GS自编码
@TOC
Learning Unified Representation of 3D Gaussian Splatting (ICLR 2026)
输入:
单个 3D高斯基元 (Gaussian Primitive) 的原始参数 θ = {μ, q, s, c, o}。
(预处理中):将该基元转化为 等概率子流形场 (Submanifold Field),即在以高斯中心为原点的椭球面上均匀采样的、携带颜色场信息的点云集合。
输出:
一个低维、紧凑且几何/语义连续的 潜在特征向量 (Latent Embedding) (作为中间表示)。
重建后的 3D高斯基元参数 (通过解码出的流形场点云,经由 PCA 和球谐函数拟合恢复得到)。
解决的任务:
3D高斯基元的统一表示学习 (Representation Learning)。
旨在解决原始 3DGS 参数直接用于神经网络学习时存在的 非唯一性 (Non-uniqueness) (如四元数双重覆盖) 和 数值异质性 (Numerical Heterogeneity) 问题。
通过提出的 SF-VAE 框架,将高斯基元映射到一个数学性质良好(唯一对应、连续变化、抗噪性强)的潜在空间,为下游任务(如 3DGS 的生成、压缩、插值编辑)提供更优的特征空间。
动机:为什么要放弃原始 3DGS 参数?
在目前的 3DGS 生成或压缩任务中,大多数工作直接回归或处理原始参数集合 θ = {μ, q, s, c, o}。作者指出,这种做法在理论上是存在根本缺陷的,总结为两大问题:
A. 表示的非唯一性 (Representation Non-uniqueness)
这是一个“多对一”的问题,即多个不同的参数组合可以产生完全相同的渲染效果(Radiance Field)。这会导致神经网络训练时的梯度冲突和无法收敛。
四元数符号模糊性: q 和 -q 代表完全相同的旋转。如果网络需要预测旋转,这两个数值相反的目标会让网络产生困惑(比如插值时会经过零点,导致几何坍塌)。
几何对称性: 对于一个椭球体,沿着其轴旋转 180 度,或者交换轴的长短(如果对应旋转也改变),其占据的空间形状是不变的。
SH 系数冗余: 旋转球谐系数可以通过 Wigner D-matrix 变换得到等价的新系数。
B. 数值异质性 (Numerical Heterogeneity)
