transformer经典工作阅读笔记
@TOC
Attention is All You Need (2017)
这篇论文于2017年由Google的研究人员发表,介绍了Transformer模型,它彻底改变了自然语言处理(NLP)领域。它的核心思想是,完全抛弃以往序列处理任务中占主导地位的循环神经网络(RNN)和卷积神经网络(CNN)结构,仅依靠 注意力机制(Attention Mechanism) 来捕捉输入和输出序列之间的全局依赖关系。
输入:一个代表源信息的词元序列(a sequence of tokens)。在机器翻译任务中,这就是源语言的句子(例如,一句英文)。
输出:一个代表目标信息的词元序列。在机器翻译任务中,这就是目标语言的句子(例如,翻译好的法文)。
解决的任务:该模型主要解决序列到序列(Seq2Seq)的任务,最典型的例子是机器翻译。它旨在通过完全依赖注意力机制来捕捉序列内的长距离依赖关系,从而取代了以往在NLP领域占主导地位的RNN和CNN架构,解决了它们在并行计算和长距离信息传递上的瓶颈。
Motivation
在Transformer出现之前,序列到序列(Seq2Seq)任务,如机器翻译,主要依赖于包含编码器(Encoder)和解码器(Decoder)的RNN(特别是LSTM和GRU)模型。
这些模型存在几个核心痛点:
顺序计算的瓶颈 (The Bottleneck of Sequential Computation)
RNN的本质是顺序处理。要计算时刻
t的隐藏状态 ht,必须先完成时刻t-1的计算。ht=f(ht−1,xt)这种内在的顺序性阻碍了并行化。在处理长序列时,你无法同时计算所有时间步,这使得在现代GPU/TPU等擅长并行计算的硬件上训练变得非常缓慢。
长距离依赖问题 (Long-Range Dependency Issues)
理论上,RNN可以处理任意长度的序列,但实际上,信息在通过长序列的多个时间步传递时,会逐渐丢失或扭曲(即梯度消失/爆炸问题)。
尽管LSTM和GRU等门控机制在一定程度上缓解了这个问题,但对于非常长的序列,捕捉远距离词语之间的依赖关系仍然是一个巨大挑战。信息从第一个词传递到最后一个词的路径长度是
O(n),其中n是序列长度,路径越长,信息损失越严重。
CNN的尝试与局限
像ByteNet和ConvS2S等模型尝试使用CNN来代替RNN,以实现并行计算。CNN确实可以并行处理,但它们的主要问题是感受野有限。
为了捕捉长距离依赖,需要堆叠非常多的卷积层,或者使用空洞卷积(Dilated Convolutions)。这使得两个任意位置之间的信息传递路径长度仍然是
O(n/k)(k为卷积核大小)或O(log(n)),而不是常数时间。
核心动机总结: 研究人员希望设计一个模型,既能强大地捕捉序列内的长距离依赖关系,又能摆脱RNN的顺序计算限制,实现大规模并行化,从而显著提升训练速度和模型性能。Transformer的目标就是用一种全新的方式来解决这个问题,即完全依赖注意力机制。
Architecture
Transformer沿用了主流的 编码器-解码器(Encoder-Decoder) 架构,如下图所示。

整体结构
编码器 (Encoder):左侧部分。负责接收输入序列(例如,源语言句子),并将其转换为一系列连续的、富含上下文信息的表示(vectors)。它由 N=6 个完全相同的层堆叠而成。
解码器 (Decoder):右侧部分。负责接收编码器的输出和已经生成的目标序列部分,然后预测下一个词。它也由 N=6 个完全相同的层堆叠而成。
编码器(Encoder)内部结构

每个编码器层都由两个主要的子层 (Sub-layers) 构成:
多头自注意力层 (Multi-Head Self-Attention Layer):这是模型的核心。该层让输入序列中的每个位置都能关注到序列中所有其他位置,从而计算出该位置的上下文感知表示。
