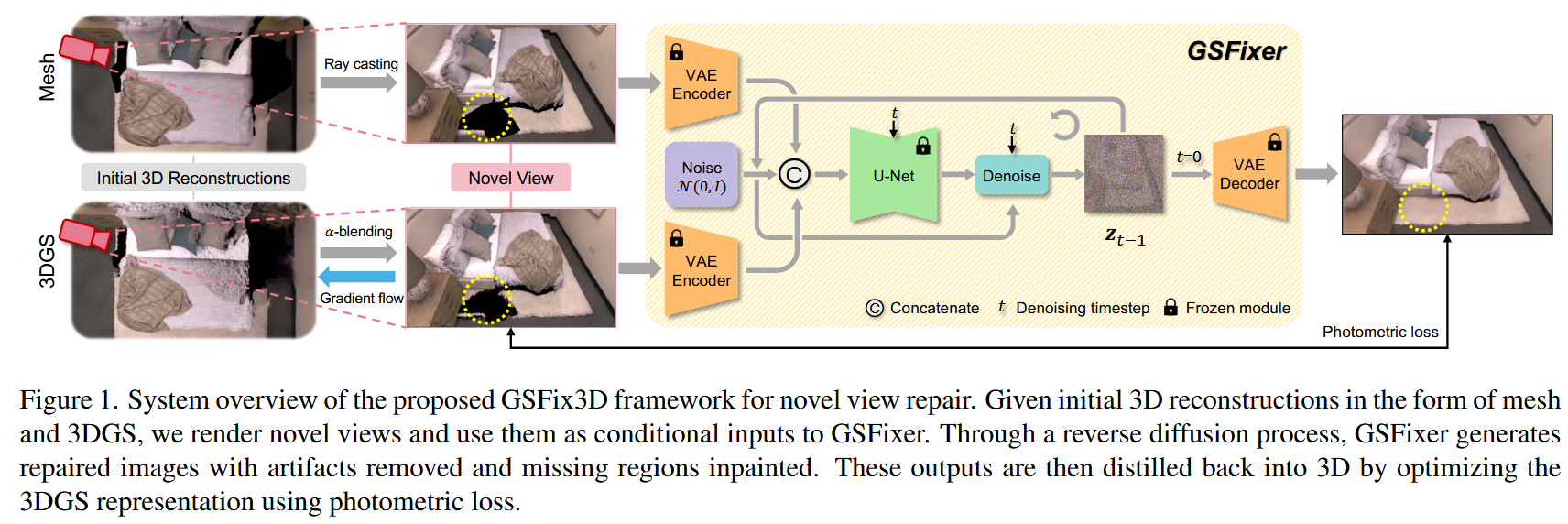
输入与条件生成:
首先,使用一个现有的3D重建系统(如论文中使用的GSFusion)同时重建出场景的3DGS表示和一个传统网格(Mesh)表示。
当需要修复一个新视角时,从该视角分别渲染出两张图像:一张来自3DGS(Igs),另一张来自Mesh(Imesh)。Igs包含丰富的纹理细节但可能有瑕疵,而Imesh的几何结构更完整但通常不够真实。这两张图像将作为修复模型的条件输入。
2D图像修复 (2D Image Repair via GSFixer):
将Igs和Imesh输入到核心模型GSFixer中。GSFixer是一个在特定场景数据上微调过的潜在扩散模型(Latent Diffusion Model)。
GSFixer执行一个反向扩散(去噪)过程,从一个随机高斯噪声开始,在Igs和Imesh的引导下,逐步生成一张高质量、无瑕疵的修复图像 Îfixed。这个过程不仅去除了浮动块等瑕疵,还能合理地补全空洞。
3D表示蒸馏 (3D Representation Distillation):
将GSFixer生成的修复图像Îfixed作为伪真值(pseudo ground truth)。
通过优化3DGS的参数(位置、旋转、缩放、颜色、不透明度等),最小化从当前3DGS渲染出的图像Igs与伪真值Îfixed之间的光度损失(photometric loss)。
这个优化过程将2D图像的修复信息“蒸馏”回3DGS表示中,从而真正地改善了3D场景模型。例如,原先是空洞的区域,通过这个过程会生成新的高斯基元来填充。
Method
微调协议 (Fine-Tuning Protocol)
这是训练GSFixer模型的关键。GSFixer并非从零开始训练,而是对一个预训练的Stable Diffusion v2模型进行定制化微调。
1. 网络架构
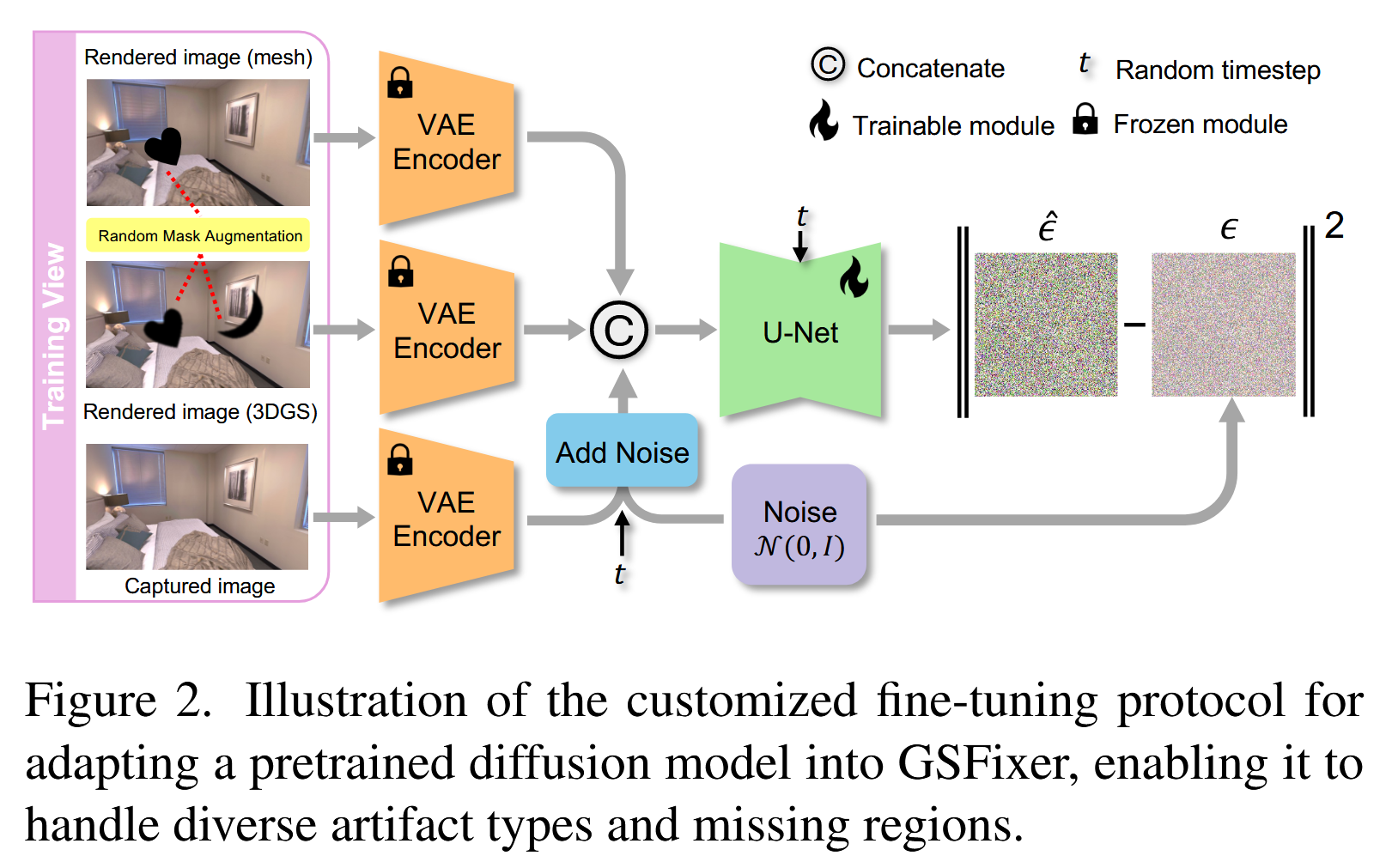
基础模型:采用Stable Diffusion v2,其核心是一个在 潜在空间(latent space) 中操作的U-Net去噪网络。为了提高效率,所有图像都先通过一个固定的变分自编码器(VAE)的编码器(Encoder)压缩到潜在空间。
双重条件输入策略 (Dual-Conditioning Strategy):这是该方法的一个核心创新点。传统的图像修复模型可能只使用一张带瑕疵的图像作为输入。而GSFixer同时使用3DGS渲染图 Igs 和 Mesh渲染图 Imesh 作为条件。
为什么需要双重条件? 这两种表示具有互补优势:
3DGS (Igs):提供了高度逼真的外观和纹理信息,但在观测不足处有瑕疵。
Mesh (Imesh):虽然渲染效果可能不那么真实,但提供了更稳定、更完整的几何结构先验,尤其是在3DGS出现空洞的区域。
通过结合两者,GSFixer可以同时利用高质量的外观线索和稳健的几何结构,从而做出更合理、更准确的修复。
网络修改:
首先,将条件图像Imesh、Igs和带噪的目标真值图Igt都通过冻结的VAE编码器转换为潜在表示zmesh、zgs和zt。
在U-Net的输入端,将这些潜在表示沿着通道维度拼接起来,形成一个新的输入张量concat(zmesh, zgs, zt)。
由于输入通道数增加了(例如,从4通道增加到12通道),U-Net的第一个卷积层需要修改。作者采用了一个巧妙的技巧:将原卷积核的权重复制三份,然后将每个权重值除以三。这样做的好处是,在保持权重初始分布和激活值尺度的同时,适配了新的输入维度,从而最大程度地保留了预训练模型的知识,避免了训练初期的不稳定性。
训练目标:训练的目标是让U-Net预测出添加到干净潜在表示中的噪声
ε。损失函数是标准的DDPM L2损失:L=Ez0,ϵ∼N(0,I),t[∣∣ϵ−ϵθ(zt,t,zmesh,zgs)∣∣2]其中zt是加噪后的潜变量,εθ是U-Net网络。
2. 数据增强 (Data Augmentation)
这是另一个至关重要的技术点,目的是教会模型如何进行内容补全。
