diffusion的x-pred与v-pred
@TOC
Back to Basics: Let Denoising Generative Models Denoise (2025)
输入:
一个 高维噪声图像序列:直接将原始像素图像切分为较大的补丁(Patches,例如 16x16 或 32x32 像素),并混合了噪声。
时间步信息 (Time step) t。
类别条件 (Class condition):通过 In-context 方式拼接的类别 Token。
核心特点:直接输入 Raw Pixels,不使用 VAE、Tokenizer 或任何降维潜空间。
输出:
网络直接预测的 干净图像补丁 (Clean Image Patches) x。
最终通过采样生成的 高分辨率、高质量 RGB 图像。
解决的任务:
克服高维空间下的生成模型崩溃问题。标准的 Vision Transformer (ViT) 在处理高维像素输入时,如果预测噪声(ϵ)或速度(v)通常会失败(维度灾难)。
建立极简的像素级扩散范式 (JiT)。通过强制网络预测“干净数据”而非“噪声”,利用数据的低维流形特性,使得最普通的 Transformer 能够不依赖任何预训练组件(如 VAE/CLIP)直接在像素空间进行高效、高质量的图像生成。
Motivation
现状与问题
目前的扩散模型(Diffusion Models)和流匹配模型(Flow Matching)虽然起源于“去噪”的概念,但在实际发展中发生了偏离:
预测目标偏离:早期的核心理念是“去噪”(预测干净图像),但后来 DDPM 发现预测噪声(ϵ-prediction)效果更好,随后的流模型倾向于预测速度(v-prediction)。
维度灾难:为了处理高维像素空间,现有方法通常依赖 潜在空间(Latent Space)(如 Stable Diffusion 使用的 VAE)来降低维度,或者使用复杂的卷积网络(U-Net)。如果直接在像素上使用简单的 Transformer(ViT),当图像补丁(Patch)尺寸较大时(导致输入维度极高),模型通常会崩溃。

流形假设

作者引入了机器学习中的经典“流形假设”来解释为什么预测噪声是困难的,而预测数据是容易的:
干净数据(Clean Data):位于高维像素空间中的一个 低维流形(Low-dimensional Manifold) 上。
噪声(Noise):固有地分布在整个 高维空间 中。
结论:如果让神经网络预测噪声(ϵ),网络需要极高的容量来模拟整个高维空间的分布;而如果让网络预测干净图像(x),网络只需要学会将输入投影回那个低维流形上。对于容量有限或输入维度极高的网络(如处理原始像素Patch的ViT),预测干净数据(x-prediction)大大降低了学习难度。
模型架构:Just Image Transformers (JiT)
论文提出了一种极简的架构,称为 JiT。这实际上就是最普通的 Vision Transformer,不做任何针对扩散模型的复杂修改。

输入处理:
不使用 VAE 或 Tokenizer,直接操作原始像素。
将图像 H x W x C 切分为 p x p 的补丁(Patches)。
使用较大的 Patch Size(如 16 或 32)。这意味着每个 Token 的维度非常高(例如 32 x 32 x 3 的 patch 维度高达 3072)。
主干网络:
标准的 ViT 结构(Transformer Blocks)。
包含线性嵌入层(Linear Embedding)和线性预测层(Linear Prediction)。
去繁就简:
没有下采样/上采样(No U-Net design)。
没有预训练的潜空间(No Latent VAE)。
没有感知损失(Perceptual Loss)或对抗损失(Adversarial Loss)。
没有分层设计。
Methodology
这是论文最核心的技术部分,作者详细阐述了预测空间、损失空间以及它们之间的转换关系。
扩散与流的基础公式
考虑干净数据 x 和噪声 ϵ。在训练过程中,时刻 t ∈ [0, 1] 的噪声样本 z_t 定义为线性插值:
对应的流速度(Velocity)v 定义为 z_t 对时间的导数:
这三个变量(x, ϵ, v)通过线性关系紧密相连。只要知道 z_t 和 t,预测出其中任意一个量,都可以推导出另外两个。
预测空间 vs. 损失空间 (关键创新)
作者指出,网络直接预测的内容(Network Output) 和 计算损失的函数(Loss Function) 不必在同一个空间。
通常的流匹配损失函数是基于 v 的:
但在 JiT 中,作者强制让神经网络的直接输出 netθ(zt,t) 代表干净图像 x。为了计算上述的 v-loss,需要进行数学变换。
变换公式: 如果网络输出的是 x(记为 x_θ),那么根据公式可以推导出隐含的 v(记为 v_θ):
训练算法流程:
采样时间 t 和噪声 ϵ。
构造噪声输入 zt=t⋅x+(1−t)⋅ϵ
计算真实目标 v=x−ϵ
网络前向传播:输入 z_t,输出预测值 xpred=netθ(zt)
空间转换:将预测的 x 转换为 v 空间:vpred=1−txpred−zt
计算损失:计算 vpred 和真实 v 之间的 MSE 损失。
通过这种方式,虽然优化的是流匹配损失(保证了生成质量和概率解释性),但网络本身承担的任务是去噪(预测 x),这符合流形假设,降低了高维空间的建模难度。
为什么 ϵ-prediction 和 v-prediction 会失败?
