From Diffusion to GSFix3D
@TOC
DDPM: Denoising Diffusion Probabilistic Models (NeurIPS 2020)
输入 (Input):
训练时: 一张真实、清晰的图像 (
x_0)。生成 (推理) 时: 一个从标准高斯分布中采样的纯噪声向量 (
x_T)。
输出 (Output):
一张与训练数据分布相似的、全新的、清晰的图像。
解决的任务 (Task):
无条件图像生成 (Unconditional Image Generation)。该模型学习一个数据集(如人脸、风景)的潜在分布,并从中生成全新的、高质量的样本,而无需任何特定指令。其核心贡献在于证明了扩散模型在图像生成质量上可以媲美甚至超越顶尖的GANs,同时训练过程更稳定。
Motivation
在2020年这篇论文发表之前,深度生成模型领域主要由以下几类模型主导:
生成对抗网络 (GANs): 在图像生成质量上处于绝对领先地位,能够生成非常逼真、高分辨率的图像。但其训练过程非常不稳定,容易出现模式坍塌 (mode collapse),且缺乏直接计算样本似然度的能力。
变分自编码器 (VAEs): 训练稳定,可以计算似然度的下界,但生成的样本通常比较模糊,细节不足。
流模型 (Flow-based Models): 能够精确计算似然度,但模型结构受到可逆性约束,通常在处理高维数据(如高分辨率图像)时表现不如GANs。
自回归模型 (Autoregressive Models): 能够获得非常高的似然度分数,但其串行的生成方式导致采样速度极其缓慢。
扩散模型 (Diffusion Models) 的理论基础在2015年 (Sohl-Dickstein et al.) 就已提出,但一直未受到广泛关注,主要是因为当时其生成样本的质量远不及GANs,且被认为实现和训练复杂。
DDPM这篇论文的核心动机是: 证明经过精心设计和简化的扩散模型,不仅能够克服训练不稳定的问题,还可以在图像生成质量上达到甚至超越顶尖的GANs。作者希望通过建立扩散模型与去噪得分匹配 (denoising score matching) 之间的联系,来简化其训练目标,并最终将其打造为一个强大、稳定且高质量的生成模型框架。
模型核心思想
DDPM将图像生成过程视为一个 逐步去噪 (denoising) 的过程。其核心思想包含两个方向相反的过程:
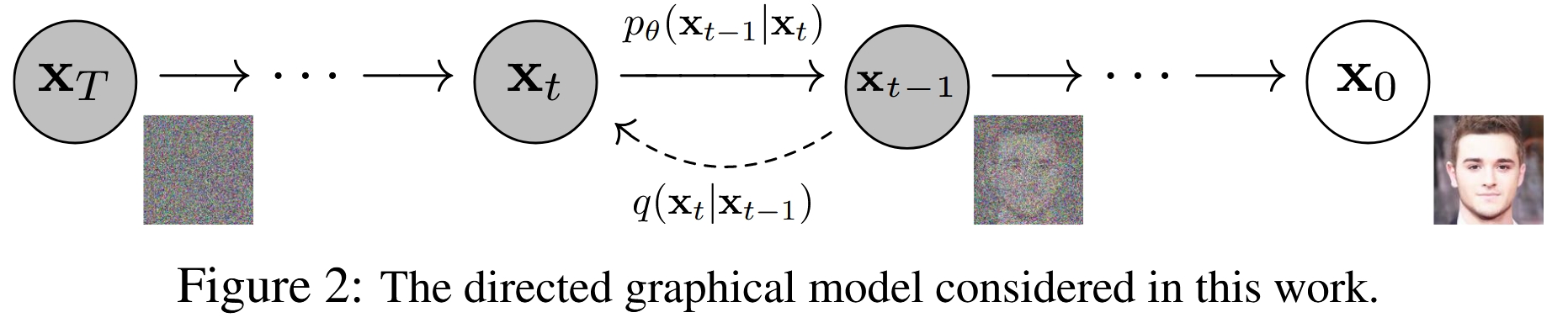
前向过程 (Forward/Diffusion Process): 这是一个固定的、无需学习的马尔可夫链。它从一张真实的、清晰的图像
x_0开始,在T个时间步内,逐步、微量地向图像中添加高斯噪声。每一步添加的噪声量由一个预设的方差表β_t控制。当T足够大时,原始图像x_0最终会变成一个完全符合标准高斯分布的纯噪声图像x_T。这个过程可以看作是对信息的逐步、可控的破坏过程。
反向过程 (Reverse/Denoising Process): 这是模型需要学习的核心部分。它从一个纯噪声
x_T(从标准高斯分布中采样)开始,同样通过一个T步的马尔可夫链,逐步地将噪声去除。在每一步t,一个神经网络会接收当前的噪声图像x_t,并预测出上一步的、稍微干净一点的图像x_{t-1}。经过T步的迭代去噪,模型最终生成一张清晰的图像x_0。这个过程就是生成(采样)过程。
整个模型的训练目标就是让这个学习到的反向过程能够精确地逆转固定的前向过程。
技术细节
前向过程
前向过程的一个关键特性是,我们可以直接从原始图像 x_0 和噪声 ε(ε ~ N(0, I))通过一个闭式解(closed-form solution)得到任意时刻 t 的噪声图像 x_t,而无需迭代计算 t 次。
令 α_t = 1 - β_t 和 α_bar_t = Π_{s=1 to t} α_s,则有:
这个公式至关重要,因为它使得我们可以在训练时随机采样任意一个时间步 t,并直接从 x_0 计算出对应的 x_t,极大地提高了训练效率。
反向过程与损失函数
反向过程的目标是学习一个神经网络 p_θ 来近似真实的后验分布 q(x_{t-1} | x_t)。然而,这个后验分布依赖于 x_0,在生成时 x_0 是未知的。幸运的是,当 x_0 给定时,这个后验分布是可解的:
其中均值 μ_tilde_t 和方差 β_tilde_t 都可以由 β_t 和 α_bar_t 计算得出。
训练的目标是最小化变分下界 (Variational Lower Bound, VLB),经过简化,可以表示为一系列KL散度项的和。其中,最关键的是在每个时间步 t,让模型预测的分布 p_θ(x_{t-1} | x_t) 逼近真实的后验分布 q(x_{t-1} | x_t, x_0)。
核心洞察:从预测图像到预测噪声
直接让神经网络去预测 x_{t-1} 的均值 μ_tilde_t 是可行的,但论文提出了一个更巧妙且效果更好的方法。
通过对 μ_tilde_t 的表达式进行变换,作者发现,预测均值等价于预测在 t 时刻添加到 x_0 上的噪声 ε。具体来说,模型 p_θ(x_{t-1} | x_t) 的均值可以被参数化为:
这里的 ε_θ(x_t, t) 就是一个神经网络,它的输入是噪声图像 x_t 和时间步 t,输出是对原始噪声 ε 的预测。
将这个参数化代入损失函数 L_{t-1} 后,经过一系列化简,损失函数变成了一个非常简洁的形式:
这个损失函数直观地表示:让神经网络 ε_θ 学习去预测它所看到的噪声图像 x_t 中包含的噪声 ε。这本质上是一个 去噪 (denoising) 任务。
简化的训练目标
作者进一步发现,直接使用上面这个简单的均方误差 (MSE) 作为损失函数,并忽略KL散度中的复杂权重项,在实践中能带来更好的样本质量。他们提出了一个最终的简化版训练目标 L_simple:
其中 t 是在 {1, ..., T} 中均匀采样的。这个目标函数非常稳定且易于实现,是这篇论文取得成功的关键之一。
模型架构
网络结构: 论文采用了类似于 PixelCNN++ 的 U-Net 架构。U-Net 的结构非常适合图像到图像的转换任务,其编码器-解码器结构和跳跃连接 (skip connections) 能够很好地保留多尺度的空间信息,这对于去噪任务至关重要。
时间编码: 由于同一个网络需要处理所有时间步
t(从1到T) 的去噪任务,模型需要知道当前处理的是哪个时间步。作者借鉴了 Transformer 中的 正弦位置编码 (sinusoidal position embedding) ,将时间步t转换为一个向量,并将其加入到U-Net的每个残差块中。注意力机制: 在U-Net的低分辨率特征图部分(例如16x16),加入了自注意力 (self-attention) 模块,以帮助模型捕捉全局依赖关系。
实验与结果
SOTA 样本质量: 在无条件 CIFAR10 数据集上,DDPM 取得了 3.17 的 FID 分数 ,在当时超过了绝大多数已发表的GAN模型,首次证明了扩散模型在图像质量上的强大竞争力。
高质量大图生成: 在 256x256 分辨率的 CelebA-HQ 和 LSUN 数据集上,生成的样本质量与当时的顶尖GAN模型 (如ProgressiveGAN) 相当,展示了其良好的可扩展性。
渐进式生成 (Progressive Generation): 论文展示了在采样过程中,模型首先生成图像的粗略轮廓和结构,然后逐步添加细节,这个过程非常有趣,类似于人类绘画。
良好的插值效果: 在隐空间中对两个样本进行插值,可以得到平滑且语义合理的过渡图像。
贡献与影响
DDPM 是深度生成模型发展史上的里程碑式工作,其主要贡献和影响如下:
确立了扩散模型的SOTA地位: 它用无可辩驳的实验结果证明,扩散模型是一种可以生成高质量样本的顶级生成模型,直接引发了后续对扩散模型的研究热潮。
简化了模型设计与训练: 提出了"预测噪声"的参数化方法和
L_simple这一极其简洁有效的训练目标,大大降低了扩散模型的实现门槛,并提高了训练的稳定性和最终效果。建立了与去噪得分匹配的桥梁: 揭示了扩散模型与去噪自编码器、得分匹配和 Langevin 动力学之间的深刻联系,统一了不同领域的思想,为后续的理论创新提供了基础。
开启了新时代: DDPM 的成功直接催生了后续一系列著名的生成模型,如 GLIDE, DALL-E 2, Imagen, 和 Stable Diffusion 等,这些模型大多都基于 DDPM 提出的核心框架进行改进和扩展,彻底改变了AI生成内容(AIGC)领域的格局。
总而言之,DDPM通过巧妙的重新参数化和目标函数简化,将一个理论上优雅但实践中效果不佳的模型类别,成功地转变为一个强大、稳定且效果顶尖的生成框架,为整个领域的发展奠定了坚实的基础。
Diffusion Models Beat GANs on Image Synthesis (NeurIPS 2021)
这篇文章是扩散模型发展历程中的一篇里程碑式的工作,它首次证明了扩散模型在主流图像生成基准上能够超越当时最先进的GAN模型。
输入 (Input):
一个纯噪声向量。
一个目标类别标签 (e.g., '猫', '狗')。
一个引导尺度 (guidance scale)
s,用于控制生成效果。
输出 (Output):
一张清晰的、明确属于输入目标类别的图像。
解决的任务 (Task):
有条件图像生成 (Conditional Image Generation),并实现了保真度-多样性的权衡。通过引入一个在带噪图像上训练的分类器来“引导”生成过程,该模型可以生成特定类别的、质量极高的图像,首次在主流基准上全面超越了GANs。
Motivation
在本文发表之前,生成对抗网络(GANs)是图像生成领域的绝对王者,尤其以StyleGAN和BigGAN为代表的模型,在生成高保真度、高分辨率图像方面取得了SOTA(State-of-the-Art)的成果。然而,GANs也存在一些固有的问题:
训练不稳定:GANs的训练是一个寻找纳什均衡的对抗过程,非常脆弱,容易出现模式崩溃(mode collapse),导致生成样本多样性差。
多样性不足:即使训练成功,GANs也常常无法完整地覆盖整个数据分布,其生成样本的多样性通常不如基于似然的模型(likelihood-based models)。