位置全连接前馈网络 (Position-wise Feed-Forward Network):这是一个简单的、在每个位置上独立应用的全连接网络,用于对注意力层的输出进行非线性变换。
每个子层外面都包裹着一个残差连接 (Residual Connection) 和一个层归一化 (Layer Normalization)。即每个子层的输出是 LayerNorm(x + Sublayer(x))。这对于训练深度网络至关重要,可以防止梯度消失,并稳定训练过程。
解码器(Decoder)内部结构

每个解码器层比编码器层多一个子层,共包含三个子层:
带掩码的多头自注意力层 (Masked Multi-Head Self-Attention Layer):与编码器中的自注意力类似,但增加了一个掩码 (mask)。这个掩码确保在预测位置
i的词时,模型只能关注到位置i及其之前的输出,而不能“看到”未来的词。这是为了保持模型的自回归 (auto-regressive) 特性,即一次生成一个词。编码器-解码器注意力层 (Encoder-Decoder Attention Layer):这是连接编码器和解码器的桥梁。在这一层,解码器可以关注到输入序列(即编码器的输出)的全部内容。它的Query来自前一个解码器子层(Masked Self-Attention的输出),而Key和Value则来自编码器的最终输出。这使得解码器在生成目标词时能够参考整个源句子。
位置全连接前馈网络 (Position-wise Feed-Forward Network):与编码器中的完全相同。
同样,每个子层也都采用了残差连接和层归一化。
Scaled Dot-Product Attention

这是Transformer注意力的核心计算单元。注意力机制可以被描述为将一个查询 (Query, Q) 和一系列键值对 (Key-Value, K-V) 映射到一个输出。
计算过程如下:
计算分数:计算查询
Q与所有键K的点积,以衡量Q和每个K的相似度。缩放:将点积结果除以一个缩放因子 sqrt(dk),其中 dk 是键向量的维度。这一步非常关键,因为当dk很大时,点积的值会变得非常大,导致Softmax函数的梯度变得极小,不利于训练。缩放可以缓解这个问题。
Softmax归一化:对缩放后的分数应用Softmax函数,将其转换为权重(概率分布),表示每个值
V的重要性。加权求和:将得到的权重与对应的值
V相乘并求和,得到最终的注意力输出。
公式表示为:
Attention(Q,K,V)=softmax(dkQKT)V


Multi-Head Attention
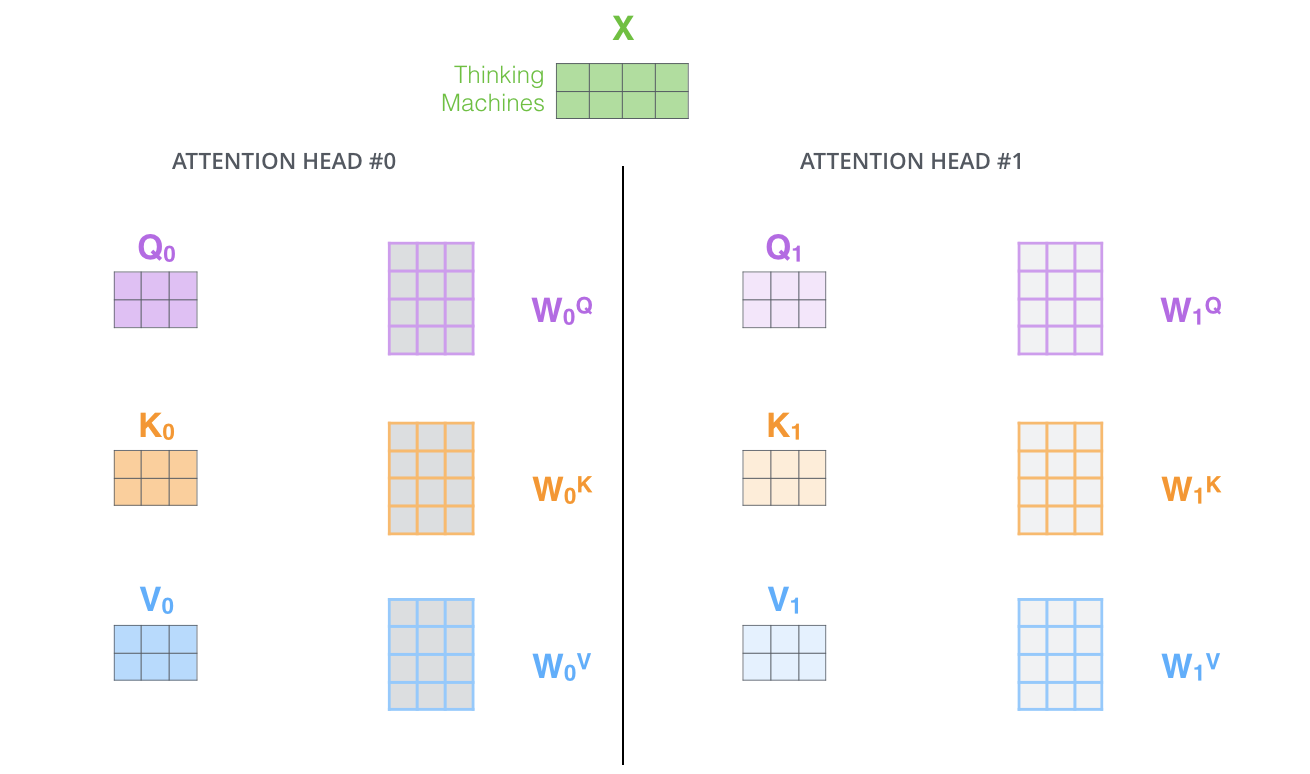
论文作者发现,只用一套Q, K, V进行一次注意力计算,可能会限制模型从不同角度理解信息。因此,他们提出了多头注意力。
其思想是:
线性投影:将原始的Q, K, V通过不同的、可学习的线性变换(权重矩阵)投影
h次(h是头的数量,论文中h=8)。这样就得到了h组不同的Q, K, V。并行计算注意力:对这
h组Q, K, V并行地执行缩放点积注意力计算,得到h个输出向量。拼接与再投影:将这
h个输出向量拼接(Concatenate)起来,再通过一个最终的线性变换,将其投影回原始的维度。
好处:多头注意力允许模型在不同的表示子空间 (representation subspaces) 中共同关注来自不同位置的信息。例如,一个头可能关注句法关系,另一个头可能关注指代关系,等等,从而增强了模型的表达能力。

Positional Encoding
自注意力机制本身是位置无关的。它处理的是一个集合,而不是一个序列。如果不加入位置信息,“猫在垫子上”和“垫子在猫上”对于模型来说可能没有区别。