在 Patch Size 很大(如 32x32)的情况下,每个 Token 的维度高达几千维。
ϵ / v:噪声是高频且充满整个高维空间的。简单的线性层(Linear Projection)很难保留如此丰富且高维的噪声信息,导致信息瓶颈。
x:真实图像位于低维流形。网络只需要学会“丢弃”与流形无关的噪声分量,这是一种降维操作,对于神经网络来说要容易得多。
关键技术细节
为了让这个简单的框架达到 State-of-the-Art (SOTA) 的效果,论文中还包含了一些重要的技术调整:
瓶颈嵌入 (Bottleneck Embedding)
在将图像 Patch 映射到 Transformer 的隐藏层维度(Hidden Dim)时,通常是一个简单的线性层。 作者发现,引入一个 低秩(Low-rank)瓶颈层 居然有益。
具体做法:将 Input → Hidden 的映射分解为 Input → d' → Hidden,其中 d' 远小于输入维度。
原理:这进一步强制网络利用数据的低维流形特性,过滤掉高频噪声。
现代 Transformer 组件
为了提升性能,JiT 采用了类似大语言模型(LLM)的现代设计,而非原始 ViT 的设计:
SwiGLU 激活函数。
RMSNorm 归一化。
RoPE (Rotary Positional Embeddings) 旋转位置编码。
QK-Norm:对 Query 和 Key 进行归一化,稳定训练。
上下文条件
在类条件生成(Class Conditioning)中,标准的 DiT 使用 adaLN(自适应层归一化)注入类别信息。 JiT 探索了一种更类似 GPT 的方式:
将类别标签(Class Label)作为一个或多个 Token,直接拼接到图像 Patch 序列的前面。
实验发现,拼接多个类别 Token(例如 32 个)能显著提升效果。
噪声调度与采样
训练噪声分布:使用 Logit-Normal 分布来采样时间 t,并倾向于在高噪声区域(t 较小)进行更多训练。
无分类器引导 (CFG):使用了标准的 CFG,这对于 ImageNet 生成至关重要。
总结
这篇文章的 Method 部分最核心的贡献在于厘清了 Prediction Space(网络输出什么) 和 Loss Space(优化什么) 的关系。
结论:在处理高维原始数据(Raw Data)时,不要让网络去预测复杂的噪声(ϵ)或混合量(v),而应该让网络回归本源,直接预测干净数据(x)。
意义:这证明了不需要复杂的潜空间(VAE)或复杂的 U-Net,仅凭最基础的 Transformer 和正确的预测目标(x-prediction),就可以实现高质量的图像生成。这为未来在视频、3D 或科学数据等难以构建 Tokenizer 的领域应用扩散模型指明了方向。
jit流程:diffusion如何与vit结合
要理解这两者如何结合,我们需要理清它们各自的角色:
Diffusion(扩散模型)是“游戏规则”:它定义了如何通过加噪(前向)和去噪(反向)来生成数据。它不是一个特定的网络结构,而是一个数学框架。在去噪的那一步,它需要一个函数(或者说一个大脑)来执行“看一眼噪声图,猜出原图是什么”这个任务。
ViT(Vision Transformer)是“大脑”:在传统的 Diffusion(如 DDPM 或 Stable Diffusion 的 U-Net 部分)中,这个“大脑”通常是卷积神经网络(CNN/U-Net)。但这篇论文说:我们把 U-Net 换掉,换成 ViT 来做这个“去噪大脑”。
场景设定
假设我们要生成一张 256 x 256 大小的彩色图片(RGB 3通道)。 设定 Patch Size(补丁大小)为 16。
第一阶段:准备输入 (Diffusion 侧)
1. 采样与加噪
输入:一张完全的高斯噪声图(或者训练时的加噪图 zt)。
维度:
[256, 256, 3](高 x 宽 x 通道)。任务:ViT 需要根据这张噪声图和当前的时间步 t,预测出干净的图像 x。
第二阶段:进入 ViT 内部 (ViT 侧)
这是核心部分,ViT 如何“吃掉”这张噪声图:
2. 切块 (Patchify) ViT 不像 CNN 那样滑动窗口,而是像切蛋糕一样把图切碎。
图像大小 256 x 256,补丁大小 32 x 32。
行方向切 256/32 = 8 块,列方向切 8 块。
总补丁数(Sequence Length)N = 8 x 8 = 64 个。
每个补丁的像素数据量:32 x 32 x 3 = 3072 个数值。
数据变形:从
[256, 256, 3]变为一个序列[64, 3072]。这里
64是序列长度 (Token数量),3072是每个 Token 的特征维度。
3. 线性嵌入 (Linear Projection) ViT 把原始像素映射到内部的隐藏层维度(Hidden Dimension),假设模型宽度为 D=768。
操作:用一个全连接层处理每个 Patch。
数据维度:从
[64, 3072]变为[64, 768]。警报:3072 > 768,信息发生坍缩!(如果是标准 v-pred 或者 ϵ-pred,到这就已经注定失败了)。
4. 注入条件 (Conditioning) Diffusion 需要告诉网络“现在是第几步(时间 t)”以及“你要生成什么类别(比如猫)”。
这篇论文的做法非常像 GPT:把 t 和 类别 变成额外的 Token,拼接到序列前面。
假设有 1 个时间 Token 和 32 个类别 Token。
数据维度:从
[64, 768]变为[97, 768](64个图块 + 33个条件Token)。
5. Transformer 编码器处理 (Self-Attention) 这是 ViT 的“思考”过程。通过自注意力机制(Self-Attention),这些 Token 互相交互。
比如:第5个补丁(左上角的一块噪声)会“看”第100个补丁(中间的一块),通过全局上下文判断:“虽然我现在看起来像噪点,但根据周围的信息,我这里应该是蓝天的一部分”。
在这个过程中,数据维度保持不变:一直是
[97, 768]。
6. 预测输出 (Prediction) 经过多层 Transformer Block 后,我们拿掉那 33 个条件 Token,只保留 64 个图像 Token。