与此同时,扩散模型(Diffusion Models)作为一种基于似然的模型,展现出了一些优良特性:
训练稳定:其训练目标是固定的,不涉及对抗训练,因此训练过程非常稳定。
高多样性:作为似然模型,它天然地倾向于学习完整的数据分布,生成样本的多样性很好。
然而,在当时,扩散模型在 样本质量(保真度) 上仍然落后于顶级的GANs,并且其 采样速度非常慢 。
作者们认为,扩散模型与GANs之间的性能差距主要源于两个因素:
模型架构:GAN的生成器架构(如StyleGAN的风格化网络)经过了大量研究和精细调优,而扩散模型普遍使用的UNet架构相对来说还有很大的探索和改进空间。
多样性与保真度的权衡(Diversity-Fidelity Trade-off):GANs可以通过一些技巧(如BigGAN的“截断技巧”,truncation trick)来牺牲一部分样本多样性,从而换取更高的样本保真度。而当时的扩散模型缺乏一个类似且有效的机制。
因此,本文的核心动机就是解决这两个问题,通过 改进模型架构和 引入一种新的引导机制,来证明扩散模型不仅能追上,甚至可以超越GANs。
模型架构改进 (Ablated Diffusion Model - ADM)
作者首先对扩散模型的基础架构——UNet进行了一系列的消融实验,以找到最优的配置。他们将改进后的模型称为 ADM (Ablated Diffusion Model)。主要改进点包括:
模型宽度与深度:在固定模型总参数量的情况下,作者发现 增加模型宽度(更多的通道数) 比增加模型深度(更多的残差块)能带来更好的性能和更快的收敛速度。
注意力机制:
增加注意力头数:将注意力机制从单头变为多头(类似Transformer),并发现每个头分配64个通道时效果最好。
在多分辨率上使用注意力:原始的DDPM只在16x16分辨率的特征图上使用注意力。作者发现,在 多个分辨率(如32x32, 16x16, 8x8) 上都使用注意力机制能显著提升模型性能。
Up/Downsampling模块:采用了BigGAN中使用的残差块进行上采样和下采样,这比标准的卷积效果更好。
自适应组归一化 (Adaptive Group Normalization - AdaGN) :这是一个关键的改进。在每个残差块中,模型不再是简单地将时间步(timestep)和类别(class)的嵌入向量加到特征图上,而是利用这个嵌入向量去 预测组归一化(Group Normalization)层的缩放(scale)和偏置(shift)参数。这种方式借鉴了StyleGAN中的AdaIN,使得条件信息(时间和类别)能更有效地控制生成过程。
通过这些架构上的改进,ADM模型在无条件生成任务上(如LSUN数据集)已经能够取得超越StyleGAN2的FID分数。
核心技术:分类器引导 (Classifier Guidance)
这是本文最核心、最具影响力的技术贡献,它为扩散模型提供了一个强大的 多样性-保真度权衡机制。
- 基本思想
在扩散模型的反向去噪过程中,每一步都是从一个较噪声的图像 x_t 预测一个稍干净的图像 x_{t-1}。分类器引导的思想是,在这个预测过程中,不仅依赖扩散模型本身学到的分布 p(x_t|x_{t-1}),还要利用一个 外部的图像分类器 p(y|x_t) 来“引导”生成方向。
具体来说,我们希望生成的样本不仅看起来真实,而且还要明确地属于目标类别 y。分类器可以判断当前的噪声图像 x_t 有多像类别 y,并提供一个梯度信号,告诉模型应该如何调整才能让它“更像”类别 y。
- 技术细节
反向去噪过程的目标是建模条件分布 p(x_{t-1} | x_t, y)。根据贝叶斯定理,这个分布正比于 p(x_{t-1} | x_t) * p(y | x_{t-1}, x_t)。作者将其近似为:
取对数后,条件分布的对数似然是无条件模型和分类器对数似然的和。在采样时,这意味着我们可以通过调整去噪步骤的均值来实现引导。
原始的去噪步骤是从一个均值为 μ,方差为 Σ 的高斯分布中采样。经过引导后,新的均值 μ_guided 变为:
其中:
μ(x_t)是原始扩散模型预测的均值。∇(x_t) log p(y|x_t)是 分类器对数似然关于输入噪声图像x_t的梯度。这个梯度指向了能让分类器最大化地将x_t识别为类别y的方向。s是 引导尺度(guidance scale),一个超参数。s=0时,没有引导。s>1时,会放大分类器的引导效果,迫使模型生成在分类器看来“极其典型”的样本。这会提升保真度(fidelity)但降低多样性(diversity) 。
分类器训练
需要注意的是,这个用于引导的分类器 p(y|x_t) 必须在 加了噪声的图像 上进行训练,这样它才能在去噪过程的任意时间步 t 对噪声图像 x_t 做出准确的判断和引导。
实验结果
作者在多个标准数据集上验证了他们的方法,并取得了突破性成果。
超越GANs:在ImageNet 128x128分辨率上,ADM-G(带引导的ADM)取得了FID 2.97的惊人成绩,远超当时BigGAN-deep的最好结果。在256x256和512x512分辨率上也同样刷新了SOTA记录。
权衡曲线更优:与BigGAN的截断技巧相比,分类器引导在多样性-保真度的权衡上表现得更出色,即在相同的保真度下能实现更高的多样性。
采样速度:虽然采样仍然比GAN慢,但作者展示了使用DDIM采样器,仅需25个采样步骤就能达到与Big-GAN相当的FID,大大缓解了采样慢的问题。
引导与上采样的结合:作者发现,分类器引导和多阶段上采样是两种互补的技术。 引导主要提升精度(Precision),而上采样擅长保持多样性(Recall)。将两者结合——在低分辨率模型上使用引导,然后用上采样模型放大到高分辨率——可以得到 最佳的生成效果 (如ImageNet 512x512上FID达到3.85)。
总结与影响
这篇论文是扩散模型发展的一个转折点。它通过系统性的架构改进和创新的分类器引导技术,解决了扩散模型长期以来在样本质量上不如GANs的问题。
主要贡献:
提出了一套优化的扩散模型架构(ADM),使其在无条件生成任务上达到SOTA。
发明了分类器引导技术,为扩散模型提供了强大的多样性-保真度控制能力,使其在条件生成任务上全面超越GANs。
深远影响:
它确立了扩散模型作为顶级生成模型的地位,引发了后续研究的热潮。
“引导”这一思想被后续工作发扬光大。例如,OpenAI后续的DALL-E 2和Google的Imagen等模型,都采用了 “无分类器引导”(Classifier-Free Guidance) 技术。该技术是本文思想的直接演进,它不再需要一个独立的分类器,而是通过在训练时以一定概率丢弃条件信息,让模型自身同时学习条件和无条件分布,从而在采样时进行自我引导。这使得引导机制变得更加通用和强大,并成为现代文生图模型的标配。
Classifier-Free Diffusion Guidance (NeurIPS 2021 Workshop)
DDPM 只能生成无条件的样本。但在机器人导航中,策略必须是有条件的(例如,以目标图像为条件)。这篇论文提出了一种非常有效且流行的方法,让扩散模型能够根据条件生成样本,而无需额外训练一个分类器。这篇文章是扩散模型发展史上的一个里程碑,它提出了一种高效、简洁且强大的方法来控制生成样本的质量和多样性,并已成为后续所有大规模条件扩散模型(如DALL-E 2, Imagen, Stable Diffusion)的标准技术。
输入 (Input):
一个纯噪声向量。
一个条件信息
c(例如,类别标签或文本描述)。一个引导强度
w。
输出 (Output):
一张与输入条件
c相符的高质量图像。
解决的任务 (Task):
简化版的有条件图像生成。它解决了上一篇工作中需要额外训练一个分类器的问题。通过在训练时以一定概率随机丢弃条件信息,让单个模型同时学会条件生成和无条件生成。在推理时,通过组合这两种预测,实现了无需分类器的“引导”,该技术已成为现代文生图模型的标配。
Summary
本文提出了一种在条件扩散模型中,无需额外训练一个分类器,即可实现“引导(Guidance)”的技术。该技术能够像之前的“分类器引导”方法一样,有效地在生成样本的保真度(Fidelity/Quality)和多样性(Diversity)之间进行权衡。作者通过在一个模型中联合训练一个条件扩散模型和一个无条件扩散模型,并在采样时将两者的分数估计(score estimates)进行线性组合,从而实现了这一目标。这种方法不仅简化了训练流程,也证明了纯粹的生成模型自身就有能力实现高质量的引导生成,而无需依赖外部模型的梯度。
Motivation
在本文之前,Dhariwal & Nichol (2021) 在他们的论文《Diffusion Models Beat GANs on Image Synthesis》中提出了 分类器引导(Classifier Guidance) 技术。这项技术极大地提升了扩散模型生成样本的质量,使其在ImageNet生成任务上首次超越了顶级的GAN模型。
分类器引导的核心思想是:在扩散模型的每一步去噪过程中,不仅使用扩散模型自身预测的噪声,还额外利用一个在带噪图片上训练好的分类器,计算出指向“目标类别”概率增加最快的梯度方向,然后将这个梯度“添加”到去噪方向上,从而“引导”生成过程向着目标类别更明确、特征更显著的方向进行。
然而,分类器引导存在以下几个核心问题,这也是本文的主要动机:
额外的模型和训练成本:需要单独训练一个分类器。更麻烦的是,这个分类器必须能在不同噪声水平的图片上进行准确分类,这意味着它需要在扩散过程中的所有中间带噪样本
z_t上进行训练,这大大增加了训练的复杂性和成本。你不能简单地拿一个在干净图片上预训练好的分类器来用。对“引导”本质的质疑:分类器引导的采样过程,可以被看作是利用分类器的梯度来“攻击”生成样本,使其在分类器眼中看起来更像目标类别。这引出了一个问题:这种方法提升的基于分类器的评估指标(如Inception Score, FID),究竟是因为生成质量真的提高了,还是因为它本质上是一种针对评估系统的“对抗性攻击”?
简化流程的需求:研究者们希望找到一种更“纯粹”、更内生的方法。是否可以不依赖任何外部模型,仅凭扩散模型自身就完成高质量的引导?