为了解决这个问题,论文引入了位置编码。
方法:在将词嵌入向量送入编码器和解码器之前,给它们加上一个位置编码向量。这个向量的维度与词嵌入向量相同。
实现:论文中使用正弦和余弦函数来生成位置编码:
其中 pos 是词在序列中的位置,i 是编码向量中的维度索引。
优点:
每个位置的编码是唯一的。
这种编码方式使得模型可以轻易地学习到相对位置关系,因为对于任何固定的偏移量
k,PEpos+k 都可以表示为 PEpos 的线性函数。它能够推广到比训练集中所见过的序列更长的序列。
ViT: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (2020)
输入:一张二维图像。
输出:图像的类别标签(通过输出类别概率分布来预测)。
解决的任务:图像分类/图像识别。ViT的核心贡献是证明了纯Transformer架构,在没有CNN固有归纳偏置(如局部性)的情况下,可以直接应用于计算机视觉任务。它通过将图像分割成小块(patches)并将其视为一个序列,成功地将Transformer模型从NLP领域迁移到了CV领域,并证明了在大规模数据预训练下,其性能可以超越顶尖的CNN模型。
Motivation
在ViT出现之前,计算机视觉(CV)领域被CNN架构统治了近十年(从AlexNet在2012年大放异彩开始)。CNN的核心优势在于其归纳偏置(Inductive Bias),这非常适合处理图像任务:
局部性 (Locality): 卷积核只在局部感受野上操作,假设了空间上相邻的像素点关联性更强。
平移等变性 (Translation Equivariance): 图像中的物体无论移动到哪个位置,卷积操作都能提取出相同的特征。
这些“先验知识”让CNN在数据量不那么大的情况下也能高效学习。
与此同时,自然语言处理(NLP)领域已经被Transformer架构彻底改变。Transformer的核心是自注意力机制(Self-Attention),它允许模型在输入序列的任意两个位置之间建立联系,捕捉长距离依赖关系。但它缺少CNN那样的图像专用归纳偏置,它对输入元素的顺序是不敏感的(需要位置编码来弥补),并且是全局计算的。
ViT的动机就是回答以下几个关键问题:
Transformer能否摆脱CNN,直接用于图像识别? 以往的工作大多是将自注意力机制作为CNN的补充模块,而不是完全取代它。
CNN的归纳偏置是必需品吗? 作者推测,CNN的归纳偏置在数据量有限时是优势,但在数据量极其庞大时,这种“硬编码”的先验知识反而可能限制了模型的学习能力。
如果我们给一个没有图像偏置的Transformer模型足够多的数据,它能否自己学会这些空间结构和模式? 这就是论文的核心假设:“规模胜过归纳偏置(Scale trumps inductive bias)”。
Architecture
ViT的架构设计遵循了“尽可能保持NLP中Transformer原貌”的原则,整个流程非常简洁优雅,可以分解为以下几个步骤(参考论文图):

步骤 1: 图像分块 (Image Patching)
标准的Transformer接收一个一维的“词元”(token)序列作为输入。为了处理二维图像,ViT首先将图像分割成一系列固定大小的、不重叠的小方块(patches)。
例如,一张
224x224的图像,如果patch大小是16x16,那么就会被分割成(224/16) * (224/16) = 14 * 14 = 196个patches。这正是论文标题《An Image is Worth 16x16 Words》的由来:每个
16x16的图像块就像是句子中的一个“单词”。
步骤 2: 展平与线性投射 (Patch Embedding)
每个图像块(Patch)被 展平(flatten) 成一个一维向量。
对于一个