3DGS 的参数分布在性质迥异的流形上,不符合神经网络对特征“同分布”的假设:
位置 μ:在欧氏空间 R3,范围可能很大。
旋转 q:在 SO(3) 流形上,必须是单位向量。
缩放 s:在 (R+)3 上,通常是指指数级变化。
SH 系数 c:高阶系数数值极小,但对高频细节影响很大。
结论: 直接将这些参数拼接成一个向量喂给 MLP,实际上强迫网络去拟合这些复杂的流形结构和数值差异,导致泛化能力差、插值抖动(Jitter)以及对噪声极其敏感。
核心方法:流形场表示 (Submanifold Field Representation)
为了解决上述问题,作者提出放弃直接学习参数,转而学习高斯基元在空间中产生的场。
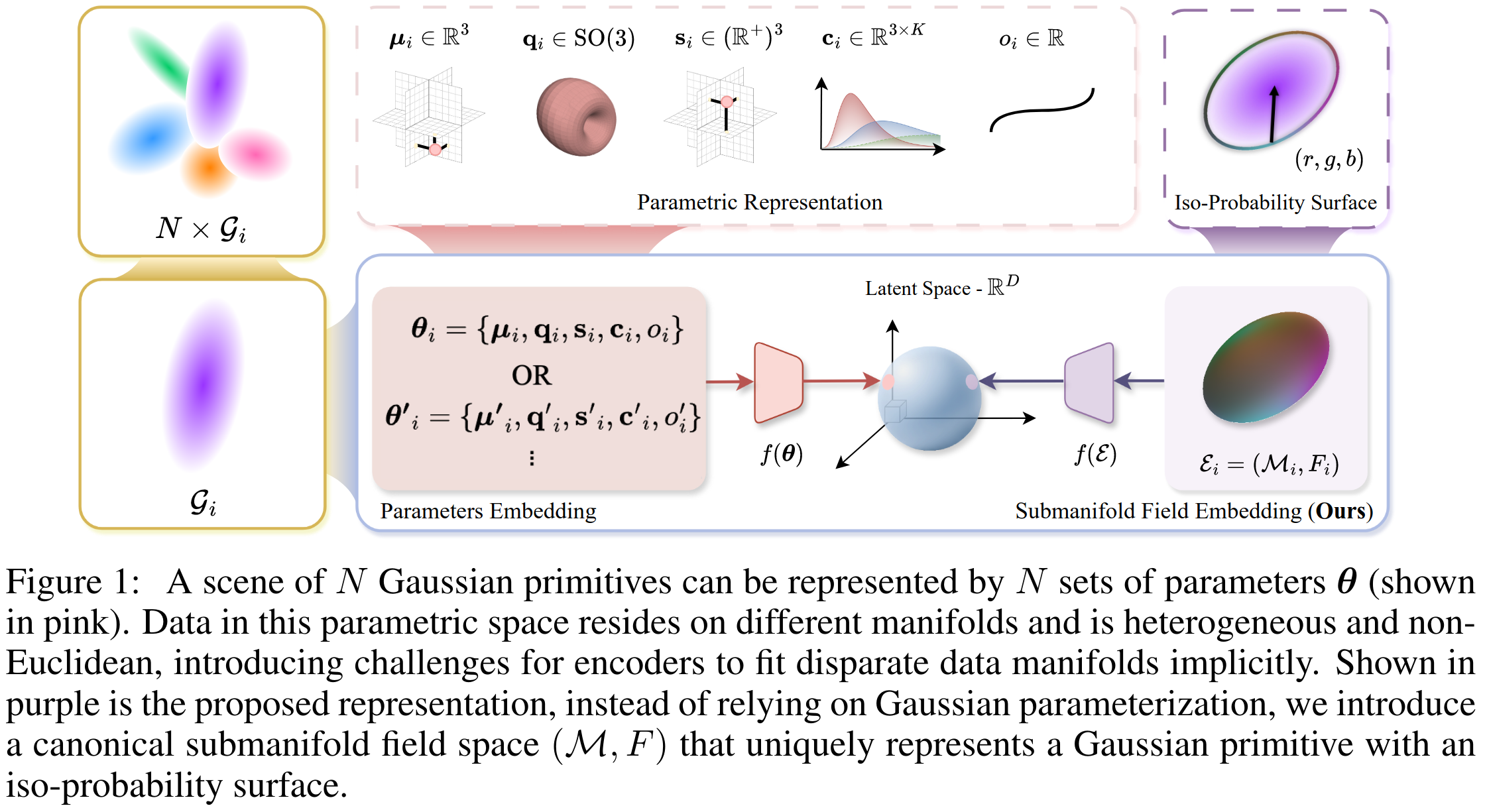
定义等概率子流形 (Iso-Probability Submanifold)
对于每一个高斯基元 Gi,其空间概率密度由均值 μi 和协方差 Σi 决定。作者定义了一个等概率曲面(即椭球表面)作为该高斯的几何代理。
设定一个固定的半径 r(例如 r=1),这个子流形 Mi 定义为:
这个 Mi 实际上就是一个以 μi 为中心,形状由 Σi 决定的椭球面。
定义流形上的颜色场
在这个曲面上,每一点 x 不仅有位置信息,还有颜色信息。作者定义了一个场函数 Fi(x):
其中,σ(oi) 是不透明度,Colori 是视相关颜色。
注意这里的 dx 是从中心指向表面点 x 的单位方向向量:dx = (x - μi) / ||x - μi||。
关键性质: 作者证明了,对于任意一个单高斯辐射场(Single Gaussian Radiance Field),存在唯一对应的子流形场表示 E = (M, F)。这意味着我们消除了四元数的符号歧义和几何对称性带来的多解问题。
模型架构:SF-VAE
为了将上述连续的数学定义转化为网络可以处理的形式,作者设计了 Submanifold Field Variational Auto-Encoder (SF-VAE)。
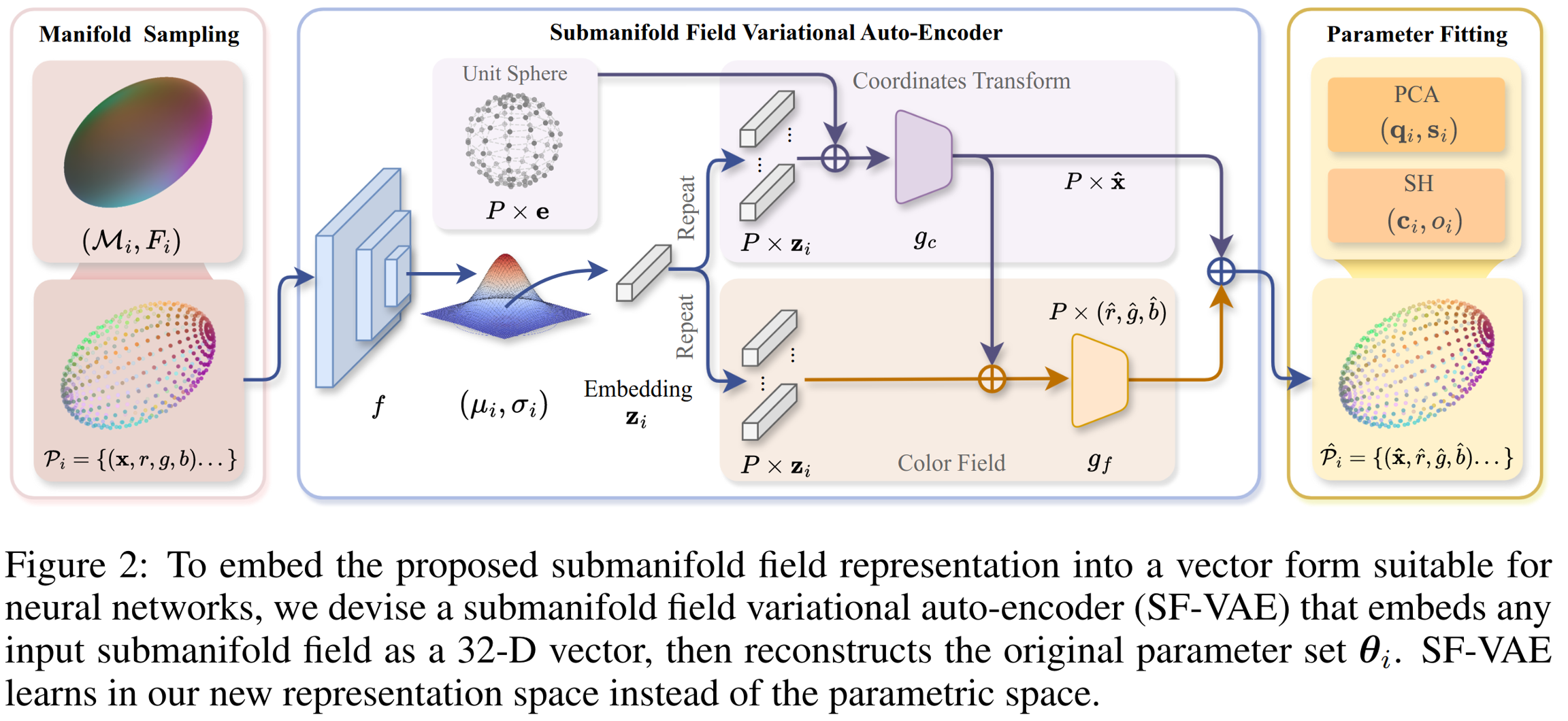
离散化与输入
网络无法处理连续曲面,所以首先要离散化。
采样:在标准单位球面上均匀采样 P 个点(例如 P=144)。
映射:将这些点映射到每个高斯的椭球表面 Mi 上。