因此,本文的目标就是摆脱分类,设计一种分类器无关的引导方法,来解决上述所有问题。
背景知识:扩散模型与分类器引导
要理解本文,首先需要了解两个关键背景。
扩散模型基础
扩散模型通过两个过程进行建模:
前向过程(Forward Process):从一张干净的图片
x_0开始,逐步、多次地向其中添加高斯噪声,直到图片变成纯粹的噪声x_T。这个过程的每一步都是一个固定的、可计算的马尔可夫链。反向过程(Reverse Process):模型学习如何“逆转”这个加噪过程。从纯噪声
x_T出发,模型在每一步预测出应该如何去噪,从而逐步恢复出原始的、干净的图片x_0。
在实践中,模型(通常是一个U-Net架构)在任意时间步 t 接收带噪样本 x_t 和时间步 t 的编码,其任务是预测出添加到 x_0 中以得到 x_t 的原始噪声 ε。这个预测出的噪声我们记为 ε_θ(x_t, t)。对于条件生成,模型还会接收一个条件信息 c(如类别标签),即 ε_θ(x_t, c, t)。
分类器引导 (Classifier Guidance)
分类器引导在采样(反向过程)时修改了模型的预测。原本的预测分数(score,与噪声 ε 成正比)是 ε_θ(x_t, c)。分类器引导将其修改为:
这里:
是条件扩散模型的原始噪声预测。
是在带噪图片 x_t 上训练的分类器模型,表示 x_t 属于类别 c 的概率。
是该概率的对数关于输入 x_t 的梯度。这个梯度指向了能让分类器更确信 x_t 属于类别 c 的方向。
w是引导强度(guidance scale/strength),控制着分类器梯度的影响大小。w=0 时即为无引导。
这个公式的直观解释是:在扩散模型原本的去噪方向上,额外叠加一个“让样本更像类别 c”的力。
分类器无关引导 (Classifier-Free Guidance)
这是本文的核心贡献。作者巧妙地利用贝叶斯定理,从数学上推导出了一个等效于分类器引导但不需要分类器的形式。

核心思想与推导
分类器引导的核心是梯度项 ∇ log p(c|x_t)。根据贝叶斯定理:
取对数后得到:
对 x_t 求梯度,log p(c) 是常数项,可以忽略:
这里的关键洞察在于:
∇_{x_t} \log p(x_t|c)正是条件扩散模型要学习的分数(score)。∇_{x_t} \log p(x_t)正是无条件扩散模型要学习的分数。
将这个关系代入分类器引导的公式:
因此,作者提出,我们可以直接训练一个条件模型 ε_θ(x_t, c) 和一个无条件模型 ε_θ(x_t),然后在采样时将它们的预测结果进行组合。
训练细节
如何高效地同时训练条件和无条件模型?作者提出了一个极为简洁的方案,也是该方法广受欢迎的原因之一:
使用单一模型,随机丢弃条件:在训练一个条件扩散模型
ε_θ(x_t, c)时,以一定的概率p_uncond(例如10%或20%)将条件c替换为一个特殊的空标签(null token, 记作 Ø)。当输入为
(x_t, c)时,模型学习的是条件去噪。当输入为
(x_t, Ø)时,模型学习的是无条件去噪。
这样,同一个神经网络 ε_θ 就同时学会了两种能力,而无需增加任何模型参数或复杂的训练流程。这在代码上只是一个简单的随机替换操作。
采样过程
在采样时,每一步都需要进行两次模型前向传播:
一次使用目标条件
c,得到条件预测ε_θ(x_t, c)。一次使用空标签
Ø,得到无条件预测ε_θ(x_t, Ø)。
然后,根据以下公式计算最终的引导后噪声预测:
其中 w 依然是引导强度。这个公式也可以写成更直观的形式:
这个形式的直观解释是:
ε_θ(x_t, Ø)是无条件的预测,代表了生成通用、自然图像的方向。(ε_θ(x_t, c) - ε_θ(x_t, Ø))是条件和无条件预测的差值,可以看作是“从通用图像转向特定类别c”的方向向量。(w+1)控制着向特定类别c靠拢的强度。当w=0时,公式变为ε_θ(x_t, c),即标准的条件生成。注意,本文的公式w从0开始,当w>0时即有引导效果。
通过调整 w,就可以在高质量、低多样性(w 较大)和高多样性、较低质量(w 较小)之间平滑过渡。
实验与结果
IS/FID 权衡曲线:论文在ImageNet 64x64和128x128数据集上进行了实验。结果显示,随着引导强度
w的增加,Inception Score (IS) 显著提高,而FID分数先下降后上升,呈现出经典的“质量-多样性”权衡曲线。这证明了分类器无关引导成功复现了分类器引导的效果。SOTA 性能:在128x128 ImageNet上,该方法取得了当时最先进的(SOTA)结果,其FID分数优于之前的分类器引导方法(ADM-G),并在高引导强度下,IS和FID同时优于BigGAN-deep的最佳IS点。
p_uncond的影响:实验发现,p_uncond取一个较小的值(如0.1或0.2)就足够了。这表明模型不需要花费大量能力去学习无条件生成,就可以提供有效的引导信号。采样步数的影响:和所有扩散模型一样,增加采样步数
T可以提升生成质量,但会增加时间成本。作者发现T=256步就能在速度和质量上取得很好的平衡。
讨论与影响
优点:
简洁性:训练和实现都非常简单,只需在训练时随机丢弃条件即可。
纯粹性:完全摆脱了对外部模型的依赖,证明了扩散模型自身能力的强大。
消除了“对抗性”的疑虑:性能的提升来自于生成模型内部的调整,而非针对外部评估系统的优化。
缺点:
采样速度:由于每一步都需要两次前向传播,采样时间大约是无引导或分类器引导(如果分类器很小)的两倍。这是该方法最主要的代价。
深远影响: 分类器无关引导(Classifier-Free Guidance, CFG)几乎立即成为了条件扩散模型领域的黄金标准。从文本到图像生成的DALL-E 2, Imagen, Stable Diffusion,到各种其他条件的生成任务,CFG都是核心组件之一。它极大地推动了扩散模型在实际应用中的落地和发展,因为它提供了一个可靠、易用且效果拔群的控制旋钮。
LDM: High-Resolution Image Synthesis with Latent Diffusion Models (CVPR 2022)
输入 (Input):
初始的随机噪声 (在潜在空间中)。
一个灵活的条件信号 (conditioning signal),可以是以下多种形式之一:
文本提示 (Text Prompts)
语义布局图 (Semantic Layouts)
类别标签 (Class Labels)
低分辨率图像 (用于超分任务)
带掩码的图像 (用于图像修复任务)
输出 (Output):
一张与输入条件语义对齐的高分辨率图像。
解决的任务 (Task):
高效、高质量的高分辨率图像生成。这篇论文的核心是解决传统扩散模型 (Diffusion Models) 在高维像素空间中直接操作所导致的巨大计算成本和缓慢推理速度的问题。
它通过一个两阶段框架实现了这一目标:
首先,使用一个自编码器将图像压缩到一个低维、信息丰富的潜在空间 (Latent Space)。
然后,在这个计算量极小的潜在空间中执行计算密集的扩散和去噪过程。
这种“潜在扩散”方法在大幅降低计算需求的同时,保持了极高的生成质量,并借助跨注意力机制 (Cross-Attention) 成为一个适用于多种条件生成任务的通用框架。
Motivation
在本文提出之前,主流的高分辨率图像生成模型主要有三类,但它们各自都存在明显的局限性:
GANs (生成对抗网络):生成速度快,图像真实感强。但训练过程不稳定,容易出现模式崩塌(mode collapse),导致生成样本的多样性不足,并且难以捕捉复杂的数据分布。
Autoregressive Models (自回归模型):如 VQ-VAE + Transformer,能够生成高质量和多样性的图像。但其推理过程是逐像素生成的,速度极慢,计算成本高昂。为了使其在可接受的时间内运行,通常需要对图像进行高倍率的压缩,这又会导致图像细节的损失。