问题:在微调时,使用的训练数据是场景中已捕获的视角,这些图像大部分是完整的,没有大的空洞。如果只用这些数据微调,模型将学不会如何填充在新视角中出现的大面积缺失区域。
解决方案:随机掩码增强 (Random Mask Augmentation) 作者引入了一种基于掩码的数据增强策略,在训练图像上人为制造缺失区域。
掩码来源:他们没有使用简单的矩形掩码,而是从一个真实的语义分割数据集中[32]获取了各种形状不规则的物体掩码。这样做的好处是,掩码的形状更自然、更多样,模拟的缺失区域更接近真实世界中的遮挡情况。
两种应用方式:
模拟遮挡:将同一个掩码同时应用到Imesh和Igs上。这模拟了新视角下由于前景物体遮挡而导致的共同缺失区域。
模拟3DGS特有瑕疵:额外使用一个独立的掩码,只应用在Igs上。这专门模拟了3DGS自身因优化失败或观测稀疏而产生的特有瑕疵(如浮动块或局部空洞),而这些瑕疵在更稳健的Mesh上可能不存在。
为了更好地模拟3DGS渲染中瑕疵的柔和边界,作者还对应用在Igs上的掩码进行了轻微的高斯模糊。
通过这种精心设计的数据增强,GSFixer在微调过程中就能学习到强大的、针对真实场景的内容补全能力。
GSFixer的推理过程
在对新视角进行推理(修复)时,过程如下:
将微调好的GSFixer(U-Net)参数冻结。
为新视角渲染出Imesh和Igs,并通过VAE编码器得到zmesh和zgs。
初始化一个与目标潜在表示维度相同的随机高斯噪声zT。
进行迭代去噪。在每一步
t,将zmesh、zgs和当前的噪声潜变量zt拼接后输入U-Net,预测出噪声εθ。使用 DDIM (Denoising Diffusion Implicit Models) 采样器来更新潜变量zt-1。DDIM相比DDPM速度更快,可以用很少的步数(如论文中的4步)生成高质量结果。其更新公式大致为:
z^0=αˉt1(zt−1−αˉtϵθ(zt,t))zt−1=αˉt−1z^0+1−αˉt−1ϵθ(zt,t)这里x̂0代表了在当前步骤
t对最终干净潜变量的预测。迭代结束后,得到最终的干净潜在表示z0。
将z0输入冻结的VAE解码器,得到最终修复好的图像Îfixed。
GSFix3D:将修复结果蒸馏回3D (Diffusion-Guided Novel View Repair)
这是将2D修复提升到3D场景修复的最后一步,也是整个GSFix3D框架的闭环。
目标:将Îfixed中的视觉改进迁移到3DGS表示中。
方法:利用3DGS的完全可微特性。
优化过程:
将Îfixed视为该新视角下的“理想渲染结果”或“伪真值”。
继续对初始的3DGS模型进行优化,但这次的损失函数是 当前3DGS的渲染图Igs与修复图Îfixed 之间的光度损失。
损失函数由L1损失和SSIM损失加权组成,以同时保证像素级和结构级的相似性。
Lpho=(1−λ)∣∣I^fixed−Igs∣∣1+λLSSIM(I^fixed,Igs)
自适应密度控制:在优化过程中,重新启用了原始3DGS论文中提出的高斯基元增殖和分裂机制。这一点非常关键,因为它允许在之前是空洞的区域创建新的高斯基元来填充内容,而不仅仅是拉伸或移动已有的高斯基元。
提升全局一致性:为了避免只修复单个视图而导致与其他视图不一致,作者采用了一种迭代策略。他们会选择一批稀疏的关键帧进行修复,然后将这些修复后的图像及其位姿加入到原始训练数据集中,再对整个增强后的数据集进行几轮优化。这确保了修复结果在全局范围内是协调一致的。
总结
GSFix3D通过一个设计精巧的流程,成功地将扩散模型的强大生成能力引入到3DGS的修复任务中。其核心技术亮点包括:
双重条件输入:同时利用Mesh的几何稳定性和3DGS的外观逼真性,为修复提供更全面的信息。
定制化微调与数据增强:通过场景特异性微调和创新的随机掩码增强,使模型能够学习到特定场景的先验知识和强大的内容补全能力。
2D到3D的蒸馏机制:利用3DGS的可微特性,将2D图像的修复结果有效地“写回”到3D表示中,实现了对3D场景本身的优化。
该方法仅需少量场景数据进行几小时的微调,就能显著提升3DGS在稀疏观测和极端视角下的渲染质量,展示了其在实际应用中的巨大潜力和效率。
Pixel-Perfect Depth with Semantics-Prompted Diffusion Transformers (NeurIPS 2025)