操作:通过一个线性层(Linear Head),把隐藏维度映射回像素维度。
数据维度:从
[64, 768]变回[64, 3072]。物理意义:此时,每一个 Token(768维向量)代表的就是网络预测的、该位置的干净像素补丁(32 x 32 x 3)。
第三阶段:还原与计算 (Diffusion 侧)
7. 拼图还原 (Unpatchify) 把预测出来的序列重新拼回图片形状。
数据维度:从
[64, 3072]变回[256, 256, 3]。这就是模型预测的“干净图像” x_pred。
8. 计算 Loss 或 采样
训练时:拿这个 x_pred 和真实的干净原图 x_gt 计算损失(Loss),然后反向传播更新 ViT 的权重。
推理时:根据 Diffusion 的公式(ODE求解器),利用这个预测的 x_pred 算出微小的去噪步长,得到 z_{t-1}(少了一点点噪声的图),然后重复上述步骤直到变成纯净图。
总结:ViT 在这里的本质
之所以觉得违和,可能是因为习惯了 ViT 用于分类(最后输出一个类别向量)。
但在 Diffusion 中,ViT 变成了一个“图片到图片”的映射网络(Image-to-Image Regression):
输入:一堆代表噪声图像碎片的向量。
处理:利用 Transformer 强大的全局注意力机制,分析这些碎片之间的关系。
输出:一堆代表修复后图像碎片的向量。
简单一句话: Diffusion 负责提供问题(噪声图)和检查答案(计算Loss),而 ViT 负责做题(看着噪声图的切片,通过计算注意力,把每一个切片还原成干净的像素切片)。
Diffusion Transformers with Representation Autoencoders (RAE) (2025)
输入:
随机高斯噪声 (Random Gaussian Noise):作为生成过程的初始状态。
条件控制信号 (Conditioning Signal):通常是类别标签(如 ImageNet 的类别),用于指导生成特定内容的图像。
输出:
高质量的合成图像 (Generated Images):逼真、细节丰富且符合输入语义的图片(如 256x256 或 512x512 分辨率)。
解决的任务:
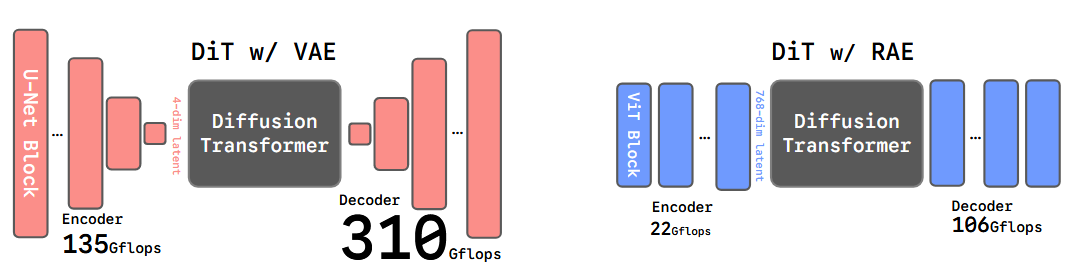
基于强语义潜在空间的图像生成。传统的潜在扩散模型(如 Stable Diffusion)依赖 VAE 进行压缩,导致潜在空间语义信息弱且训练收敛慢。
本文通过Representation Autoencoder (RAE) 取代 VAE,利用冻结的强力视觉编码器(如 DINOv2)构建高维、语义丰富的潜在空间,并利用改进的 DiT-DH 架构克服了在高维空间训练扩散模型的困难,实现了更快的训练收敛速度和SOTA 级别的生成质量。
Motivation
在当前的生成式建模领域,标准范式是“潜在生成建模”(Latent Generative Modeling)。例如 Stable Diffusion 或 DiT,它们通常包含两个阶段:
压缩阶段:使用一个预训练的自动编码器(通常是 VAE,如 SD-VAE),将像素空间的图像压缩到一个低维的潜在空间(Latent Space)。
生成阶段:在这个潜在空间中训练扩散模型。
作者指出了现有范式(基于 VAE)的三个主要痛点:
过时的骨干网络:SD-VAE 仍然依赖于旧式的卷积神经网络(CNN),这在架构简洁性和扩展性上不如现在的 Transformer。
信息受限的潜在空间:VAE 为了生成,通常将图像压缩到非常小的空间(例如 32 x 32 x 4),这限制了信息的容量,丢失了大量细节。
弱语义表示:VAE 的训练目标纯粹是基于像素重建的(Reconstruction-based)。这意味着它的潜在空间只关注“长得像不像”,而不包含“是什么”的高级语义信息。这最终限制了生成模型的上限。
作者的洞察: 现在的视觉表示学习(Representation Learning)已经非常发达,出现了 DINOv2、SigLIP、MAE 等强大的自监督模型。这些模型生成的特征具有极强的语义性和结构性。
传统偏见:人们通常认为这些特征是“高维”且“语义导向”的,不适合用来做像素级的图像重建,也不适合用来跑扩散模型(因为维度太高)。
论文反驳:作者证明了使用冻结的表示编码器(Representation Encoder)配合一个训练良好的解码器,可以实现比 VAE 更好的重建质量,同时保留丰富的语义。
核心目标: 用 Representation Autoencoder (RAE) 取代 VAE,并让 DiT 能够在这个高维、强语义的潜空间中高效训练。
模型架构:Representation Autoencoder
RAE 并不是一个端到端训练的新模型,而是一种新的组合策略。
编码器
选择:使用现成的、冻结参数的预训练视觉编码器。论文主要测试了 DINOv2 (自监督)、SigLIP (语言监督) 和 MAE (掩码自编码器)。
操作:
输入图像被切分成 Patch(例如 14 x 14 或 16 x 16)。
编码器输出一系列特征 Token。
关键点:RAE 不进行下采样压缩。如果输入是 256 x 256,Patch 大小是 16,那么会产生 16 x 16 = 256 个 Token。
维度:这些 Token 的通道维度(Channel Dimension, d)通常很高(例如 DINOv2-Base 是 768,Large 是 1024),远高于 VAE 的 4 通道。
解码器
架构:一个轻量级的 Vision Transformer (ViT) 解码器。
功能:接收编码器输出的特征 Token,将其映射回像素空间。
训练目标:仅训练解码器,编码器保持冻结。使用 L1 Loss、LPIPS(感知损失)和 GAN Loss(对抗损失)的组合。
RAE 的优势:
重建质量(rFID)优于 SD-VAE。
线性探测(Linear Probing)准确率远高于 VAE(84.5% vs 8.0%),说明潜在空间包含了丰富的语义信息。
Method: Taming DiT for RAE