Diffusion Models (扩散模型, DMs):当时在图像生成质量上达到了SOTA(state-of-the-art)水平,能够生成多样性极佳的样本。然而,其核心问题在于计算成本过高。扩散模型直接在 像素空间(pixel space) 上进行反复的去噪操作,这个过程涉及数百甚至上千步。由于高分辨率图像的像素空间维度巨大(例如 256x256x3),导致:
训练成本极高:训练一个强大的扩散模型通常需要数百个GPU天。
推理速度极慢:生成一张图像需要对一个庞大的神经网络进行上千次顺序评估,非常耗时。
论文作者敏锐地指出,扩散模型在像素空间上操作,其实浪费了大量的计算资源在建模人眼几乎无法感知的高频细节上。他们将模型的学习过程分为两个阶段(见论文图2):
感知压缩 (Perceptual Compression):去除图像中冗余的高频信息,这些信息对图像的语义内容影响不大。
语义压缩 (Semantic Compression):学习图像的核心语义和概念构成。
传统扩散模型将这两个过程混在一起,在巨大的像素空间上同时进行,导致效率低下。因此,本文的核心动机是:将扩散模型从高维度的像素空间解放出来,让它在一个低维度的、但信息丰富的潜在空间 (latent space) 中进行训练和生成,从而在保持高质量的同时,极大地提升效率。
模型架构 (Model Architecture)
为了实现上述动机,作者提出了Latent Diffusion Model (LDM),其架构是一个清晰的两阶段模型:
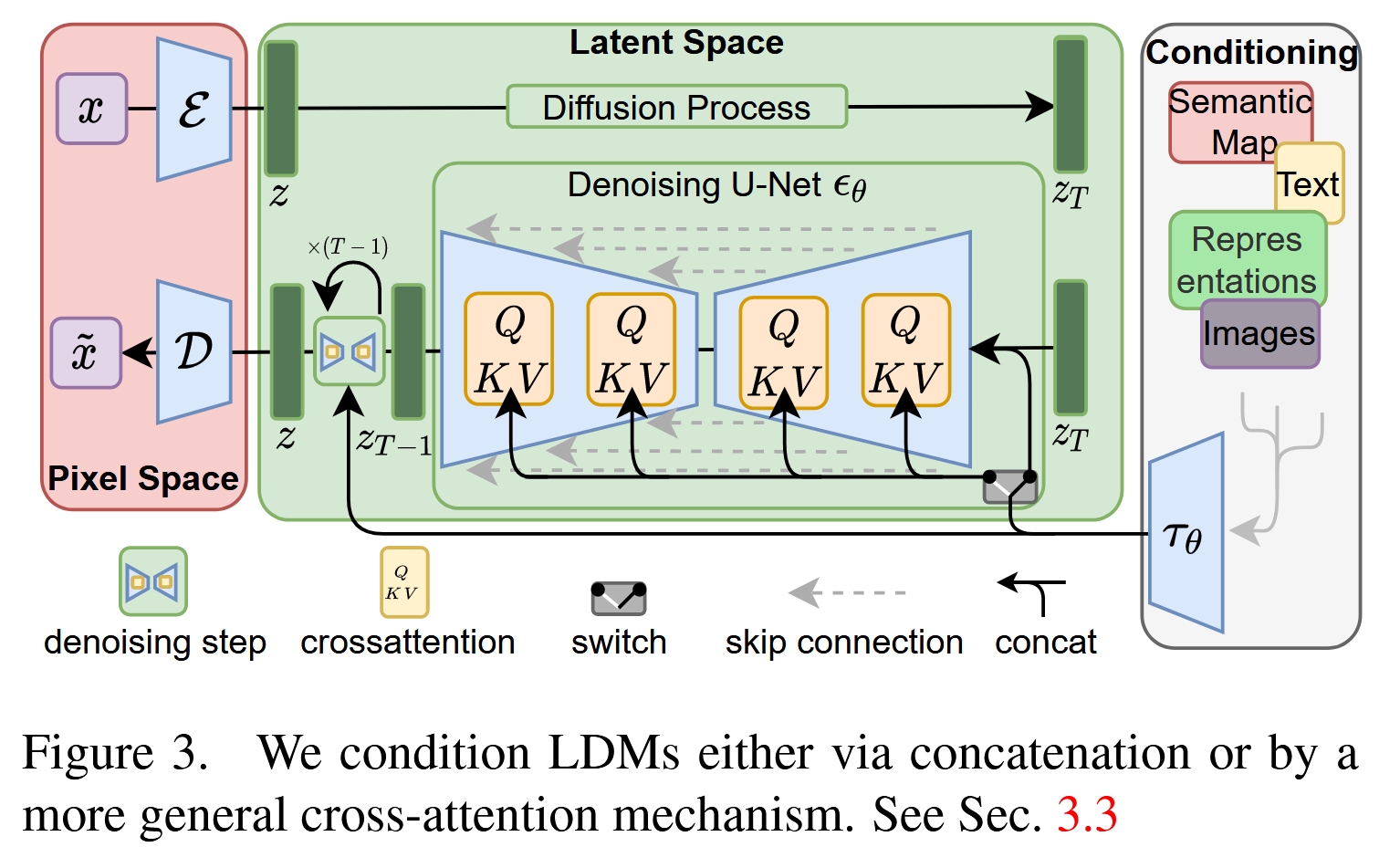
第一阶段:感知压缩模型 (Perceptual Compression Model)
这一阶段的目标是训练一个强大的自编码器 (Autoencoder),它负责将图像在像素空间和潜在空间之间进行转换。
编码器 (Encoder) E:将输入的高分辨率图像
x压缩成一个低维度的潜在表示z = E(x)。例如,一张 256x256x3 的图像,经过一个下采样因子f=8的编码器后,会变成一个 32x32x4 的潜在特征图z。解码器 (Decoder) D:接收潜在表示
z,并将其重建回原始像素空间的图像x' = D(z)。
这个自编码器并非普通的自编码器。为了确保重建的图像 x' 具有丰富的细节和高真实感,而不是模糊的平均图像,作者采用了以下技术进行训练:
感知损失 (Perceptual Loss):比较原图和重建图像在深度神经网络(如VGG)中的特征差异,使得重建图像在感知上更接近原图。
基于 Patch 的对抗性损失 (Patch-based Adversarial Loss):引入一个判别器来判断图像的每个小块(patch)是否真实,这能有效提升图像的局部真实感和纹理细节。
正则化:为了防止潜在空间的方差过大,作者引入了两种正则化方法:一种是类似VAE的KL散度正则化,另一种是类似VQ-GAN的矢量量化(VQ)正则化。这使得潜在空间更加规整,便于后续扩散模型的学习。
关键点:这个自编码器只需要训练一次。训练完成后,它的编码器和解码器权重就被冻结。之后,它可以被复用于训练各种不同任务的扩散模型,极大地提高了复用性和效率。
第二阶段:潜在扩散模型 (Latent Diffusion Model)
这是模型的核心生成部分。与传统扩散模型在像素 x 上操作不同,LDM 完全在第一阶段学到的潜在空间 z 上进行操作。
扩散过程 (Forward Process):与标准扩散模型一样,这是一个固定的过程。它在
T步内,逐渐向从编码器得到的潜在表示z中添加高斯噪声,直到z_T变成一个纯粹的标准正态分布噪声。去噪过程 (Reverse Process):这是模型需要学习的部分。它使用一个神经网络(通常是 U-Net 架构)来预测每一步添加的噪声。这个 U-Net 的输入是带有噪声的潜在表示
z_t和当前的时间步t,输出是对噪声的预测ε_θ(z_t, t)。
模型的训练目标是最小化预测噪声与真实噪声之间的差异:
优势:由于 z 的维度远小于 x(例如,空间维度降低了 f^2 倍),U-Net 的计算量大幅下降,使得训练和推理过程都变得非常高效。
图像生成:从一个随机的高斯噪声
z_T开始,利用训练好的 U-Net 逐步去噪,得到一个干净的潜在表示z_0。最后,将z_0输入到第一阶段训练好的解码器 D 中,只需一次前向传播,即可得到一张高分辨率的生成图像x'。
跨注意力条件注入机制 (Cross-Attention Conditioning)
这是 LDM 能够处理多模态任务(如文本生成图像)的核心技术,也是其成功的关键之一。传统的条件生成模型通常通过简单的拼接(concatenation)方式将条件信息(如类别标签)输入到 U-Net 中,这种方式功能有限且不够灵活。
LDM 采用了一种更强大的跨注意力机制来注入条件信息 y(例如文本、语义图等):
领域特定的编码器 (Domain-specific Encoder) τ_θ:首先,使用一个预训练好的、针对特定领域的编码器来处理条件输入
y。例如:对于文本条件 (Text-to-Image),使用一个 Transformer 模型(如 CLIP Text Encoder 或 BERT)将文本
y编码成一系列词向量τ_θ(y)。对于语义图条件 (Layout-to-Image),可以使用卷积网络。
注入 U-Net:将编码后的条件表示
τ_θ(y)通过跨注意力层注入到 U-Net 的多个中间层中。具体来说:U-Net 中间层的特征图
φ_i(z_t)作为注意力机制的 Query (Q)。条件表示
τ_θ(y)作为 Key (K) 和 Value (V)。
注意力计算公式如下:
这种机制允许 U-Net 在生成图像的不同空间位置时,能够“关注”到条件信息(如文本提示)中的最相关部分。例如,在生成“一只猫坐在垫子上”的图像时,模型在绘制猫的区域会更关注“猫”这个词的特征,在绘制垫子时则更关注“垫子”的特征。
这种灵活的机制使得 LDM 可以轻松地扩展到各种条件生成任务,如文本生成图像、布局生成图像、图像修复(inpainting)、超分辨率等,而无需对核心架构做大的改动。
总结与优势
Latent Diffusion Model 通过一个巧妙的两阶段设计,成功地解决了传统扩散模型效率低下的核心痛点,其主要优势可以总结为:
高效率:通过在低维潜在空间进行扩散过程,极大地降低了训练和推理的计算成本,使得在消费级 GPU 上进行高分辨率图像生成成为可能,真正实现了“民主化”。
高质量:由于第一阶段的自编码器被训练用来保留所有重要的感知信息,LDM 可以在不牺牲太多图像细节的情况下进行生成,质量与像素空间的扩散模型相当甚至更好。
高灵活性:基于跨注意力的条件机制是一个通用且强大的框架,使 LDM 能够轻松适应各种输入模态和生成任务,成为一个通用的条件图像生成器。
总而言之,LDM 在效率、质量和灵活性之间找到了一个绝佳的平衡点,为后续的 Stable Diffusion 等一系列强大的生成模型奠定了坚实的基础。
ControlNet: Adding Conditional Control to Text-to-Image Diffusion Models (ICCV 2023)
ControlNet是一种神经网络架构,旨在为预训练的大型文本到图像扩散模型(如Stable Diffusion)增加额外的、精细化的空间条件控制。在ControlNet出现之前,用户主要通过文本提示(prompt)来指导图像生成,但这很难精确控制图像中物体的姿态、构图、形状或布局。ControlNet通过引入一种高效的训练策略,允许用户使用如边缘图、人体姿态骨架、深度图、分割图等条件图像来精确指导生成过程,同时完整保留了原始预训练模型的强大生成能力和高质量的图像输出。