16x16的RGB图像块,其维度为16 * 16 * 3 = 768。然后,这个展平的向量会通过一个 可训练的线性投射层(Linear Projection) ,映射到一个固定的维度
D(例如D=768),这个输出被称为patch embedding。至此,一张二维图像就成功转化为了一个一维的
N x D的向量序列(N是patch数量),可以被Transformer处理了。
步骤 3: 引入[CLS] Token与位置编码 (Classification Token & Positional Embedding)
[CLS] Token: 借鉴了BERT模型的设计,在patch embedding序列的最前面,拼接(prepend)上一个可学习的特殊向量,称为
[class]token。这个token不代表任何一个具体的图像块,它的作用是在经过Transformer Encoder的充分信息交互后,其对应的最终输出向量将作为整个图像的全局特征表示,用于最终的分类任务。位置编码 (Positional Embedding): Transformer本身不具备处理序列顺序的能力(置换不变性)。为了让模型知道每个patch的原始空间位置,需要给每个patch embedding(包括
[CLS]token)加上一个位置编码。ViT使用的是标准的可学习的1D位置编码,每个位置都有一个独特的、可学习的向量。
步骤 4: Transformer Encoder (编码器)
经过上述处理后得到的向量序列(长度为 N+1)被送入一个标准的Transformer Encoder。
Encoder由
L个相同的层堆叠而成。每一层包含两个核心子模块:
多头自注意力 (Multi-head Self-Attention, MSA): 这是核心。它允许序列中的每个patch embedding(token)关注并融合序列中所有其他token的信息。这实现了全局信息交互,与CNN的局部感受野形成鲜明对比。
多层感知机 (MLP): 在MSA之后,每个token的输出会独立地通过一个MLP(通常是两个线性层加一个GELU激活函数)。
每个子模块前后都有层归一化 (LayerNorm),并使用了残差连接 (Residual Connection)。
步骤 5: 分类头 (Classification Head)
当序列通过整个Transformer Encoder后,我们只取[CLS] token在最后一层对应的输出向量。这个向量被认为是整个图像的聚合表示。
这个向量最后被送入一个简单的MLP分类头(在预训练时通常是带一个隐藏层的MLP,在微调时则是一个简单的线性层),最终输出图像的类别概率。
关键技术细节
1. 归纳偏置的缺失与大数据的重要性
ViT的弱点: 如前所述,ViT几乎没有内置的图像归纳偏置。它必须从零开始学习空间关系,比如“眼睛通常在鼻子的上方”,“相邻的patch可能属于同一个物体”等。
实验验证: 论文中的实验(Figure 3)完美地证明了这一点:
当在中等规模的数据集(如ImageNet-1k,约130万张图)上从头训练时,ViT的性能不如同等计算量的ResNet。这是因为它没有足够的数据来学习这些基本的视觉模式,容易过拟合。
当在大规模数据集(如ImageNet-21k,1400万张图;JFT-300M,3亿张图)上预训练后,ViT的性能开始超越ResNet。这表明,有了海量数据,ViT能够克服归纳偏置的缺失,学习到比CNN更强大、更通用的特征表示。
2. 微调与高分辨率处理 (Fine-tuning & Higher Resolution)
这是一个非常巧妙的工程细节。在下游任务(如对一个新数据集进行分类)上进行微调时,通常会使用比预训练时更高分辨率的图像,这能提升性能。
问题: 更高分辨率的图像意味着会产生更多的patches,输入序列的长度变了。预训练好的位置编码长度不匹配,该怎么办?