这是论文最核心的部分。当作者尝试直接在这个高维的 RAE 潜空间上训练标准的 DiT 时,发现模型完全不收敛或效果极差。
为了解决这个问题,作者进行了深入的理论分析并提出了三个关键的技术改进和一个架构改进(DiT-DH)。
技术挑战 1:高维空间的模型容量不足
现象: RAE 的潜在空间维度(Token Dimension, n)通常是 768 或 1024。而标准的 DiT 设计通常是针对 VAE 的低维潜空间(channel=4)设计的。作者发现,如果 DiT 的隐藏层宽度(Hidden Width, d)小于 RAE 的 Token 维度 n,模型无法拟合,甚至无法过拟合单个样本。
理论解释 (Theorem 1): 作者提出了一个理论推导。扩散模型在训练过程中会向数据中添加高斯噪声。
这实际上将数据的流形(Manifold)“扩散”到了整个全秩空间。为了能够逼近这个全维度的速度场(Velocity Field),神经网络的宽度必须足够大。 结论:DiT 的宽度 d 必须 大于等于 RAE 的 Token 维度 n。
如果 DiT 太窄,它将出现信息瓶颈,无法有效地去噪。
解决方案: 强制 DiT 的宽度至少要匹配编码器的输出维度。例如,对于 DINOv2-Base (dim=768),DiT 的宽度至少要是 768。
技术挑战 2:噪声调度策略失效
现象: 原本针对像素或 VAE 潜空间设计的噪声调度(Noise Schedule)在 RAE 上表现不佳。
原因: 先前的研究表明,对于维度为 C x H x W 的输入,增加空间分辨率 (H x W) 会降低同一噪声水平下的信息破坏程度。 然而,RAE 的“分辨率”体现在通道数上(高维特征)。随着通道数 C 的增加,每个 Token 包含的信息量变大,同样的噪声对信息的破坏力变小了。
解决方案:维度依赖的噪声偏移 (Dimension-Dependent Noise Schedule Shift) 作者采用了类似 Flow Matching 中的 Shift 策略,根据有效数据维度(Effective Data Dimension)调整时间步 t:
其中缩放因子 α 定义为:
这里 n 是基准维度(例如 4096),m 是 RAE 的有效维度(Tokens数量 x 通道维度)。这种 Shift 策略确保了在高维空间中,噪声分布能够更合理地覆盖信号破坏的范围,从而显著提升 FID(从 23.08 提升至 4.81)。
技术挑战 3:解码器对噪声的鲁棒性
现象:
VAE:是变分模型,编码输出的是分布,解码器训练时采样自 z ~ N(μ, σ)。因此 VAE 解码器天然见过“噪声”。
RAE:编码器是确定性的(Deterministic),解码器只见过干净的特征 z = E(x)。
问题:在推理时,扩散模型生成的潜在变量 $\hat{z}$ 肯定不完美,带有一些噪声或误差。RAE 解码器对这些微小的分布外(OOD)扰动非常敏感,导致生成图像质量下降。
解决方案:噪声增强解码 (Noise-Augmented Decoding) 在训练 RAE 的解码器时,人为地向编码器的输出 z 中注入高斯噪声,迫使解码器学习去噪或对噪声鲁棒:
解码器的训练输入变为 z + n。
为了进一步提高鲁棒性,噪声的标准差 σ 本身也是随机采样的。这使得解码器不仅能重建完美特征,也能处理扩散模型生成的“略带瑕疵”的特征。
架构创新:DiT-DH (Diffusion Head)
动机: 根据挑战 1 的结论,DiT 的宽度必须很宽(例如 > 1024)。但标准的 Transformer 计算复杂度与宽度的平方成正比(O(d^2))。如果为了匹配高维特征而简单地把整个 DiT 变宽,计算成本(FLOPs)会爆炸。
解决方案:DiT-DH 作者借鉴了 DDT (Decoupled Diffusion Transformer) 的思想,提出了一种非对称的架构:
DiT Backbone:可以使用标准的、较窄的 DiT 结构(负责处理上下文关系,深度较深)。
DDT Head (Diffusion Head):在 Backbone 之后,附加一个 极宽(Wide)但极浅(Shallow) 的 Transformer 模块。
具体设计:
Backbone 提取特征 zt。
Head 负责将特征映射回高维空间并预测速度场 vt。
公式:
zt=Backbone(xt∣t,y)vt=Head(xt∣zt,t)优势:Head 满足了“宽度 >= Token 维度”的理论要求,但因为它很浅(例如只有 2 层),所以并没有引入太多的计算量。
这使得 DiT-DH 能够以极高的效率处理高维 RAE 潜空间,其收敛速度和最终效果都远超传统的 DiT。
总结
RAE + DiT-DH 的组合流程:
输入:图片。
编码:通过冻结的 DINOv2 得到高维 Token(不压缩数量,只映射维度)。
扩散训练:
应用 DiT-DH:Backbone 处理序列,宽的 Head 处理高维特征匹配。
应用 Schedule Shift:调整噪声调度以适应高维特性。
采样/生成:DiT-DH 生成潜在 Token。
解码:通过 噪声增强训练过的解码器 将 Token 还原为图像。
结果:
在 ImageNet 256 x 256 上,无引导 FID 达到 1.51,有引导达到 1.13。
训练收敛速度比基于 VAE 的方法(如 SiT, REPA)快得多(达到 16x - 47x 的加速)。
证明了“高维、语义丰富”的特征不仅可以用于生成,而且比“低维、压缩”的特征更好。
rae流程
第零阶段:预处理 (Pre-stage) —— 仅仅在训练准备时做
这一步是 RAE 独有的。我们需要先用一个“超级老师”把图片翻译成特征。
老师模型:冻结的 DINOv2-Base。
动作:把真实图片扔进 DINOv2。
结果:DINOv2 输出 256 个特征 Token(对应 16 x 16 的网格)。
特征维度:每个 Token 是 768 维(DINOv2-Base 的输出维度)。
由像素变特征:现在我们的“真值”不再是
[256, 256, 3]的图片,而是[256, 768]的特征矩阵。
第一阶段:准备输入 (Diffusion 侧) —— <修改点 1>
1. 采样与加噪
输入:不再是像素噪声,而是特征空间的高斯噪声。
维度:直接就是