输入:
一张单独的RGB图像。
输出:
一张与输入图像尺寸对应的深度图 (Depth Map)。
解决的任务:
高质量的单目深度估计,其核心目标是解决现有方法普遍存在的 “飞行像素” (flying pixels) 问题。
该模型通过直接在 像素空间(pixel space) 进行扩散生成,避免了传统生成模型因使用VAE(变分自编码器)进行潜在空间压缩而导致的边缘伪影和细节丢失。
最终目标是生成能够转换为高质量、无伪影、边缘锐利的3D点云的深度图,以增强在3D重建、机器人等下游任务中的实用性。
Motivation
这篇论文的核心动机是解决单目深度估计(Monocular Depth Estimation, MDE)中的一个关键痛点问题:“飞行像素”(flying pixels)。
当我们从单个2D图像预测深度图,并将该深度图转换成3D点云时,物体边缘和细节处常常会出现一些不属于任何物体的、悬浮在空中的错误点,这些就是“飞行像素”。这个问题的存在极大地限制了深度估计在3D重建、机器人操作、新视角合成等下游任务中的实际应用价值。
论文指出,现有的主流方法都无法很好地解决这个问题,但原因各不相同:
判别式模型(Discriminative Models): 例如Depth Anything v2等模型,它们通常通过回归损失函数来直接预测每个像素的深度值。为了最小化损失,模型倾向于在深度不连续的物体边缘(例如前景和背景的交界处)输出一个平滑的、介于两者之间的平均深度值。这种“模糊”的边缘预测在转换成点云后,就形成了“飞行像素”。
生成式模型(Generative Models): 例如Marigold等基于扩散(Diffusion)的模型,它们在理论上能够更好地捕捉物体边缘的多模态深度分布,从而生成更清晰的边缘。然而,当前主流的生成式模型(如Stable Diffusion)为了降低计算复杂性,都在一个低维的 潜在空间(latent space) 中进行扩散操作。这意味着,它们需要一个变分自编码器(VAE)先将高清的深度图压缩成低维的潜在表示,在潜在空间生成后,再用VAE解码器恢复成高清深度图。问题在于,VAE的压缩和解压过程是有损的,这个过程本身就会引入伪影,导致边缘和细节信息的丢失,最终同样会产生“飞行像素”。
因此,本文作者的动机非常明确:设计一个既能利用生成式模型保留清晰边缘的优势,又能避免因VAE压缩而引入“飞行像素”的新型深度估计框架。 为了实现这一目标,他们提出了直接在 像素空间(pixel space) 进行扩散生成的方案,并设计了一系列创新的技术来克服在像素空间直接生成所带来的巨大挑战(如计算成本高、难以收敛等)。
Architecture
论文提出的模型名为Pixel-Perfect Depth,其整体架构如论文图3所示,可以概括为一个端到端的流程:
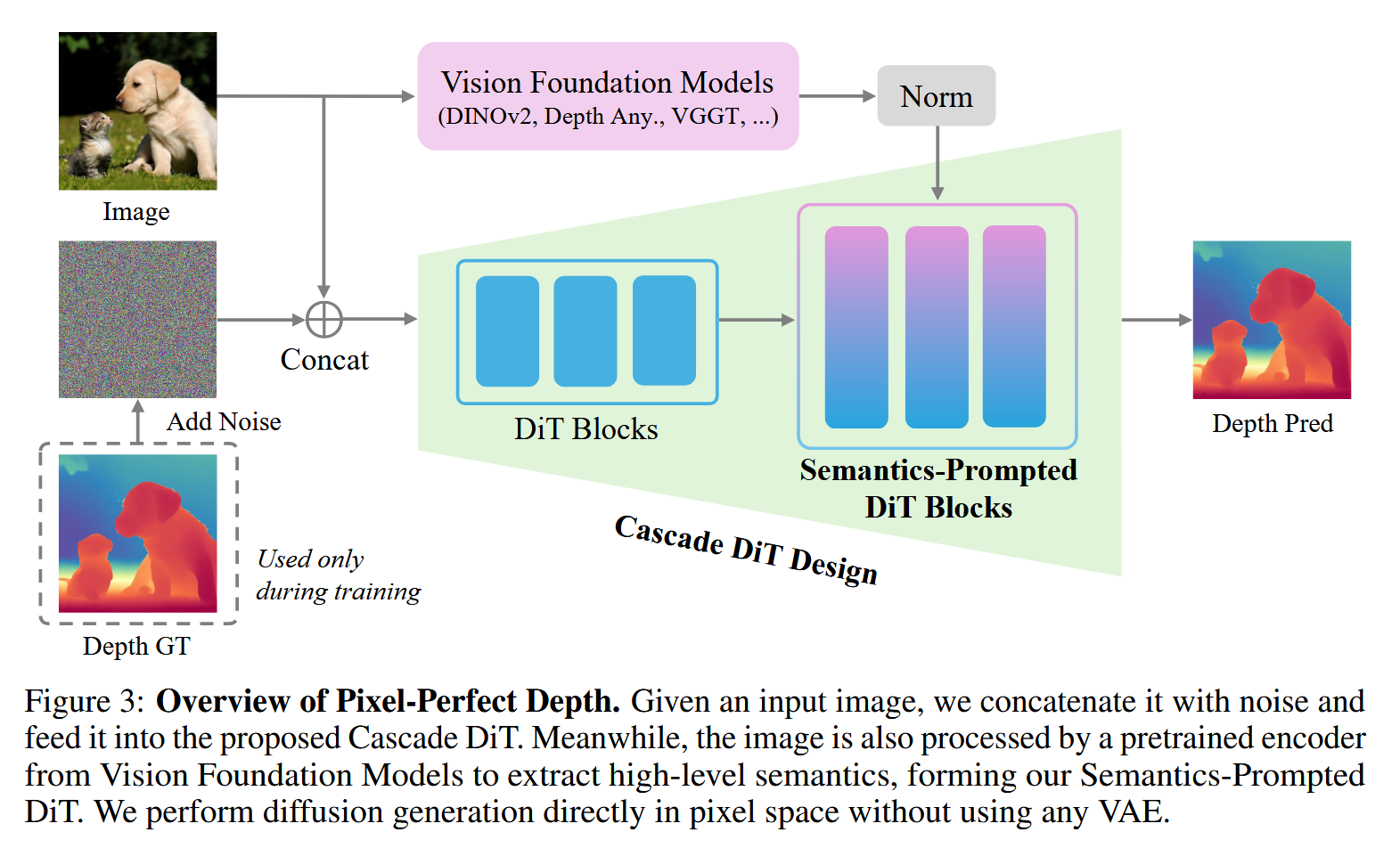
输入与噪声拼接:
模型的输入是一张普通的RGB图像。
在训练过程中,模型还将该图像对应的真实深度图作为目标。
在生成过程的初始阶段,模型会生成一个与输入图像尺寸相同的高斯噪声图。
这张RGB输入图像将与当前的噪声图(或在去噪过程中的中间结果)在通道维度上进行拼接。
语义信息提取 (核心创新之一):
与此同时,输入的RGB图像会被送入一个 预训练好的、冻结的视觉基础模型(Vision Foundation Models, VFMs) 中,例如DINOv2或Depth Anything的编码器。
这个VFM的作用是提取图像的高层语义特征。这些特征包含了对图像内容的全局理解,比如物体的轮廓、类别和场景布局等信息。
提取出的语义特征经过一个归一化处理,准备注入到主干网络中。
级联扩散Transformer主干网络 (Cascade DiT):
拼接了图像和噪声的张量被送入模型的主干网络——级联扩散Transformer(Cascade DiT Design)。这个网络完全由Transformer模块构成,不包含任何卷积层。
该网络的核心任务是学习如何一步步地从纯噪声中,根据输入图像的引导,预测出噪声中的“速度场”(velocity field),从而逐渐还原出清晰的深度图。