特征:每个点携带的信息不仅是坐标 (x,y,z),还有在该点计算出的颜色场值 F(x)(RGB)和不透明度 α。
最终输入:一个点云 Pi = {(xm, F(dx_m))},形状为 (P, 7),包含
[x, y, z, r, g, b, α]。
编码器
目标是将输入点云压缩为一个低维潜变量 z(例如 32 维)。
架构:采用 PointNet 结构。因为点云是无序的,PointNet 具有置换不变性(Permutation Invariance),非常适合处理这种采样点集。
过程:输入 Pi 通过 MLP 提取特征,进行最大池化(Max Pooling)得到全局特征,最后映射到均值 μz 和方差 σz。
重参数化:使用 VAE 标准的 Reparameterization Trick 采样得到潜向量 z。
解码器
这是本篇工作最精彩的设计之一。解码器不是直接回归 μ, q, s,而是重建流形场点云,然后再解算出参数。
解码器包含两个隐式函数网络:
坐标变换网络 (gc):
输入:单位球上的规范坐标点集 UP' 和潜向量 z。
作用: 将单位球上的点变形为目标椭球面上的点。
输出:变形后的点云坐标。它实际上学会了如何将单位球拉伸、旋转、平移成目标高斯的椭球形状。
颜色场网络 (gf):
输入:变形后的坐标和潜向量 z。
输出:每个点上的颜色和不透明度。
输出是一个重构的点云 Phat。
从点云恢复高斯参数 (Parameter Recovery)
这是技术细节中的重点。网络输出了点云,怎么变回 3DGS 渲染器需要的 q, s, c?作者没有使用额外的 MLP 来回归,而是使用解析解和经典算法,保证了数值稳定性:
恢复几何 (μ, Σ):对重构的点云坐标进行 PCA (主成分分析)。
均值 μ:点云的重心。
协方差 Σ:点云的协方差矩阵。
分解:对 Σ 进行特征分解,特征值对应缩放 s (取对数),特征向量构成的旋转矩阵转换为四元数 q。
恢复外观 (c, o):
SH 系数:利用最小二乘法(Least Squares),根据点云中每个点的方向和 RGB 值,拟合出球谐系数 c。
不透明度 o:取点云中不透明度值的平均。
这种设计确保了生成的参数一定是在合法的几何空间内(例如协方差矩阵一定是半正定的),避免了直接回归参数可能导致的非物理结果。