[256, 768](序列长度 x 特征维度)。注意:这里没有 H × W × 3 这个概念了,起步就是序列。
任务:DiT 需要根据这个噪声特征,预测出 DINOv2 看到的那个干净特征。
第二阶段:进入 ViT 内部 —— <修改点 2: 架构大改>
2. 切块 (Patchify)
RAE 做法:因为输入
[256, 768]本身就是 Token 序列了,我们不需要再切图片。操作:Patch Size = 1。即把每一个特征向量视为一个 Token。
数据维度 (n):768。
3. 线性嵌入 (Linear Projection) —— <瓶颈出现> 我们决定用 DiT-Small,它的隐藏层宽度 d=384。
操作:把输入的 768 维特征投影到 384 维。
数据维度:从
[256, 768]变为[256, 384]。警报:384 < 768,信息发生坍缩!(如果是标准 DiT,到这就已经注定失败了)。
4. Transformer Backbone 处理
操作:在 384 维的低维空间里,通过 Self-Attention 处理上下文关系。
数据维度:保持
[256, 384]。作用:这一步主要负责“思考”Token 之间的关系(比如左上角的 Token 和右下角的 Token 有什么关联),虽然信息不全,但能处理语义逻辑。
5. DDT Head (Diffusion Head) —— <关键修改: 救世主> 这是 RAE 论文为了解决第 3 步坍缩问题引入的特殊模块。在 Backbone 之后,不直接输出,而是接一个很宽的网络。
操作:把 384 维的特征,升维映射到一个很宽的维度,比如 2048。
结构:一个只有 2 层的浅层 Transformer,但宽度是 2048。
数据维度:从
[256, 384]变为[256, 2048]。原理:此时宽度 (2048) >= 原始数据维度 (768)。模型终于有足够的空间来重构那些复杂的、全秩的高维噪声信息了。
6. 预测输出 (Prediction) —— <修改点 3: 目标>
操作:从 2048 维映射回 768 维。
预测目标:RAE 推荐预测 速度场 v (Velocity),而不是 x。
数据维度:变回
[256, 768]。
第三阶段:还原与解码 (Decoder 侧) —— <修改点 4: 独立解码器>
在 RAE 里,还原是一个神经网络推理过程。
7. 得到干净特征
通过 Diffusion 采样循环,我们最终得到了一个纯净的
[256, 768]张量。这代表 DINOv2 对那张图片的“理解”。
8. RAE 解码器 (Learned Decoder)
有一个专门训练好的轻量级 ViT 解码器。
输入:
[256, 768]的特征。操作:这个解码器负责把抽象的语义特征,翻译回 RGB 像素。
注:训练这个解码器时,我们特意加了噪声让它抗造(Noise-augmented decoding)。
输出:
[256, 256, 3]的图像。
总结:修改的核心逻辑
步骤
(JiT/Pixel)
(RAE)
为什么改?
输入
像素噪声 [256, 256, 3]
特征噪声 [256, 768]
利用预训练模型(DINO)的强语义
数据维度 (n)
3072 (来自 32 x 32 x 3)
768 (来自 DINOv2-Base)
没变,但含义变了(像素vs特征)
模型宽度 (d)
768 (Base)
384 (Small)
假设我们要省算力
瓶颈
无 (虽然3072 > 768,但是x-pred)
有 (768 < 384)
RAE 要解决的核心困难
特殊结构
无
DDT Head (宽2048)
在最后时刻把维度撑开,防止崩溃
预测目标
x (图片)
v (速度场)
RAE 证明宽头结构能预测 v
最后一步
Unpatchify (拼图)
训练好的解码器网络
特征不是像素,需要翻译
Diffusion As Self-Distillation (DSD): End-to-End Latent Diffusion In One Model (2025)
输入:
训练阶段: 原始的RGB图像(如ImageNet数据集)及其对应的类别标签。
推理/生成阶段: 随机的高斯噪声向量(Latent noise)和目标类别标签(Class label)。
输出:
高质量的 生成图像(例如 256x256 分辨率)。
一个单一的、统一权重的 Vision Transformer (ViT) 模型,它同时具备编码、去噪(扩散)和解码的能力。
解决的任务:
端到端训练潜在扩散模型 (End-to-End Latent Diffusion):打破了传统LDM需要分阶段训练独立VAE(编码器/解码器)和扩散模型的设计,将这三个组件统一为一个单体网络进行训练。
解决“潜在坍塌” (Solving Latent Collapse):解决了将编码器和扩散模型联合训练时,潜在空间维度急剧下降导致生成失败的问题。文章通过将扩散过程重新建模为“自蒸馏”(Self-Distillation),利用秩差分机制(Rank Differentiation)稳定了训练,实现了高效、高性能的单模型图像生成。
Motivation
现状与痛点
标准的潜在扩散模型(Latent Diffusion Models, LDMs,如Stable Diffusion)采用的是三阶段的模块化设计:
预训练 VAE 编码器(Encoder): 将图像压缩到潜在空间。
扩散模型(Diffusion Model): 在潜在空间学习去噪。
预训练 VAE 解码器(Decoder): 将生成的潜在变量还原为图像。
这种设计存在三个主要问题:
缺乏统一性 (Lack of Unification): 这种多组件架构阻碍了扩散模型与视觉基础模型(如使用单一网络的对比学习或自蒸馏模型)的统一。
次优性能 (Suboptimal Performance): VAE 是独立训练的,其重构损失不考虑后续扩散模型的具体需求;而扩散模型也只优化生成,不调整潜在空间。
计算开销 (Computational Overhead): 独立的编码器和解码器占用了大量参数(可达20%)并增加了推理延迟。
核心问题
能否将编码器、解码器和扩散模型统一到一个单一的、端到端训练的网络中?