在去噪过程的中间阶段,从VFM中提取的语义特征会被注入到DiT模块中,这就是所谓的 “语义提示”(Semantics-Prompted)。这些语义信息像一个“全局导航仪”,引导DiT模块在生成细节的同时,不会丢失整体的结构和一致性。
输出:
经过多步迭代去噪后,主干网络最终输出一个预测的深度图。这个深度图由于是直接在像素空间生成的,避免了VAE带来的伪影,因此在转换成点云后几乎没有“飞行像素”。
总结来说,Pixel-Perfect Depth是一个以纯Transformer为骨干的像素空间扩散模型,它巧妙地利用视觉基础模型提取的语义信息来“提示”和“约束”扩散过程,并通过级联设计来优化效率和精度,最终生成高质量、无飞行像素的深度图。
Method
1. Pixel-Perfect Depth (核心目标)
这部分重申了模型的最终目标:生成一个转换成点云后没有飞行像素的“像素完美”深度图。它详细阐述了现有判别式模型因“均值预测偏见”和生成式模型因“VAE压缩”而导致飞行像素的根本原因。
为了从根本上解决这个问题,作者提出了直接在像素空间进行扩散的方案。这样做的好处是显而易见的:模型可以直接学习像素级别的深度分布,尤其是在物体边缘的不连续分布,从而避免了任何形式的压缩伪影。但挑战也同样巨大:在高分辨率的像素空间(例如1024x768)直接训练一个生成模型,计算量极大,并且模型很难同时兼顾全局结构的正确性和局部细节的精细度,非常难以优化。为了应对这些挑战,作者引入了下面两个关键设计:Semantics-Prompted DiT 和 Cascaded DiT Design。
2. 生成范式 (Generative Formulation)
模型选择了Flow Matching作为其生成框架的核心。Flow Matching是一种较新的生成模型训练范式,它通过学习一个将高斯噪声连续变换到真实数据分布的“速度场”来实现生成。
插值样本定义: 首先,定义一个在时间
t(从0到1)的插值样本 xt。它是由真实的干净深度图 x0 和一个标准高斯噪声 x1 线性插值得到的。xt=t⋅x1+(1−t)⋅x0当
t=0时,xt = x0(真实深度图);当t=1时,xt = x1(纯噪声)。速度场 (Velocity Field): 这个插值路径定义了一个从x0到x1的恒定速度场 vt。对xt关于
t求导即可得到:vt=dtdxt=x1−x0这个速度场描述了从真实数据“移动”到噪声的方向。
训练目标: 模型vθ(xt, t, c)的任务就是根据当前的带噪样本xt、时间步
t和作为条件的输入图像c,来预测这个真实的速度场 vt。训练的目标函数是让模型预测的速度和真实速度之间的均方误差(MSE)最小化。Lvelocity(θ)=Ex0,x1,t[∥vθ(xt,t,c)−vt∥2]推理过程: 在推理(生成深度图)时,过程则反过来。从一个纯噪声x1(即
t=1)开始,使用训练好的模型vθ来求解这个常微分方程(ODE),通过多步迭代,逐步将噪声往t=0的方向(即真实数据的方向)推进。每一步的更新公式如下:xti−1=xti+vθ(xti,ti,c)(ti−1−ti)其中时间步ti从1递减到0,最终得到的x0就是模型生成的深度图。
3. 语义提示扩散Transformer (Semantics-Prompted DiT, SP-DiT)
这是为了解决像素空间扩散难以优化问题的第一个核心技术。直接在像素空间应用标准的扩散Transformer (DiT) 效果很差(如论文图6所示),模型既无法把握全局结构,也生成不了精细的细节。作者分析其根本原因在于,模型在去噪的每一步都只能看到局部的像素信息,缺乏对整个图像内容的全局理解。
SP-DiT的设计思想就是:用一个强大的、预训练好的视觉基础模型(VFM)来为DiT提供全局语义指导。
提取语义表示: 给定输入图像
c,首先用一个VFM的编码器f(例如DINOv2的ViT-L/14编码器)来提取高层语义特征e。e=f(c)∈RT′×D′这里的
e是一系列Token,T'是Token数量,D'是每个Token的维度。这个e包含了对图像“讲了什么”的深刻理解。特征归一化 (关键步骤): 作者发现,从VFM中提取的语义特征