训练目标:Manifold Distance (M-Dist)
由于输入和输出都是定义在流形上的分布(点云),作者提出使用 最优传输(Optimal Transport) 理论中的 Wasserstein-2 距离作为重建损失,称为 Manifold Distance。
公式如下: Lrec=W22(P,P^)=minΓ∈Π(P,P^)∑i,jΓijd2(pi,p^j)
其中基距离 d2 定义为空间距离和颜色距离的加权和: d2((x,cx),(y,cy))=∥x−y∥22+λ∥cx−cy∥22
直观解释:这个损失函数寻找一种“搬运方案”,将预测的点云“搬运”到真实的点云,使得移动的几何距离和颜色变化的代价最小。相比于 L1 或 L2 Loss 直接作用于参数,M-Dist 更符合人类的感知,并且对旋转和平移具有更好的鲁棒性。
总 Loss:L = L_rec + β * KL_Divergence。
启发
这篇论文对三维视觉研究有几个非常重要的启发点:
表示学习 (Representation Learning) 是核心:不要局限于别人提供的数据格式(如原始 3DGS 参数)。如果原始格式不适合神经网络(如存在多解性、流形不匹配),**设计一个中间表示(Proxy Representation)**往往能带来性能的飞跃。本文将参数转化为“几何+场”的点云,就是一种升维再降维的智慧。
结合传统算法与深度学习:这篇论文没有让网络去死记硬背如何输出四元数,而是让网络输出直观的几何形状(点云),然后用 PCA 这种传统且鲁棒的算法来提取参数。这种可微分的传统算法层(PCA 本身是可导的)嵌入网络中,通常比纯 MLP 回归效果更稳定。
损失函数要符合物理/几何意义:直接在参数空间做 MSE(比如
||q1 - q2||)往往是错误的,因为参数空间和结果空间(渲染图)不是线性的。使用 Wasserstein Distance 或者 Chamfer Distance 这类集合距离,能够更好地衡量几何结构的一致性。数据归一化:注意论文中提到的 Latent Space Interpolation(潜空间插值)。在原始参数空间插值会导致高斯旋转乱跳,而在他们的流形空间插值则非常平滑。这提示我们在做生成模型(如 Diffusion for 3DGS)时,寻找一个连续、紧凑的 Latent Space 是关键。
最后更新于