解决方案: ViT保持patch大小不变,因此序列长度
N会增加。作者对预训练好的位置编码进行2D插值,以匹配新的序列长度。例如,预训练时是14x14的位置编码,微调时如果是16x16,就将14x14的编码图插值到16x16。这是ViT中为数不多的、巧妙利用了图像2D结构信息的地方。
3. 混合架构 (Hybrid Architecture)
除了纯粹的ViT,论文还实验了一种混合架构:
先用一个CNN(如ResNet)来提取图像的低级特征图(feature maps)。
然后,将CNN输出的特征图视为“图像”,对其进行分块(patch size可以设为1x1),再送入Transformer。
实验发现,对于较小的模型和数据集,混合模型性能略优于纯ViT。但随着模型和数据规模的增大,纯ViT的潜力更大,最终会追上并反超。
4. 内部工作机制的可视化 (Inspecting ViT)
为了理解ViT学到了什么,作者做了一些可视化分析:
Patch Embedding Filters: 第一层线性投射层的权重(滤波器)被可视化出来,它们类似于CNN底层学习到的Gabor滤波器和颜色基元,说明ViT确实在学习有意义的低级特征。
位置编码相似度: 可视化位置编码之间的余弦相似度,发现模型自主地学会了图像的2D空间结构。同一行或同一列的patch具有更相似的位置编码。
注意力距离: 模型中的注意力头可以同时关注局部和全局信息。即使在网络的浅层,也有一些头(heads)的“感受野”(attention distance)非常大,覆盖了整个图像,这与CNN逐层扩大感受野的方式完全不同。在网络的深层,几乎所有的头都具有全局注意力。
CLIP: Learning Transferable Visual Models From Natural Language Supervision (2021)
输入:
训练时:大量的(图像,文本)配对数据。
推理时(零样本预测):一张待分类的图像,以及一组描述所有可能类别的文本提示(例如,"A photo of a dog", "A photo of a cat"等)。
输出:
训练时:一个共享的多模态嵌入空间,其中语义相似的图像和文本的特征向量在空间上彼此靠近。
推理时(零样本预测):输入图像的预测类别。这个类别是通过计算图像特征与哪个文本提示特征最相似来确定的。
解决的任务:核心是学习一个通用的、可迁移的视觉-语言联合表示。它最惊艳的应用是解决了 零样本图像分类(Zero-Shot Image Classification) 问题,即模型无需在特定任务的数据上进行微调,就能对任意给定的类别进行分类。这极大地摆脱了对昂贵的人工标注数据集的依赖。
Motivation
在CLIP出现之前,深度学习在计算机视觉领域的主流范式是在大型有标签数据集(如ImageNet)上进行有监督预训练,然后将模型迁移(微调)到下游任务。这种范式虽然成功,但存在几个核心痛点:
高昂的标注成本:像ImageNet这样的数据集需要大量的人工标注,成本极高,且难以扩展到更多、更细粒度的类别。
任务局限性:在ImageNet上预训练的模型,其“知识”被局限在预定义的1000个类别中。对于新任务或新类别,模型通常需要重新收集数据并进行微调,灵活性差。
鲁棒性问题:在标准基准测试中表现出色的模型,在面对真实世界中各种分布变化(如风格、光照、角度变化)时,性能会急剧下降。如论文第13页
Figure 18所示,在ImageNet上提升性能(Adapt to ImageNet)反而可能降低模型在其他分布数据集上的平均鲁棒性。
CLIP的动机就是摆脱对传统“固定标签”的有监督学习的依赖,转而利用互联网上已经大量存在的、带有自然语言描述的图像数据。作者认为,自然语言本身就包含了丰富、灵活、开放的语义信息,可以用来监督视觉模型的学习,从而获得一个更通用、更鲁棒、可以轻松迁移到任意视觉分类任务的模型。
Architecture

CLIP的核心思想是将图像和文本映射到同一个多模态嵌入空间,并通过对比学习拉近匹配的图文对,推远不匹配的图文对。其架构非常简洁,主要包含两个核心组件(如第1页A.2. Models部分描述):