e的数值大小(magnitude)与DiT内部流动的Token的数值大小差异很大。如果直接将它们融合,会导致训练不稳定和性能下降。为此,他们引入了一个简单而有效的L2归一化步骤,对e在特征维度上进行归一化,得到ê。e^=∥e∥2e这一步使得注入的语义提示在数值上与DiT的内部状态更加匹配,确保了稳定的训练和有效的融合。
语义融合: 归一化后的语义表示
ê通过一个简单的多层感知机(MLP)层B和加法,被整合到DiT模型的内部Tokenz中。z′=hϕ(z+B(e^))经过融合后,后续的DiT模块就获得了语义提示,从而能在生成精细视觉细节的同时,有效保持全局语义的一致性。
4. 级联DiT设计 (Cascade DiT Design, Cas-DiT)
这是为了解决像素空间扩散计算成本高昂问题的第二个核心技术。它的设计基于一个观察:在DiT架构中,靠前的模块主要负责捕捉和生成全局的、低频的结构信息,而靠后的模块则专注于高频的、精细的细节信息。
基于这个洞察,Cas-DiT采用了一种从粗到细(coarse-to-fine)的级联策略来优化计算效率和精度。
设计细节: 假设整个模型有
N个DiT模块。粗糙阶段 (Coarse Stage): 前
N/2个DiT模块使用一个较大的Patch Size(例如16x16)。这意味着输入图像被分割成较少数量的、尺寸更大的Token。Token数量的减少直接导致了计算量的显著下降(Transformer的计算复杂度与Token数量的平方成正比)。这个阶段强迫模型优先学习和处理图像的全局结构和低频信息,这恰好与VFM提取的高层语义信息相匹配。精细阶段 (Fine Stage): 后
N/2个DiT模块(也就是SP-DiT模块)则使用一个较小的Patch Size(例如8x8)。模型在这里会增加Token的数量(通过一个MLP层和Reshape操作实现),从而获得更高的空间分辨率。这使得模型能够在此阶段专注于生成高频的、精细的空间细节。
这种级联设计不仅大幅提升了效率(论文提到推理时间减少了30%),还因为它模拟了人类视觉系统先看轮廓再看细节的层级感知过程,从而进一步提升了模型的精度。
5. 实现细节
这部分提供了复现模型所需的关键参数和设置。
模型架构:
总共
N=24个DiT模块。隐藏层维度
D=1024。前12个模块(粗糙阶段)的Patch Size为16,输入
H x W的图像后,Token数量为(H/16) x (W/16)。在第12个模块后,通过一个MLP层将隐藏维度扩展4倍,然后重塑(Reshape)得到
(H/8) x (W/8)的Token数量。后12个模块(精细阶段,即SP-DiT)处理这些数量更多的Token。
模型最后通过一个MLP和Reshape操作输出最终的
H x W深度图。特别强调:整个模型是纯Transformer架构,不依赖任何卷积层。
深度归一化: 为了让模型能够更好地处理室内和室外等不同尺度的场景,训练前对真值深度图
d进行了归一化:对数变换:
d' = log(d + ε),将绝对深度值转换到对数空间,以平衡不同尺度下的深度差异。分位数归一化:
d^=dmax′−dmin′d′−dmin′−0.5其中d'min和d'max分别是每张深度图中2%和98%位置的分位数,这使得归一化对异常值更加鲁棒。最终将值域缩放到[-0.5, 0.5]。
训练细节:
在8个NVIDIA GPU上训练。
优化器为AdamW,学习率为
1e-4。损失函数除了前面提到的MSE速度匹配损失外,还额外采用了来自Depth Anything v2的梯度匹配损失,以鼓励生成更清晰的边缘。
训练数据使用了高质量的合成数据集(如Hypersim),因为它们提供精确无误的3D几何信息,这对于训练一个旨在消除“飞行像素”的模型至关重要。
通过以上对动机、架构和技术细节的全面解析,我们可以看到,Pixel-Perfect Depth 这篇论文通过在像素空间进行扩散的根本性变革,并巧妙地设计了SP-DiT和Cas-DiT来解决随之而来的挑战,最终成功地实现了其核心目标——生成高质量、无飞行像素的深度图,为单目深度估计领域提供了一个极具价值的新思路。