之前的简单尝试(Naive Joint Training)直接将它们连在一起训练,结果发生了 Latent Collapse(潜在空间坍塌) :潜在表示的维度急剧下降,所有图像的潜在向量趋向于同一个点,导致重构和生成彻底失败。
理论视角:扩散即自蒸馏
作者并没有仅仅将其视为工程问题,而是建立了一个理论框架,将 潜在扩散模型(Latent Diffusion) 与 自蒸馏(Self-Distillation, SD) 无监督学习(如BYOL, DINO)联系了起来。

相似性:
自蒸馏 (SD): 编码器 E1 处理增强后的图像 x+ 得到 z1,经过预测器 P 后,去拟合由目标编码器 E2(通常是EMA更新)处理原图 x 得到的 z2
潜在扩散: 编码器 E 产生潜在变量 z。
分支1(输入):z 加噪变成 zt,进入扩散模型 vθ(相当于预测器 P)。
分支2(目标):z 用于计算损失函数中的目标(如 z-ε)。
结论: 扩散模型的训练过程在结构上等同于一种特殊的自蒸馏。
坍塌的根源 (Rank Differentiation Mechanism): 自蒸馏不发生坍塌的条件是:目标表征的有效秩(Effective Rank)必须高于预测表征的有效秩。
erank(Target)>erank(Predictor Output)这意味着预测器 P 必须充当一个低通滤波器(Low-pass filter),去除高频信息,降低秩。如果预测器输出了高秩信号(如噪声),循环就会被打破,导致坍塌。
Methodology - DSD 的构建过程
作者通过逐步诊断 naive 训练失败的原因,推导出了 DSD 方法。这是一个迭代优化的过程。
统一符号表示
设 z1 为输入分支的潜在变量,z2 为目标分支的潜在变量。通用损失形式为:
失败原因 1:潜在方差抑制 (Latent Variance Suppression)
现象: 直接使用标准扩散损失进行端到端训练,潜在空间的有效秩迅速掉到 1(即所有 z 都一样)。
原因: 标准扩散损失是:
∥v(zt,t)−(z−ϵ)∥2数学分解后发现,该损失包含一项与目标 z 的方差成正比的项。为了最小化损失,梯度会强迫编码器 E 减小 z 的方差,导致 z 聚集到均值点,引发坍塌。
解决方案 1:解耦 (Decoupling) 借鉴自蒸馏的做法,对目标分支的潜在变量使用 Stop-Gradient (sg) 操作。
L=∥v(zt,t)−(sg(z)−ϵ)∥2注意: 这与 REPA-E [24] 不同。REPA-E 完全切断了扩散损失对 VAE 的梯度。而这里只是切断了作为“目标”的 z 的梯度,作为输入 zt 的那个 z 仍然允许梯度回传。这意味着扩散任务仍然可以指导潜在空间的学习。
失败原因 2:违反秩差分机制 (Rank Differentiation Violation)
现象: 即使加了 Stop-Gradient,模型在训练后期仍然会发生坍塌(虽然慢了一些)。
原因: 再次回到秩稳定性条件:erank(Target)>erank(Predictor) 在标准扩散中,预测目标是速度 v ≈ z - ε。预测器 P 试图输出 v。 由于 v 包含了纯噪声 ε,噪声是全秩(Full-Rank)且高维的。这导致预测器的输出具有极高的秩。 结果:erank(Target z)<erank(Predictor Output v) 这违反了稳定性条件,导致预测器无法作为低通滤波器,最终引发坍塌。
解决方案 2:损失变换 (Loss Transformation) 必须改变预测目标,让预测器不再输出高频噪声。 利用几何关系 v=z−ϵ∝z−zt 作者证明了预测“速度 v”在数学上等价于预测“干净的潜在变量 z”。 作者将预测目标改为直接预测去噪后的 Clean Latent z。
Lz=E[∥v~(zt,t)−z∥2]为什么有效? 预测 z 本质上是一个**去噪(Denoising)**任务。去噪模型会自动去除输入 zt 中的高频噪声 ε 来恢复 z。因此,预测器 $\tilde{v}$ 自然变成了一个 低通滤波器,降低了输出的有效秩。 这满足了稳定性条件,从而稳定了训练。
DSD 增强:完整的自蒸馏桥梁
为了进一步提升性能,作者引入了现代自蒸馏(如DINO, BYOL)的标准操作:
EMA 目标编码器 (EMA Target Encoder): 这提供了更平滑、更稳定的训练目标。目标 z2 不再直接由在线编码器 E1 生成,而是由一个动量更新(EMA)的编码器 E2 生成:
数据增强 (Data Augmentation): 这迫使模型从被破坏的、噪声大的输入中恢复出一致的、干净的特征。为了强化预测器的低通滤波性质,对在线分支的输入 x 施加更强的数据增强,得到 x+,生成 z1 = E1(x+)。而目标分支使用原图 x 生成 z2。
最终 DSD 训练目标
结合以上所有点,DSD 的核心训练损失(Self-Distillation Loss)为:

其中:
zt=AddNoise(z1,t)
z1=E1(x+)(强增强,在线网络)
z2=E2(x)(弱增强,EMA网络)
v~预测的是干净的z2
Architecture
DSD 实现了一个真正统一的架构,基于标准的 Vision Transformer (ViT)。
骨干网络 (Backbone): 一个单一的 ViT,处理所有的特征提取和变换。
多头设计 (Multi-Head):
Latent Head (Encoder): 类似 ViT Tokenizer,将图像 Patch 转换为潜在 Token。