输入 (Input):
一个文本提示 (Text Prompt),描述图像的内容和风格。
一个条件控制图像 (Conditional Image),用于提供精确的空间约束,例如Canny边缘图、人体姿态骨架、深度图、分割图或用户涂鸦等。
输出 (Output):
一张高质量图像。这张图像在内容上匹配文本提示,同时其空间结构(如构图、物体姿态、轮廓)严格遵循条件控制图像的指导。
解决的任务 (Task):
为大型文生图模型提供精细化的空间控制。它解决了仅靠文本提示无法精确控制生成图像中物体姿态、形状和布局的难题。
核心贡献是提出了一种高效的训练策略,能够在不损害或重新训练庞大的预训练模型的前提下,为其添加多种新的、可控的生成条件,从而极大地扩展了AI绘画的实用性和可控性。
Motivation
文本提示的局限性: 尽管文本到图像模型取得了巨大成功,但仅靠语言描述来传达复杂的空间信息是困难且模糊的。例如,要精确描述一个特定的人物姿势、复杂的室内布局或独特的建筑轮廓,往往需要用户反复尝试和修改提示词,这个过程被称为“提示工程(prompt engineering)”,效率低下且结果不可控。
精确空间控制的需求: 无论是专业设计师还是普通用户,都希望能够更直接、更精确地控制生成图像的构图。例如,用户可能想根据一张草图生成一张完整的插画,或者根据一个3D模型渲染的深度图生成一张具有真实感的照片,或者让生成的人物完全符合指定的姿态。这些任务都需要模型能够理解并遵循除了文本之外的、更具空间性的指导信号。
直接微调(Finetuning)的挑战: 一个看似直接的方法是在新的条件数据上微调整个预训练模型。然而,这种方法面临两大挑战:
灾难性遗忘(Catastrophic Forgetting): 像Stable Diffusion这样的大模型是在数十亿张图片上训练得到的,拥有非常泛化和强大的图像先验知识。如果在规模小得多的特定任务数据集(例如,只有几十万张的姿态-图像对)上直接微调,模型很容易过拟合新任务,从而忘记原有的通用生成能力,导致生成图像的质量和多样性急剧下降。
数据和计算成本高昂: 针对特定条件的成对数据集(如深度图-真实图)通常比训练基础模型所用的通用数据集小几个数量级。即使如此,微调整个大模型仍然需要巨大的计算资源和时间。
因此,ControlNet的核心动机在于:如何在不损害原始大模型性能的前提下,高效、稳健地为其添加新的条件控制能力,即使在小规模数据集上训练也能取得良好效果。
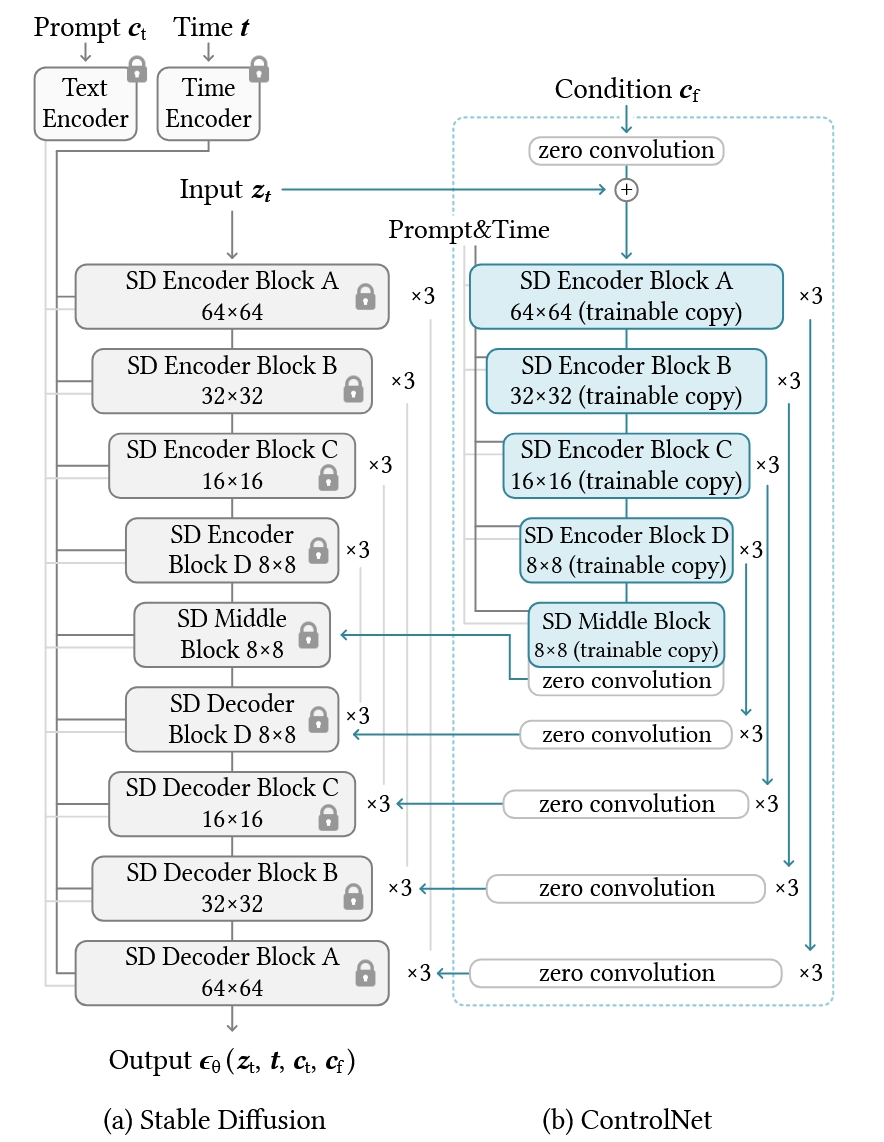
Architecture
ControlNet的架构设计非常巧妙,其核心思想不是修改原始模型,而是在其之上“嫁接”一个可训练的分支。它作用于Stable Diffusion的U-Net部分。
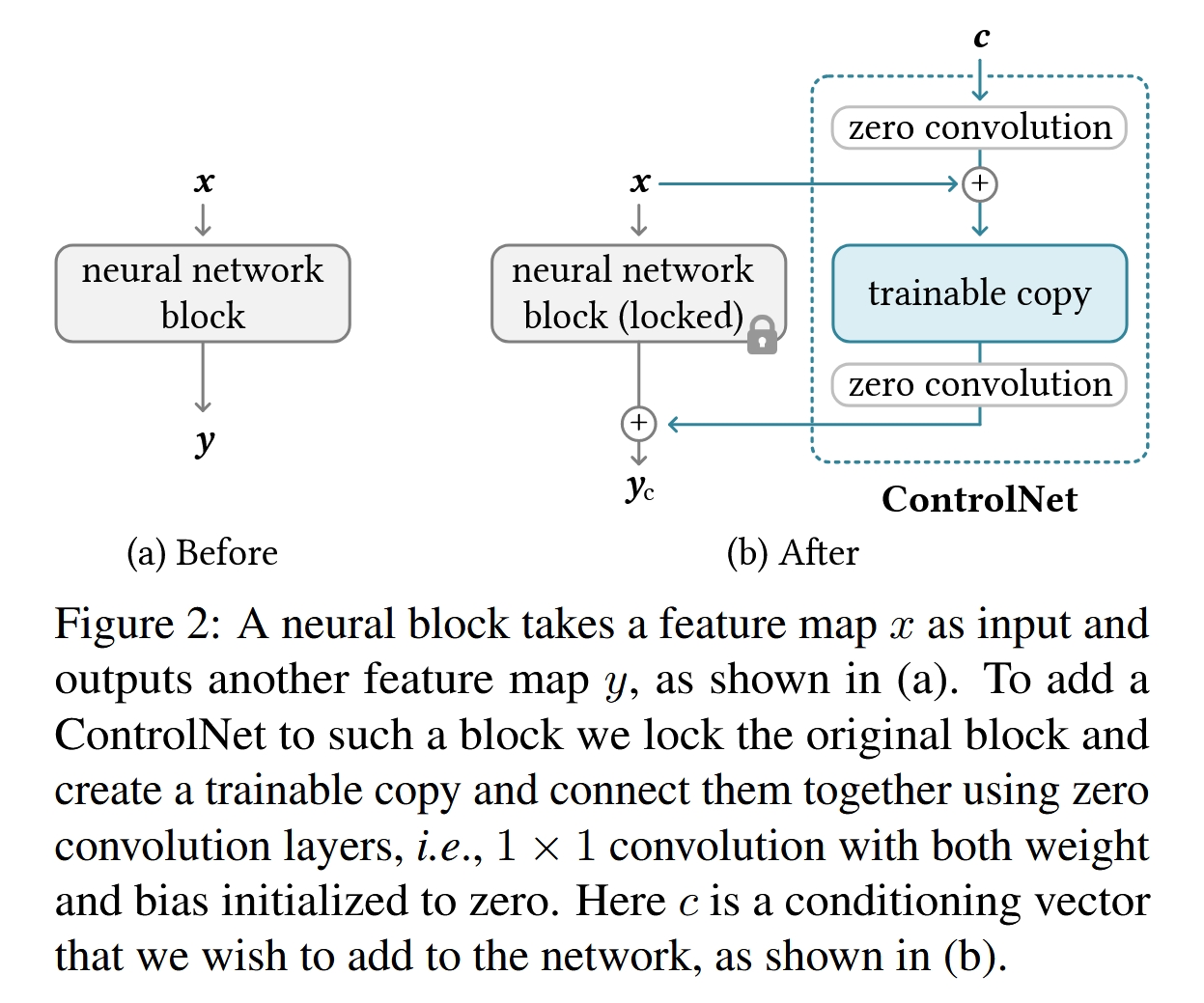
锁定与复制(Lock & Copy):
锁定原始模型: ControlNet首先将预训练的扩散模型(论文中以Stable Diffusion为例)的全部权重锁定(freeze),使其在训练过程中不参与梯度更新。这确保了模型数十亿图像中学到的丰富知识被完整保留,不会在训练新条件时被破坏。
创建可训练副本: 随后,ControlNet创建了原始模型U-Net编码器部分和中间块(Middle Block)的可训练副本。这个副本的权重由原始模型的权重初始化,这意味着它从一个非常强大的起点开始学习,而不是从零开始。这个副本将负责学习如何理解新的条件输入。
零卷积层(Zero Convolution Layers): 这是ControlNet架构设计的关键和精髓所在。零卷积层是连接锁定模型和可训练副本的“开关”。
定义: 零卷积层是一种1x1的卷积层,其权重和偏置在初始化时都被设为零。
作用: 在训练开始时,由于零卷积层的权重和偏置都为零,它的输出也必然为零。这意味着在训练的初始阶段,可训练副本对原始模型的输出没有任何影响,整个模型的行为与原始的、未经修改的Stable Diffusion完全一致。
优势: 这种设计极大地保护了模型的训练稳定性。它避免了在训练初期,由于可训练副本尚未学习好,其产生的随机噪声会污染和破坏原始模型精心学习到的深度特征。随着训练的进行,模型会通过反向传播逐渐学习到零卷积层的非零权重,使得条件控制信息能够以一种渐进、平滑的方式融入到生成过程中。
数据流(Data Flow): 如下图所示,对于U-Net中的一个块(例如一个ResNet块):
U-Net的输入特征图
x同时流向锁定的原始块和可训练的副本块。外部的条件图像
c(例如Canny边缘图)经过一个小型编码网络E处理后,其输出也输入到可训练副本块中。可训练副本块的输出会经过一个零卷积层。
原始块的输出与经过零卷积层处理后的副本块输出相加,得到最终的输出
y_c。这个输出会通过跳跃连接(skip connection)传递给U-Net的解码器部分。
用公式可以简化表示为:
其中
F(x; Θ)是锁定的原始块,F(·; Θ_c)是可训练副本,Z代表零卷积层。在训练开始时,Z的输出为0,因此y_c = y,模型退化为原始模型。
技术细节
训练过程:
突然收敛现象(Sudden Convergence Phenomenon): 论文观察到一个有趣的现象。由于零卷积层的存在,模型在训练初期就能生成高质量的图像(因为它本质上就是原始的Stable Diffusion)。在训练了数千步之后,模型会突然“学会”遵循条件输入,而不是逐渐地、一点点地学习。这表明ControlNet架构能够快速找到将条件信息注入生成过程的最优方式。
提示词随机丢弃(Prompt Dropout): 在训练期间,研究者以50%的概率将文本提示词替换为空字符串。这一策略强迫ControlNet不仅依赖文本来理解图像内容,还要学会直接从条件图像中解析语义。例如,当看到一个房子的边缘图时,即使没有“a house”的提示,模型也应能生成一个房子。这大大增强了ControlNet在没有文本提示或提示不足的情况下的可用性。
推理过程
多重控制组合(Composing Multiple ControlNets): ControlNet的架构天然支持多种条件的组合。例如,如果想同时使用人体姿态和深度图进行控制,只需将Pose ControlNet的输出和Depth ControlNet的输出直接相加到U-Net的对应层即可。这种简单的加法操作就能生效,无需复杂的权重调整或模型融合,体现了其设计的优雅和可扩展性。
分类器无关指导权重调整(CFG Weighting): Classifier-Free Guidance (CFG) 是提高扩散模型生成质量的关键技术。ControlNet的引入会影响CFG的平衡。论文提出了一种“ControlNet指导权重”的启发式方法,在推理时可以调整ControlNet的影响力,让用户可以权衡生成结果与条件输入的匹配程度。
鲁棒性与效率
对数据集大小的鲁棒性: 实验证明,ControlNet对训练数据集的大小不敏感。即使在只有几千张图片的小数据集上训练,也能取得不错的效果。当数据集增大时,其性能也能相应提升。这得益于它充分利用了原始大模型的先验知识,只需学习条件控制这一特定任务。
计算效率: 由于巨大的原始模型权重被锁定,训练时无需计算其梯度,这极大地节省了GPU显存和计算时间。相比于微调整个模型,训练一个ControlNet的成本要低得多,甚至可以在消费级显卡(如RTX 3090)上完成。
综上所述,ControlNet通过创新的“锁定-复制”架构和“零卷积层”设计,成功解决了在大型预训练扩散模型上添加新条件控制的难题。它既保留了原始模型的高质量生成能力,又实现了对图像构图的精细控制,同时具有训练高效、对数据量要求低等优点,为可控内容生成领域带来了革命性的突破。