ArtiFixer: Enhancing and Extending 3D Reconstruction with Auto-Regressive Diffusion Models (2026)

输入:
一个由稀疏图像构建的、包含严重伪影或未观测区域的 初始3D重建模型(如3DGS)。
由该初始模型在新视角下生成的 退化渲染图 以及对应的 细粒度不透明度图 (Opacity Maps)。
用户指定的 相机轨迹控制信号 (Camera poses/trajectory) 与少量的 干净参考视图 (Reference views)。
(可选的)文本提示词 (Text prompts)。
输出:
沿着输入相机轨迹直接渲染出的 超长序列、时空一致且无伪影的高清视频/图像流。
一个经过海量视频伪监督信号一次性“反向提炼”修复后,泛化与外推能力得到极大增强的 高质量底层3D模型(ArtiFixer 3D)。
解决的任务:
修复并大幅扩展极端/未观测视角下的3D重建缺陷。传统的3DGS等方法在观测不足或完全空白的区域会产生严重的画面破损、空洞和伪影。
以往引入扩散模型的修复方法需要“生成几张图 -> 更新一下3D模型”来回交替迭代,极其耗时且无法保证长序列一致性。ArtiFixer 通过创新的“不透明度感知混合”与“自回归因果蒸馏”技术,能够在单次前向推理中一口气生成数百帧符合3D物理规律且完美补全盲区的长视频,彻底打破了现有生成式3D修复中计算昂贵、扩展性差的瓶颈。
Motivation
在3D重建和新视角合成领域,基于单场景优化的方法(例如 3D Gaussian Splatting)虽然在观测充足的区域提供了当前SOTA级别的渲染质量,但在观测不足(under-observed)或完全未观测到的区域,这些方法的泛化和外推能力极差,往往会产生严重的伪影(Artifacts)或画面破损。
为了修复这些区域,近期的一些研究引入了生成式扩散模型(Generative Diffusion Priors)来进行纠正。然而,这些现有方法面临着两个致命的短板:
可扩展性不足与极高的计算开销(Scalability Issues): 现有的方法多依赖于图像扩散模型或双向视频生成模型。这类模型在单次前向传递中能够生成的视角数量极其有限。因此,为了在整个3D空间内保持多视角的一致性,它们不得不依赖于一种昂贵且耗时的渐进式迭代蒸馏过程(Progressive Iterative Distillation)——即在“生成少量新视角图像”和“更新底层3D重建表示”之间来回交替,导致训练时间开销极大。
生成质量与一致性差(Quality and Consistency Flaws): 由于直接使用现成生成器,先前的方法在处理极端退化的3D区域时,往往会产生与场景现有内容不一致的输出,或者在完全未观测的区域发生模式坍塌(Mode Collapse),导致生成失败或产生严重的幻觉现象。
ArtiFixer的破局思路:该工作的核心动机是探索显式3D重建与自回归视频生成的交叉点,通过紧密耦合这两种范式来实现双赢——既利用退化但具有结构的3D表示为视频生成提供强有力的条件约束,又利用自回归视频模型极高的生成效率和长序列一致性来大规模增强和扩展3D重建。
Architecture
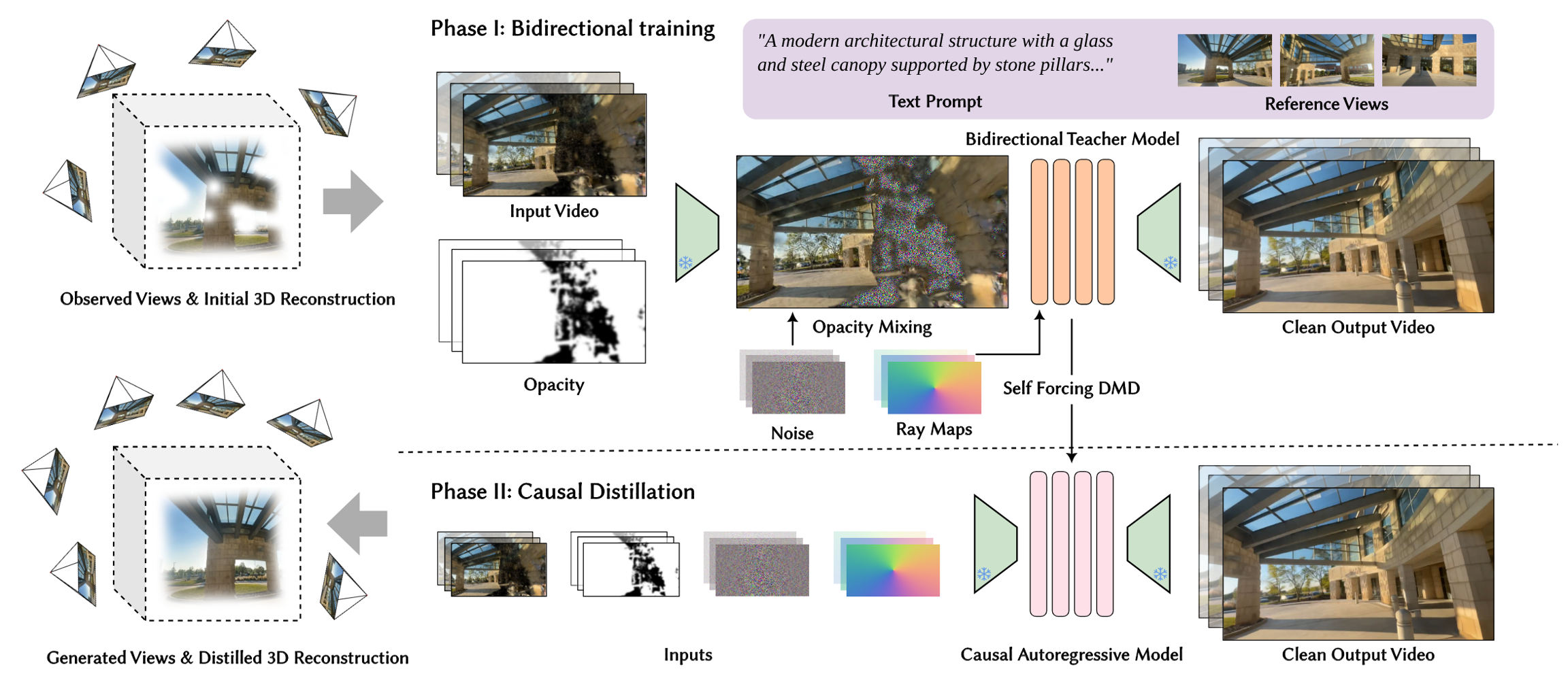
ArtiFixer 提出了一个极其高效的 两阶段(Two-stage) 架构。给定一个由稀疏图像集构建的初始退化3D重建模型,ArtiFixer 旨在以交互速率生成任意相机视角的无伪影长序列渲染(包括完全未知的区域)。
第一阶段:双向生成模型的训练与微调(Bidirectional Teacher Training) 模型首先将一个预训练的视频扩散模型适配为一个强大的“双向教师模型”。在此阶段,模型引入了创新的不透明度感知噪声混合策略(Opacity-aware noise mixing),将退化的3D渲染图、参考视图和不透明度信息有效融合,从而兼顾一致性与生成能力。