Image Head (Decoder): 将潜在 Token 还原为图像 Patch。
Diffusion Head: 一个 DiT 块,处理加噪的 Latent 并输出预测。
辅助损失 (Auxiliary Losses) & 采样头:
Detached Velocity Loss (Lvelo): 虽然主干是用预测 z 训练的,但为了采样(Sampling)方便(通常使用预测 v 的求解器),作者加了一个额外的轻量级 Head 来预测速度 v。关键点: 这个 Head 的梯度被切断(Detached),不回传给主干,以免破坏 DSD 的稳定性。
Reconstruction Loss (Lrec): 包含 L2, LPIPS 和 GAN Loss。为了正则化,使用了 "Noise Interpolation" 策略将噪声注入重构过程。
Alignment Loss: 浅层特征与 DINOv3 对齐,深层特征进行自蒸馏。
Classification Loss: 利用 ImageNet 标签辅助学习语义特征。
总结 DSD 的技术突破点
诊断精准: 首次将扩散训练的失败归因于违反了自蒸馏的“秩差分机制”。
去噪即低通: 发现将预测目标从“速度/噪声”改为“原图Latent”,本质上是强制网络做低通滤波,从而满足稳定性条件。
完全解耦: 通过 Stop-Gradient 和 Detached Head,既保留了扩散对Latent空间的指导,又避免了方差抑制和高秩信号的干扰。
架构极简: 没有独立的巨大 VAE,不需要多阶段训练,一个 ViT 从头练到尾。
这种方法在 ImageNet 256x256 上取得了惊人的效果(FID=4.25),且参数量极小(仅 205M),证明了将生成模型与自蒸馏表征学习统一的可行性和巨大潜力。
Representation Entanglement for Generation (REG): Training Diffusion Transformers Is Much Easier Than You Think (2025)
输入:
训练阶段:原始图像的潜变量 (Image Latents) + 预训练视觉大模型 (如 DINOv2) 提取的 高级语义 Class Token。
推理阶段:用于图像部分的 随机高斯噪声 + 用于 Class Token 部分的 随机高斯噪声 (两者在输入端被拼接在一起)。
输出:
生成的 高质量、高保真度的 2D 图像。
(过程产物) 同步重构出的 判别性语义 Token (它在去噪过程中充当“向导”,但在最终输出图像时被丢弃)。
解决的任务:
极大幅度加速扩散 Transformer (如 SiT, DiT) 的训练收敛。通过这种方法,模型训练速度比原始 SiT 快 63 倍,比之前的加速方法 REPA 快 23 倍。
解决推理阶段缺乏高质量语义引导的问题。REG 提出“表示纠缠”策略,强迫模型在推理时从纯噪声中同时恢复图像和语义特征,从而让模型“自己生成自己的语义向导”,显著提升了生成质量和语义一致性。
Motivation
背景:生成模型作为表示学习者
近年来,扩散模型(如LDM, DiT, SiT)在图像生成领域取得了巨大成功。研究表明,生成模型在训练过程中不仅学习了如何生成像素,还隐式地学习了图像的判别性特征(Discriminative Representations)。然而,这种学习过程非常缓慢,且学到的特征质量往往不如专门的预训练视觉模型(如DINOv2, CLIP)。
现有方法的局限性 (REPA)
为了加速训练,先前的SOTA方法 REPA (Representation Alignment) 引入了“外部对齐”机制。
REPA的做法:在训练时,强迫扩散模型的中间层特征与预训练视觉编码器(如DINOv2)提取的特征保持一致(通过计算相似度损失)。
REPA的问题:这种对齐是外部的且仅存在于训练阶段。
在推理(Inference)阶段,也就是去噪生成图像时,预训练的视觉编码器是不存在的(为了节省推理成本)。
因此,扩散模型无法在推理过程中直接获得那些高质量的判别性语义信息作为引导。这种“训练有引导,推理无引导”的差异,限制了模型充分利用判别性特征的能力。
REG的出发点
作者认为,应该让这些高质量的语义信息直接参与到生成过程中,不仅在训练时存在,在推理时也能被模型“感知”和“利用”。
核心思想:将预训练模型的“Class Token”(代表全局语义)视为生成目标的一部分。
做法:不仅仅生成图像,而是同时生成“图像”和“语义Token”。这样,在推理的一开始(纯噪声阶段),模型就开始构建语义信息,并用这些语义信息来指导图像细节的生成。
Method
这是本文最核心的部分。REG建立在 SiT (Scalable Interpolant Transformers) 的基础之上。
预备知识:SiT与流匹配 (Preliminaries)
SiT 使用随机插值(Stochastic Interpolants)框架,统一了扩散模型和流模型(Flow Matching)。 定义数据样本为: x∗
高斯噪声为: ϵ
前向过程定义为: xt=αtx∗+σtϵ
其中,t ∈ [0, 1] 是时间步,αt 和 σt 控制噪声调度的系数。
模型的目标是学习一个速度场(Velocity Field),使得我们可以通过逆向求解常微分方程(ODE)或随机微分方程(SDE)从噪声恢复出数据。v(xt,t)