GSFix3D: Diffusion-Guided Repair of Novel Views in Gaussian Splatting (2024)
输入 (Input):
一个初始的、可能存在瑕疵的 3D高斯溅射 (3DGS) 模型。
一个对应的 3D网格 (Mesh) 模型 (作为几何先验)。
一个需要生成高质量图像的 新视角位姿。
输出 (Output):
一个经过优化和修复的 3D高斯溅射模型。
从新视角渲染出的 高质量、无瑕疵的2D图像。
解决的任务 (Task):
修复3D高斯溅射在新视角下的渲染瑕疵。当从训练时未见过的、视角较为极端的位置渲染图像时,3DGS会产生空洞、浮动块等问题。
GSFix3D利用一个定制的扩散模型(GSFixer)来“脑补”和修复单张2D图像的瑕疵,然后通过一种创新的蒸馏方法,将2D图像的修复结果“写回”到3D模型中,从而提升整个3D场景的质量和真实感。
Motivation
这篇文章的核心动机是为了解决3D高斯溅射(3DGS)方法的一个关键痛点。
3DGS的局限性: 3DGS作为一种新兴的、高效的3D场景表示方法,能够实现高质量的实时渲染。然而,它的效果严重依赖于密集且覆盖全面的输入视角。当从训练视角之外的极端新视角或在观测不足的区域进行渲染时,3DGS往往会产生各种视觉瑕疵(artifacts),例如:
空洞 (Holes):场景中由于缺乏观测数据而出现的黑色或空白区域。
浮动块 (Floaters):场景中出现的不符合几何逻辑的、漂浮在空中的彩色斑点或团块。
不完整的几何结构:物体表面残缺不全,几何形状不自然。 这些问题严重影响了渲染图像的真实感和质量,限制了3DGS在需要自由视角漫游或处理稀疏输入数据时的应用。
扩散模型的潜力与挑战: 与此同时,以Stable Diffusion为代表的扩散模型在图像生成领域取得了巨大成功。它们从海量数据中学习到了强大的生成先验(generative priors),能够生成极其逼真和多样化的图像内容。这使得它们具备了修复和内容补全的潜力。 然而,直接将通用的扩散模型应用于3D重建修复任务面临以下挑战:
缺乏场景特异性:预训练的扩散模型不了解特定3D场景的几何和纹理信息,修复结果可能与场景的真实内容不一致。
缺乏3D一致性:对单张2D图像的修复无法保证从不同视角看过去的3D结构是一致的。
输入-输出不一致:扩散模型主要用于生成,而非精确修复,可能会过度修改图像中本已正确的部分。
核心动机:本文旨在结合3DGS的快速渲染能力和扩散模型的强大生成先验,创建一个能够智能修复3DGS渲染瑕疵的框架。其目标是,在保留场景已有观测细节的基础上,利用扩散模型“脑补”出缺失或错误区域的合理内容,并最终将这种2D图像层面的修复结果 “蒸馏”回3D场景表示中,从而提升整个3D模型的质量。
Architecture
整个框架名为GSFix3D,其核心组件是一个经过特殊微调的扩散模型,名为GSFixer。整体流程如下图所示,可以分为三个主要阶段:
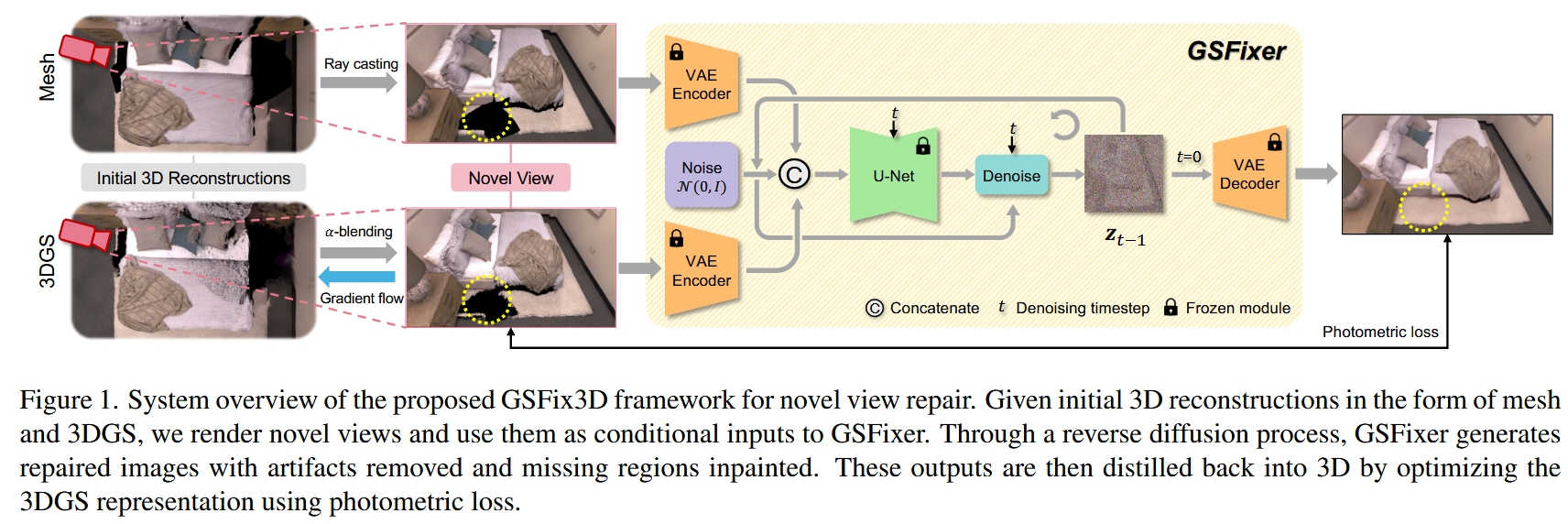
输入与条件生成:
首先,使用一个现有的3D重建系统(如论文中使用的GSFusion)同时重建出场景的3DGS表示和一个传统网格(Mesh)表示。
当需要修复一个新视角时,从该视角分别渲染出两张图像:一张来自3DGS(
I_gs),另一张来自Mesh(I_mesh)。I_gs包含丰富的纹理细节但可能有瑕疵,而I_mesh的几何结构更完整但通常不够真实。这两张图像将作为修复模型的条件输入。
2D图像修复 (2D Image Repair via GSFixer):
将
I_gs和I_mesh输入到核心模型GSFixer中。GSFixer是一个在特定场景数据上微调过的潜在扩散模型(Latent Diffusion Model)。GSFixer执行一个反向扩散(去噪)过程,从一个随机高斯噪声开始,在
I_gs和I_mesh的引导下,逐步生成一张高质量、无瑕疵的修复图像Î_fixed。这个过程不仅去除了浮动块等瑕疵,还能合理地补全空洞。
3D表示蒸馏 (3D Representation Distillation):
将GSFixer生成的修复图像
Î_fixed作为伪真值(pseudo ground truth)。通过优化3DGS的参数(位置、旋转、缩放、颜色、不透明度等),最小化从当前3DGS渲染出的图像
I_gs与伪真值Î_fixed之间的光度损失(photometric loss)。这个优化过程将2D图像的修复信息“蒸馏”回3DGS表示中,从而真正地改善了3D场景模型。例如,原先是空洞的区域,通过这个过程会生成新的高斯基元来填充。
Method
微调协议 (Fine-Tuning Protocol)
这是训练GSFixer模型的关键。GSFixer并非从零开始训练,而是对一个预训练的Stable Diffusion v2模型进行定制化微调。
1. 网络架构
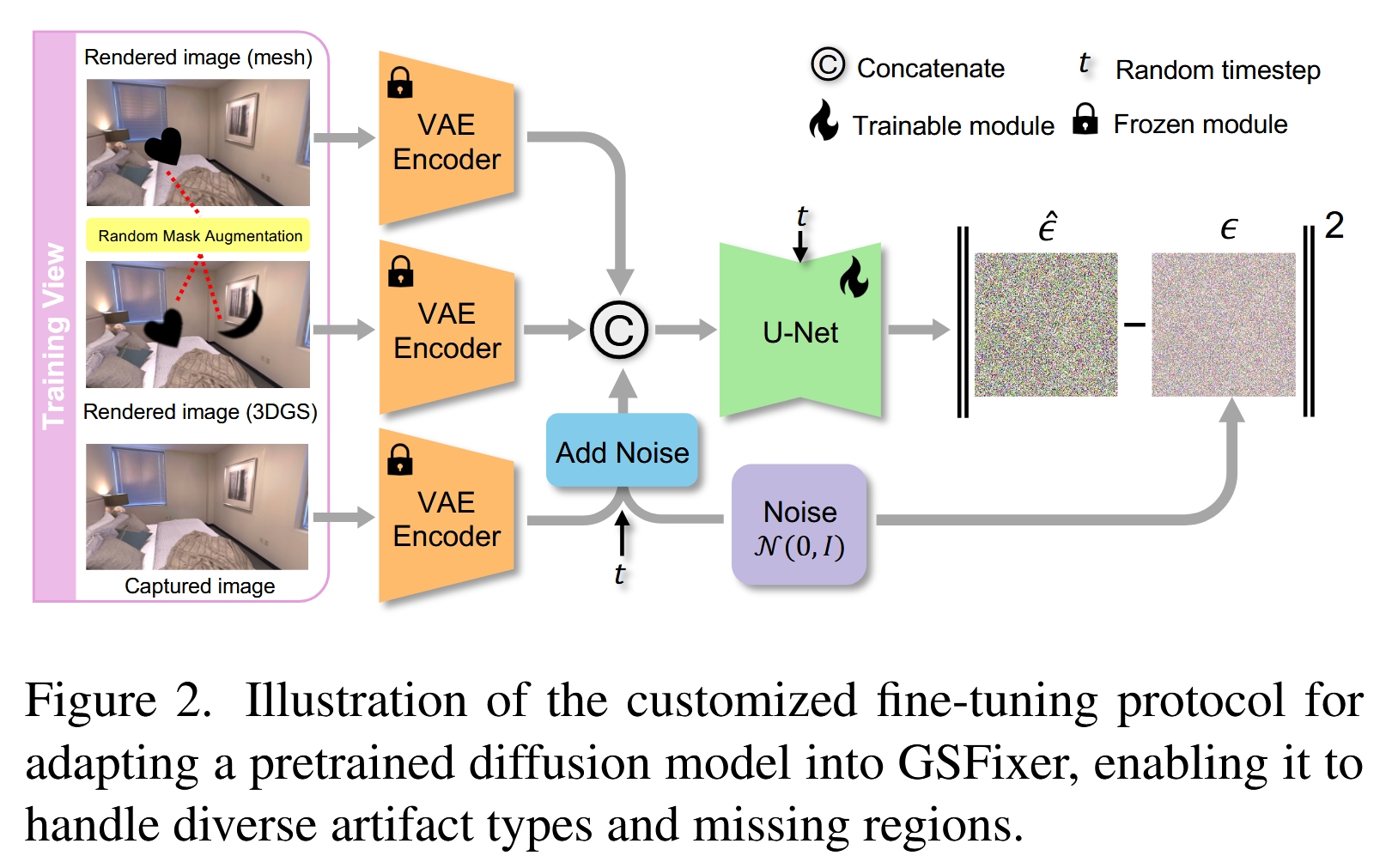
基础模型:采用Stable Diffusion v2,其核心是一个在 潜在空间(latent space) 中操作的U-Net去噪网络。为了提高效率,所有图像都先通过一个固定的变分自编码器(VAE)的编码器(Encoder)压缩到潜在空间。
双重条件输入策略 (Dual-Conditioning Strategy):这是该方法的一个核心创新点。传统的图像修复模型可能只使用一张带瑕疵的图像作为输入。而GSFixer同时使用3DGS渲染图
I_gs和 Mesh渲染图I_mesh作为条件。为什么需要双重条件? 这两种表示具有互补优势:
3DGS (
I_gs):提供了高度逼真的外观和纹理信息,但在观测不足处有瑕疵。Mesh (
I_mesh):虽然渲染效果可能不那么真实,但提供了更稳定、更完整的几何结构先验,尤其是在3DGS出现空洞的区域。
通过结合两者,GSFixer可以同时利用高质量的外观线索和稳健的几何结构,从而做出更合理、更准确的修复。
网络修改:
首先,将条件图像
I_mesh、I_gs和带噪的目标真值图I_gt都通过冻结的VAE编码器转换为潜在表示z_mesh、z_gs和z_t。在U-Net的输入端,将这些潜在表示沿着通道维度拼接起来,形成一个新的输入张量
concat(z_mesh, z_gs, z_t)。由于输入通道数增加了(例如,从4通道增加到12通道),U-Net的第一个卷积层需要修改。作者采用了一个巧妙的技巧:将原卷积核的权重复制三份,然后将每个权重值除以三。这样做的好处是,在保持权重初始分布和激活值尺度的同时,适配了新的输入维度,从而最大程度地保留了预训练模型的知识,避免了训练初期的不稳定性。
训练目标:训练的目标是让U-Net预测出添加到干净潜在表示中的噪声
ε。损失函数是标准的DDPM L2损失:其中
z_t是加噪后的潜变量,ε_θ是U-Net网络。
2. 数据增强 (Data Augmentation)
这是另一个至关重要的技术点,目的是教会模型如何进行内容补全。
问题:在微调时,使用的训练数据是场景中已捕获的视角,这些图像大部分是完整的,没有大的空洞。如果只用这些数据微调,模型将学不会如何填充在新视角中出现的大面积缺失区域。
解决方案:随机掩码增强 (Random Mask Augmentation) 作者引入了一种基于掩码的数据增强策略,在训练图像上人为制造缺失区域。
掩码来源:他们没有使用简单的矩形掩码,而是从一个真实的语义分割数据集中[32]获取了各种形状不规则的物体掩码。这样做的好处是,掩码的形状更自然、更多样,模拟的缺失区域更接近真实世界中的遮挡情况。
两种应用方式:
模拟遮挡:将同一个掩码同时应用到
I_mesh和I_gs上。这模拟了新视角下由于前景物体遮挡而导致的共同缺失区域。模拟3DGS特有瑕疵:额外使用一个独立的掩码,只应用在