第二阶段:因果自回归模型的提取与蒸馏(Causal Auto-Regressive Distillation) 利用 Self Forcing 策略结合分布匹配蒸馏(DMD, Distribution Matching Distillation),将上述庞大的双向教师模型蒸馏成一个少步数(Few-step)、因果自回归的视频生成器。该模型能够在单次推理中生成数百帧长序列、时序一致的视角,可直接用于长视频渲染,或作为海量伪监督信号一次性回传给3D表示,彻底打破迭代瓶颈。
Method
1. 第一阶段:双向模型训练 (Sec 4.1. Bidirectional Training)
在这一步中,目标是教会预训练的视频扩散模型如何理解退化的3D输入,并在保持已知区域特征的同时,对未知区域进行合理的外推和补全。
多模态条件注入 (Multimodal Condition Injection): 为了实现高度可控的生成,网络接收大量维度的条件信号。具体包括:
退化的渲染图 (Degraded rendering):由初始粗糙3D模型渲染出的目标视角当前画面。
细粒度的不透明度信息 (Fine-grained opacity information):随3DGS渲染图一起生成的 Alpha 掩码/不透明度图。
相机控制信号 (Camera control):当前目标视角以及连续生成的相机位姿参数。
干净的参考视图 (Clean reference views):用户提供的无损视角,作为全局风格和内容的强参考。
可选的文本提示 (Optional text prompt):允许通过语言输入进行语义层面的宏观引导。 通过多维度的注入,论文证明了即便初始3D重建高度退化,也能够为生成网络提供足够强大的结构性引导信号(Conditioning signals)来简化后续生成过程。
核心创新:不透明度感知噪声混合策略 (Opacity-aware Noise Mixing / Opacity Mixing): 这是本文解决“模式坍塌”和“语义幻觉”的核心法宝。在过去的方法中,通常是简单粗暴地将“退化渲染图”在通道维度上直接与“高斯噪声”进行拼接(Channel Concatenation)输入给去噪网络。这种做法会导致扩散模型在面对大面积“空白/未观测”区域时无所适从,进而产生严重的语义不一致(例如在原本应该空旷的场景里错误地幻觉出一张桌子)。
ArtiFixer 独具匠心地利用底层3D表示(如3DGS)渲染出的不透明度图 (Opacity Maps),作为空间权重来进行混合指导。 具体而言,设输入RGB图像在隐空间编码后的特征为 zRGB,渲染出的不透明度映射为 α(取值范围0到1),随机高斯噪声为 ε。其混合初始隐变量 zmix 遵循如下核心逻辑(概念公式):
zmix=α⊙zRGB+(1−α)⊙ε深层机制解析:
高不透明度区域(α 趋近于 1):这代表相机曾经观测到该区域,存在扎实的3D实体结构。此时 zmix 几乎等同于 zRGB,网络主要接收真实的特征。这强制生成结果与现有的观测保持严格的一致性,避免破坏已建好的高质量区域。
低不透明度区域(α 趋近于 0):这代表未观测到的死角、破洞或严重伪影区域。此时特征被彻底掩盖,zmix 被大量注入了纯高斯噪声 ε。这种机制有效防止了模式坍塌(Modal Collapse),为扩散模型保留了最大化的生成能力(Generative Capacity),使其能够纯粹利用视频扩散先验,在这些空缺区域进行极其自然、符合物理逻辑的生成与外推。
2. 第二阶段:因果蒸馏与自回归生成 (Sec 4.2. Causal Distillation)
第一阶段的双向模型虽然渲染质量高,但由于是全局联合生成(Joint synthesis),显存占用巨大,单次能够生成的帧数极其有限,无法满足大尺度游历。因此,第二阶段负责将其蒸馏为极具扩展性的自回归模型。
自回归与块因果注意力 (Block-Causal Attention): 将模型转换为按顺序(Sequentially)生成帧的方式。以往自回归视频生成由于当前帧依赖先前所有帧的输出,会导致误差随时间成倍累加(Error Accumulation)。ArtiFixer 巧妙借用了强大的底层3D先验来对齐全局空间坐标,极大缓解了时间漂移问题。