REG 的核心机制:表示纠缠 (Representation Entanglement)

REG 不仅处理图像潜变量,还引入了视觉基础模型的 Class Token。
1. 输入定义:
图像潜变量 (Image Latents): z∗∈RDz×Cz×Cz
这是通过VAE编码器得到的压缩图像特征(例如 Stable Diffusion 的 VAE)。
语义 Token (Visual Class Token): f∗ 通过视觉编码器(如 DINOv2)提取的特征,其中包含 N 个视觉 Token。REG 专门提取其中的全局 Class Token,记为 cls∗∈R1×Dvf
2. 联合加噪 (Synchronized Noise Injection): 这是 REG 与传统条件生成(Conditioning)最大的不同。通常 Class Label 是作为条件(Clean Condition)输入的,但在这里,Class Token 被视为需要生成的数据的一部分,因此也要加噪。
给定两个高斯噪声采样
3. Token 拼接与输入构造 (Concatenation): 在送入 Transformer(SiT Block)之前,进行如下处理:
Patchify: 将图像潜变量zt展平为序列zt′∈RN×Dz′
Projection: 将加噪的ClassToken:clst通过一个线性层投影到与图像潜变量相同的维度Dz′,得到clst′
Entanglement (拼接): 将两者在序列维度上拼接: ht=[clst′;zt′]∈R(N+1)×Dz′ 这个 ht 就是 SiT 模型的输入。这意味着 Transformer 的第一个 Token 承载着“加噪的全局语义”,后续 Token 承载着“加噪的图像细节”。
训练目标
REG 的训练损失由两部分组成:预测损失和对齐损失。
1. 速度场预测损失 (Prediction Loss): 模型需要预测图像和 Token 的去噪方向(Velocity)。由于输入是拼接的,输出也是拼接的。我们将模型输出拆分为针对图像的部分和针对 Token 的部分:
损失函数定义为:
第一项是标准的图像生成损失。
第二项是 Token 生成损失。
β 用于平衡两者权重(文中实验最佳值为 0.03)。
2. 表示对齐损失 (Alignment Loss - 继承自 REPA): 为了确保模型内部学到高质量特征,REG 保留了 REPA 的对齐机制。 在 Transformer 的第 n 层(例如第 4 层或第 8 层),提取隐藏状态 hϕ(ht[n]),并使其与预训练视觉编码器(由真实 Class Token 和 Patch Token 组成)的真实特征对齐:y∗
这迫使 SiT 的中间层特征在语义上逼近 DINOv2 等强力视觉模型。
3. 总损失 (Total Loss):
推理过程
这是 REG 最精妙的地方。
初始化:
采样随机高斯噪声作为图像初始状态: zT∼N(0,I)
采样随机高斯噪声作为 Token 初始状态: clsT∼N(0,I)
联合去噪:
将两者拼接,输入 SiT 网络。
网络同时输出图像和 Token 的更新方向。
随着时间步 t 从 1 走向 0,噪声逐渐减少。
自我引导:
在这个过程中,Class Token会逐渐从纯噪声演变为一个具有明确语义的向量。
由于 Self-Attention 机制,图像部分的 Token 会不断查询(Query)这个正在形成的 Class Token。
这意味着模型自己生成了自己的语义向导,并利用这个向导来完善图像生成的结构和细节。
输出:最终只保留图像部分 zθ,丢弃生成的 Token,经 VAE 解码得到图像。
技术细节与配置
基础模型: 使用 SiT (Scalable Interpolant Transformers) 作为 Backbone。
视觉编码器: 使用 DINOv2-ViT-B/14 提取目标特征和 Class Token。
对齐层 (Alignment Depth):
对于 SiT-B/2 模型,在第 4 层进行对齐。
对于 SiT-L/2 和 SiT-XL/2 模型,在第 8 层进行对齐。
这说明在网络的早期/中期注入语义信息效果最好。
超参数:
Token 预测损失权重 β = 0.03。
对齐损失权重 λ(具体值需参考代码或附录,通常为常数)。
计算开销: 推理时仅增加 1个 Token 的计算量(相比于原本的 256 个 Token),FLOPs 和延迟增加不到 0.5%,几乎可以忽略不计。
实验结果与优势
极速收敛:
在 ImageNet 256x256 上,SiT-XL/2 + REG 仅需训练 110K 步即可达到 SiT-XL/2 训练 7M 步的性能水平。
训练速度比原始 SiT 快 63倍。
比之前的加速方法 REPA 快 23倍。
生成质量:
FID 分数显著降低(越低越好)。
仅训练 400K 步的 SiT-L/2 + REG 击败了训练 4M 步的 SiT-XL/2 + REPA(后者模型更大且训练时间长10倍)。
判别性语义: 通过 CKNNA 指标分析,REG 在推理过程中能够保持极高的语义一致性,证明了“纠缠”策略确实让模型学到了更好的语义表示。
总结
REG 的核心创新在于打破了“外部对齐”的思维定势,通过将判别性特征(Class Token)作为生成目标的一部分进行纠缠训练,使得模型在推理时能够自发地重构出高质量的语义引导。这种方法在几乎不增加推理成本的前提下,实现了惊人的训练加速和质量提升。
最后更新于