图像编码器 (Image Encoder):
负责将输入的图像转换成一个特征向量。
论文中探索了两种主流架构:
ResNet-50 的变体(
CLIP-RN系列),并通过类似EfficientNet的复合缩放方法,扩展出不同计算量的版本(如RN50x4,RN50x16,RN50x64)。Vision Transformer (ViT)(
CLIP-ViT系列),如ViT-B/32,ViT-B/16,ViT-L/14。
文本编码器 (Text Encoder):
负责将输入的文本(一句话或一个词)转换成一个特征向量。
采用标准的Transformer架构,具体超参数在第25页
Table 19和Table 20中有详细说明(例如,12层,多头注意力机制等)。
训练时,图像和文本编码器同时从头开始训练,没有使用任何预训练权重。它们的目标是学习如何将语义上相关的图像和文本映射到嵌入空间中的相近位置。
核心技术细节
数据集
作者构建了一个名为 WebImageText (WIT) 的庞大数据集。他们从互联网上收集了4亿个(图像,文本)对。这个数据集是CLIP成功的关键,它具备以下特点:
规模巨大:远超ImageNet等传统数据集。
噪声高:文本描述与图像内容不一定完全对应,但巨大的数据量弥补了质量上的不足。
内容多样:覆盖了极其广泛的视觉概念,远不止1000个类别。
训练方法:对比学习 (Contrastive Learning)
CLIP的训练过程是其精髓所在,具体步骤如下:
构建批次 (Batch Construction):在一个训练批次中,随机抽取
N个(图像,文本)对。这样就有了N张图像和N段文本。特征提取:
N张图像通过图像编码器得到N个图像特征向量 I1, I2, ..., IN。N段文本通过文本编码器得到N个文本特征向量 T1, T2, ..., TN。
计算相似度:计算所有可能的图像-文本对的余弦相似度,形成一个
N x N的相似度矩阵。在这个矩阵中,对角线上的元素 (Ii, Ti) 是正样本对(匹配的图文)。
所有非对角线上的元素 (Ii, Tj) 其中
i ≠ j,都是负样本对(不匹配的图文)。
计算损失函数:
损失函数的目标是最大化正样本对的相似度,同时最小化负样本对的相似度。
它是一个对称的交叉熵损失:
对于每一行(每一张图像),模型需要预测其对应的正确文本(在
N个文本中)。对于每一列(每一段文本),模型也需要预测其对应的正确图像(在
N张图像中)。
最终的损失是这两个方向损失的平均值。
这个过程迫使模型学习到一个共享的嵌入空间,在这个空间里,"一只狗的照片"的图像特征会非常接近"a photo of a dog"的文本特征。
核心能力:零样本预测 (Zero-Shot Prediction)
训练完成后,CLIP最惊人的能力是无需微调即可在各种分类任务上进行零样本预测。这个过程巧妙地将传统的分类任务转化为了图文匹配任务(如第9页B. Zero-Shot Analysis所述):
构建文本提示 (Prompt Engineering):对于一个分类任务(比如CIFAR-10),我们不直接使用类别名(如 "dog", "car"),而是将它们构造成有意义的句子,即提示 (Prompt)。例如,使用模板
"A photo of a {label}.",生成 "A photo of a dog.", "A photo of a car." 等。作者发现这种方式能显著提升性能(比直接用标签词提升1.3%)。编码:
给定一张待分类的图像,通过图像编码器得到其特征向量 If。
将所有类别的文本提示,通过文本编码器得到一组文本特征向量 T1, T2, ..., TC(C为类别数)。
预测:
计算图像特征 If 与所有文本特征 T1, ..., TC 的余弦相似度。
相似度最高的那个文本提示所对应的类别,即为模型的预测结果。
这个过程完全不需要使用新任务的任何训练样本,因此被称为“零样本”。
最后更新于