I_gs上。这专门模拟了3DGS自身因优化失败或观测稀疏而产生的特有瑕疵(如浮动块或局部空洞),而这些瑕疵在更稳健的Mesh上可能不存在。
为了更好地模拟3DGS渲染中瑕疵的柔和边界,作者还对应用在
I_gs上的掩码进行了轻微的高斯模糊。
通过这种精心设计的数据增强,GSFixer在微调过程中就能学习到强大的、针对真实场景的内容补全能力。
GSFixer的推理过程
在对新视角进行推理(修复)时,过程如下:
将微调好的GSFixer(U-Net)参数冻结。
为新视角渲染出
I_mesh和I_gs,并通过VAE编码器得到z_mesh和z_gs。初始化一个与目标潜在表示维度相同的随机高斯噪声
z_T。进行迭代去噪。在每一步
t,将z_mesh、z_gs和当前的噪声潜变量z_t拼接后输入U-Net,预测出噪声ε_θ。使用 DDIM (Denoising Diffusion Implicit Models) 采样器来更新潜变量
z_{t-1}。DDIM相比DDPM速度更快,可以用很少的步数(如论文中的4步)生成高质量结果。其更新公式大致为:这里
x̂₀代表了在当前步骤t对最终干净潜变量的预测。迭代结束后,得到最终的干净潜在表示
z_0。将
z_0输入冻结的VAE解码器,得到最终修复好的图像Î_fixed。
GSFix3D:将修复结果蒸馏回3D (Diffusion-Guided Novel View Repair)
这是将2D修复提升到3D场景修复的最后一步,也是整个GSFix3D框架的闭环。
目标:将
Î_fixed中的视觉改进迁移到3DGS表示中。方法:利用3DGS的完全可微特性。
优化过程:
将
Î_fixed视为该新视角下的“理想渲染结果”或“伪真值”。继续对初始的3DGS模型进行优化,但这次的损失函数是 当前3DGS的渲染图
I_gs与修复图Î_fixed之间的光度损失。损失函数由L1损失和SSIM损失加权组成,以同时保证像素级和结构级的相似性。
自适应密度控制:在优化过程中,重新启用了原始3DGS论文中提出的高斯基元增殖和分裂机制。这一点非常关键,因为它允许在之前是空洞的区域创建新的高斯基元来填充内容,而不仅仅是拉伸或移动已有的高斯基元。
提升全局一致性:为了避免只修复单个视图而导致与其他视图不一致,作者采用了一种迭代策略。他们会选择一批稀疏的关键帧进行修复,然后将这些修复后的图像及其位姿加入到原始训练数据集中,再对整个增强后的数据集进行几轮优化。这确保了修复结果在全局范围内是协调一致的。
总结
GSFix3D通过一个设计精巧的流程,成功地将扩散模型的强大生成能力引入到3DGS的修复任务中。其核心技术亮点包括:
双重条件输入:同时利用Mesh的几何稳定性和3DGS的外观逼真性,为修复提供更全面的信息。
定制化微调与数据增强:通过场景特异性微调和创新的随机掩码增强,使模型能够学习到特定场景的先验知识和强大的内容补全能力。
2D到3D的蒸馏机制:利用3DGS的可微特性,将2D图像的修复结果有效地“写回”到3D表示中,实现了对3D场景本身的优化。
该方法仅需少量场景数据进行几小时的微调,就能显著提升3DGS在稀疏观测和极端视角下的渲染质量,展示了其在实际应用中的巨大潜力和效率。
Pixel-Perfect Depth with Semantics-Prompted Diffusion Transformers (NeurIPS 2025)
输入 (Input):
一张单独的RGB图像。
输出 (Output):
一张与输入图像尺寸对应的深度图 (Depth Map)。
解决的任务 (Task):
高质量的单目深度估计,其核心目标是解决现有方法普遍存在的 “飞行像素” (flying pixels) 问题。
该模型通过直接在 像素空间(pixel space) 进行扩散生成,避免了传统生成模型因使用VAE(变分自编码器)进行潜在空间压缩而导致的边缘伪影和细节丢失。
最终目标是生成能够转换为高质量、无伪影、边缘锐利的3D点云的深度图,以增强在3D重建、机器人等下游任务中的实用性。
Motivation
这篇论文的核心动机是解决单目深度估计(Monocular Depth Estimation, MDE)中的一个关键痛点问题:“飞行像素”(flying pixels)。
当我们从单个2D图像预测深度图,并将该深度图转换成3D点云时,物体边缘和细节处常常会出现一些不属于任何物体的、悬浮在空中的错误点,这些就是“飞行像素”。这个问题的存在极大地限制了深度估计在3D重建、机器人操作、新视角合成等下游任务中的实际应用价值。
论文指出,现有的主流方法都无法很好地解决这个问题,但原因各不相同:
判别式模型(Discriminative Models): 例如Depth Anything v2等模型,它们通常通过回归损失函数来直接预测每个像素的深度值。为了最小化损失,模型倾向于在深度不连续的物体边缘(例如前景和背景的交界处)输出一个平滑的、介于两者之间的平均深度值。这种“模糊”的边缘预测在转换成点云后,就形成了“飞行像素”。
生成式模型(Generative Models): 例如Marigold等基于扩散(Diffusion)的模型,它们在理论上能够更好地捕捉物体边缘的多模态深度分布,从而生成更清晰的边缘。然而,当前主流的生成式模型(如Stable Diffusion)为了降低计算复杂性,都在一个低维的 潜在空间(latent space) 中进行扩散操作。这意味着,它们需要一个变分自编码器(VAE)先将高清的深度图压缩成低维的潜在表示,在潜在空间生成后,再用VAE解码器恢复成高清深度图。问题在于,VAE的压缩和解压过程是有损的,这个过程本身就会引入伪影,导致边缘和细节信息的丢失,最终同样会产生“飞行像素”。
因此,本文作者的动机非常明确:设计一个既能利用生成式模型保留清晰边缘的优势,又能避免因VAE压缩而引入“飞行像素”的新型深度估计框架。 为了实现这一目标,他们提出了直接在 像素空间(pixel space) 进行扩散生成的方案,并设计了一系列创新的技术来克服在像素空间直接生成所带来的巨大挑战(如计算成本高、难以收敛等)。
Architecture
论文提出的模型名为Pixel-Perfect Depth,其整体架构如论文图3所示,可以概括为一个端到端的流程:
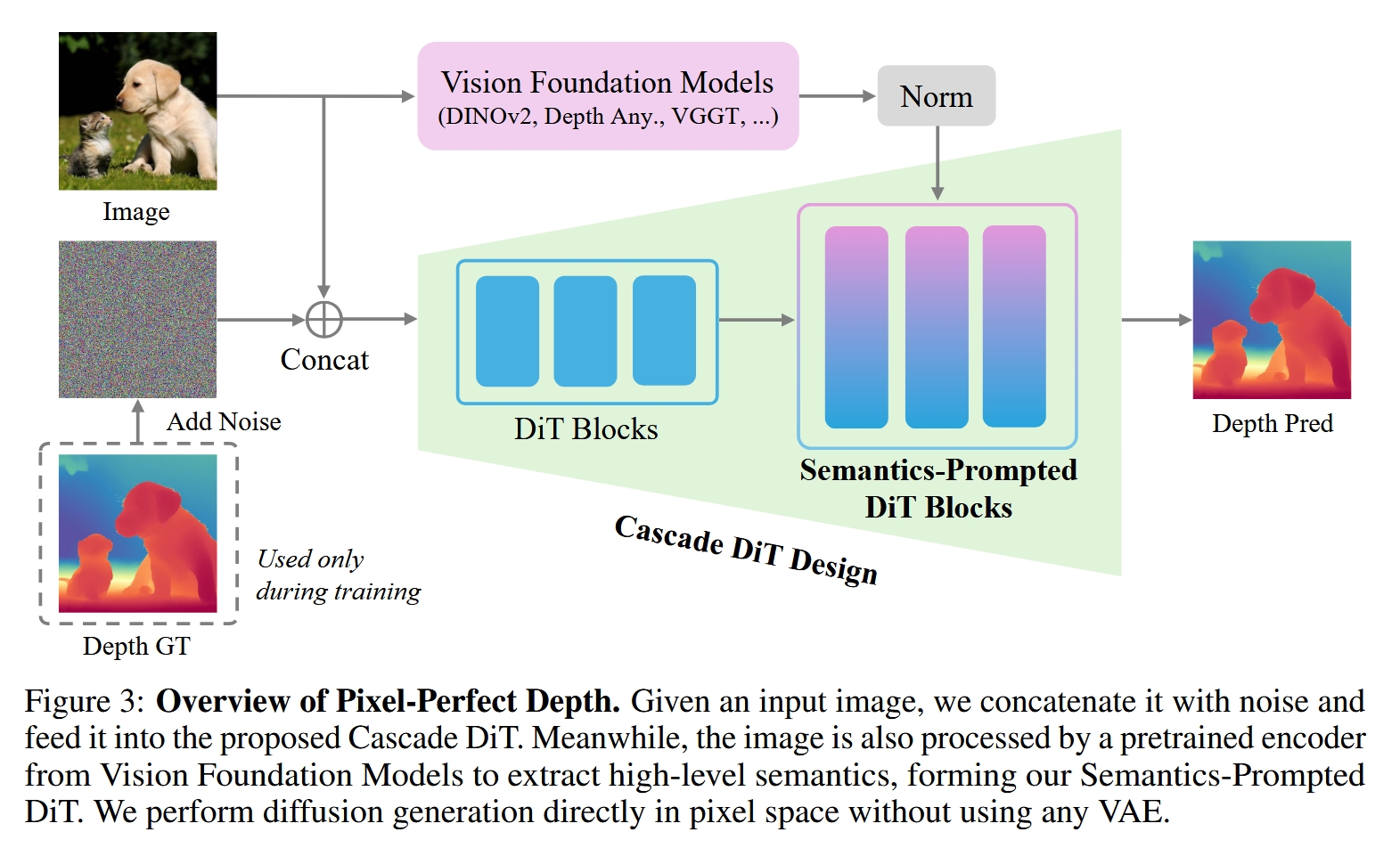
输入与噪声拼接:
模型的输入是一张普通的RGB图像。
在训练过程中,模型还将该图像对应的真实深度图作为目标。
在生成过程的初始阶段,模型会生成一个与输入图像尺寸相同的高斯噪声图。
这张RGB输入图像将与当前的噪声图(或在去噪过程中的中间结果)在通道维度上进行拼接。
语义信息提取 (核心创新之一):
与此同时,输入的RGB图像会被送入一个 预训练好的、冻结的视觉基础模型(Vision Foundation Models, VFMs) 中,例如DINOv2或Depth Anything的编码器。
这个VFM的作用是提取图像的高层语义特征。这些特征包含了对图像内容的全局理解,比如物体的轮廓、类别和场景布局等信息。
提取出的语义特征经过一个归一化处理,准备注入到主干网络中。
级联扩散Transformer主干网络 (Cascade DiT):
拼接了图像和噪声的张量被送入模型的主干网络——级联扩散Transformer(Cascade DiT Design)。这个网络完全由Transformer模块构成,不包含任何卷积层。
该网络的核心任务是学习如何一步步地从纯噪声中,根据输入图像的引导,预测出噪声中的“速度场”(velocity field),从而逐渐还原出清晰的深度图。
在去噪过程的中间阶段,从VFM中提取的语义特征会被注入到DiT模块中,这就是所谓的 “语义提示”(Semantics-Prompted)。这些语义信息像一个“全局导航仪”,引导DiT模块在生成细节的同时,不会丢失整体的结构和一致性。