Self Forcing 风格的训练与 KV 缓存 (KV Caching): 采用类似于 Huang 等人(2025)提出的 Self Forcing 策略。
视频块顺序生成:模型不再一次性预测整个视频,而是划分为多个视频块(Video chunks)进行推理。
键值缓存 (KV Caching):在生成当前块时,强制模型将其作为条件(Conditioning),依赖于先前已生成视频块的 KV 缓存。这种机制保留了极长上下文的时间一致性,同时极大节省了显存,使得单次通过能够产出数百帧(Hundreds of frames in a single pass)。
一致性 Dropout 策略: 为了防止自回归模型“偷懒”(即过度依赖先前的生成帧而忽略当前指定的相机控制信号与参考视图),该阶段继续施加了严苛的 Dropout 机制(与 Sec 4.1 相同)。这确保了当模型移动到完全未观测区域、必须从纯噪声(Pure noise)进行生成时,它对相机位姿参数的精确控制力依然不会出现任何退化。
DMD 分布匹配蒸馏 (Distribution Matching Distillation): 为达到交互级实时帧率,生成器去噪步数必须被压缩。
采用 Yin 等人(2024)的 DMD 技术,将冗长的扩散步骤蒸馏成极少的步数。
论文实验中将生成步数设定为 N = 4 步。
值得一提的是,得益于3D条件的强大指引,论文指出在非完全盲区(存在部分先验观测的区域),推理步数甚至可以缩减至少于 4 步,且肉眼几乎难以察觉到画质损耗。
模型变体与应用范式
在论文的实验评估(Sec 5)中,作者证明了其模型解耦能力极强,演化出了三种高效的使用变体:
ArtiFixer (Direct Render): 直接发挥自回归生成器的强大能力,基于输入的相机轨迹实时渲染任意长度、无伪影的新视角视频,全面替代传统3D渲染器。
ArtiFixer 3D (Pseudo-supervision Distillation): 利用自回归模型一口气生成海量的高质量长视频视角,将这些帧作为伪监督(Pseudo-supervision),一次性批量回传提炼(Distill back)至底层3D表示中优化参数。因为省去了“生成-更新-再生成”的交替循环,这使得修复底层 3D 模型的训练时间断崖式下降,效率极高。
ArtiFixer 3D+ (Post-processing Enhancement): 将自回归模型当作一层增强滤镜,叠加在已经被 ArtiFixer 3D 修复过的3D表示之上作为后处理(Post-processing step)。这能进一步找回高频细节,使最终画面在保持最高全局时空一致性的前提下,实现比纯3D渲染更锐利(Crisper)的画质。
训练与硬件实现细节
为了体现方法的专业级扩展性,作者提供了极其详尽的系统工程配置:
硬件规模与框架:算法基于 PyTorch 搭建,使用了规模庞大的 128 张 NVIDIA H100 GPU 并行训练。由于使用了每张卡 Batch Size 为 1 的设置,总有效全局 Batch Size 高达 128。
加速计算层:全面集成了最新的 FlashAttention-3,最大程度优化显存带宽,使得超长视频序列的注意力矩阵计算成为可能。
优化器与超参配置:
第一阶段 (双向微调):使用 AdamW 优化器训练 15,000 次迭代,学习率固定为 1 × 10-5。
第二阶段 (因果蒸馏):
首先以 1 × 10-5 的学习率初始化因果自回归模型并训练 5,000 次迭代。
紧接着展开 2,000 次自回归 Rollout 与 DMD 结合的蒸馏训练。这一步采用双学习率解耦控制:生成网络(Generator)的学习率设定为 2 × 10-6,而用于判断分布差异的 Fake Score Function 学习率设定为 4 × 10-7。
总结而言,ArtiFixer 实现了领域内的一次重要范式融合。通过“不透明度感知混合”和“长序列自回归蒸馏”,它成功地把显式 3D 重建强大的空间一致性与视频生成模型天马行空的外推修复能力完美捏合,并在各个常用基准测试上将 SOTA 指标一举拉升了 1~3 dB PSNR。
最后更新于