输出:
经过多步迭代去噪后,主干网络最终输出一个预测的深度图。这个深度图由于是直接在像素空间生成的,避免了VAE带来的伪影,因此在转换成点云后几乎没有“飞行像素”。
总结来说,Pixel-Perfect Depth是一个以纯Transformer为骨干的像素空间扩散模型,它巧妙地利用视觉基础模型提取的语义信息来“提示”和“约束”扩散过程,并通过级联设计来优化效率和精度,最终生成高质量、无飞行像素的深度图。
Method
1. Pixel-Perfect Depth (核心目标)
这部分重申了模型的最终目标:生成一个转换成点云后没有飞行像素的“像素完美”深度图。它详细阐述了现有判别式模型因“均值预测偏见”和生成式模型因“VAE压缩”而导致飞行像素的根本原因。
为了从根本上解决这个问题,作者提出了直接在像素空间进行扩散的方案。这样做的好处是显而易见的:模型可以直接学习像素级别的深度分布,尤其是在物体边缘的不连续分布,从而避免了任何形式的压缩伪影。但挑战也同样巨大:在高分辨率的像素空间(例如1024x768)直接训练一个生成模型,计算量极大,并且模型很难同时兼顾全局结构的正确性和局部细节的精细度,非常难以优化。为了应对这些挑战,作者引入了下面两个关键设计:Semantics-Prompted DiT 和 Cascaded DiT Design。
2. 生成范式 (Generative Formulation)
模型选择了Flow Matching作为其生成框架的核心。Flow Matching是一种较新的生成模型训练范式,它通过学习一个将高斯噪声连续变换到真实数据分布的“速度场”来实现生成。
插值样本定义: 首先,定义一个在时间
t(从0到1)的插值样本xt。它是由真实的干净深度图x0和一个标准高斯噪声x1线性插值得到的。当
t=0时,xt = x0(真实深度图);当t=1时,xt = x1(纯噪声)。速度场 (Velocity Field): 这个插值路径定义了一个从
x0到x1的恒定速度场vt。对xt关于t求导即可得到:这个速度场描述了从真实数据“移动”到噪声的方向。
训练目标: 模型
vθ(xt, t, c)的任务就是根据当前的带噪样本xt、时间步t和作为条件的输入图像c,来预测这个真实的速度场vt。训练的目标函数是让模型预测的速度和真实速度之间的均方误差(MSE)最小化。推理过程: 在推理(生成深度图)时,过程则反过来。从一个纯噪声
x1(即t=1)开始,使用训练好的模型vθ来求解这个常微分方程(ODE),通过多步迭代,逐步将噪声往t=0的方向(即真实数据的方向)推进。每一步的更新公式如下:其中时间步
ti从1递减到0,最终得到的x0就是模型生成的深度图。
3. 语义提示扩散Transformer (Semantics-Prompted DiT, SP-DiT)
这是为了解决像素空间扩散难以优化问题的第一个核心技术。直接在像素空间应用标准的扩散Transformer (DiT) 效果很差(如论文图6所示),模型既无法把握全局结构,也生成不了精细的细节。作者分析其根本原因在于,模型在去噪的每一步都只能看到局部的像素信息,缺乏对整个图像内容的全局理解。
SP-DiT的设计思想就是:用一个强大的、预训练好的视觉基础模型(VFM)来为DiT提供全局语义指导。
提取语义表示: 给定输入图像
c,首先用一个VFM的编码器f(例如DINOv2的ViT-L/14编码器)来提取高层语义特征e。这里的
e是一系列Token,T'是Token数量,D'是每个Token的维度。这个e包含了对图像“讲了什么”的深刻理解。特征归一化 (关键步骤): 作者发现,从VFM中提取的语义特征
e的数值大小(magnitude)与DiT内部流动的Token的数值大小差异很大。如果直接将它们融合,会导致训练不稳定和性能下降。为此,他们引入了一个简单而有效的L2归一化步骤,对e在特征维度上进行归一化,得到ê。这一步使得注入的语义提示在数值上与DiT的内部状态更加匹配,确保了稳定的训练和有效的融合。
语义融合: 归一化后的语义表示
ê通过一个简单的多层感知机(MLP)层B和加法,被整合到DiT模型的内部Tokenz中。经过融合后,后续的DiT模块就获得了语义提示,从而能在生成精细视觉细节的同时,有效保持全局语义的一致性。
4. 级联DiT设计 (Cascade DiT Design, Cas-DiT)
这是为了解决像素空间扩散计算成本高昂问题的第二个核心技术。它的设计基于一个观察:在DiT架构中,靠前的模块主要负责捕捉和生成全局的、低频的结构信息,而靠后的模块则专注于高频的、精细的细节信息。
基于这个洞察,Cas-DiT采用了一种从粗到细(coarse-to-fine)的级联策略来优化计算效率和精度。
设计细节: 假设整个模型有
N个DiT模块。粗糙阶段 (Coarse Stage): 前
N/2个DiT模块使用一个较大的Patch Size(例如16x16)。这意味着输入图像被分割成较少数量的、尺寸更大的Token。Token数量的减少直接导致了计算量的显著下降(Transformer的计算复杂度与Token数量的平方成正比)。这个阶段强迫模型优先学习和处理图像的全局结构和低频信息,这恰好与VFM提取的高层语义信息相匹配。精细阶段 (Fine Stage): 后
N/2个DiT模块(也就是SP-DiT模块)则使用一个较小的Patch Size(例如8x8)。模型在这里会增加Token的数量(通过一个MLP层和Reshape操作实现),从而获得更高的空间分辨率。这使得模型能够在此阶段专注于生成高频的、精细的空间细节。
这种级联设计不仅大幅提升了效率(论文提到推理时间减少了30%),还因为它模拟了人类视觉系统先看轮廓再看细节的层级感知过程,从而进一步提升了模型的精度。
5. 实现细节
这部分提供了复现模型所需的关键参数和设置。
模型架构:
总共
N=24个DiT模块。隐藏层维度
D=1024。前12个模块(粗糙阶段)的Patch Size为16,输入
H x W的图像后,Token数量为(H/16) x (W/16)。在第12个模块后,通过一个MLP层将隐藏维度扩展4倍,然后重塑(Reshape)得到
(H/8) x (W/8)的Token数量。后12个模块(精细阶段,即SP-DiT)处理这些数量更多的Token。
模型最后通过一个MLP和Reshape操作输出最终的
H x W深度图。特别强调:整个模型是纯Transformer架构,不依赖任何卷积层。
深度归一化: 为了让模型能够更好地处理室内和室外等不同尺度的场景,训练前对真值深度图
d进行了归一化:对数变换:
d' = log(d + ε),将绝对深度值转换到对数空间,以平衡不同尺度下的深度差异。分位数归一化:
其中
d'min和d'max分别是每张深度图中2%和98%位置的分位数,这使得归一化对异常值更加鲁棒。最终将值域缩放到[-0.5, 0.5]。
训练细节:
在8个NVIDIA GPU上训练。
优化器为AdamW,学习率为
1e-4。损失函数除了前面提到的MSE速度匹配损失外,还额外采用了来自Depth Anything v2的梯度匹配损失,以鼓励生成更清晰的边缘。
训练数据使用了高质量的合成数据集(如Hypersim),因为它们提供精确无误的3D几何信息,这对于训练一个旨在消除“飞行像素”的模型至关重要。
通过以上对动机、架构和技术细节的全面解析,我们可以看到,Pixel-Perfect Depth 这篇论文通过在像素空间进行扩散的根本性变革,并巧妙地设计了SP-DiT和Cas-DiT来解决随之而来的挑战,最终成功地实现了其核心目标——生成高质量、无飞行像素的深度图,为单目深度估计领域提供了一个极具价值的新思路。
Last updated
Was this helpful?