From Diffusion to GNM and NoMaD
@TOC
DDPM: Denoising Diffusion Probabilistic Models (NeurIPS 2020)
输入 (Input):
训练时: 一张真实、清晰的图像 (
x_0)。生成 (推理) 时: 一个从标准高斯分布中采样的纯噪声向量 (
x_T)。
输出 (Output):
一张与训练数据分布相似的、全新的、清晰的图像。
解决的任务 (Task):
无条件图像生成 (Unconditional Image Generation)。该模型学习一个数据集(如人脸、风景)的潜在分布,并从中生成全新的、高质量的样本,而无需任何特定指令。其核心贡献在于证明了扩散模型在图像生成质量上可以媲美甚至超越顶尖的GANs,同时训练过程更稳定。
Motivation
在2020年这篇论文发表之前,深度生成模型领域主要由以下几类模型主导:
生成对抗网络 (GANs): 在图像生成质量上处于绝对领先地位,能够生成非常逼真、高分辨率的图像。但其训练过程非常不稳定,容易出现模式坍塌 (mode collapse),且缺乏直接计算样本似然度的能力。
变分自编码器 (VAEs): 训练稳定,可以计算似然度的下界,但生成的样本通常比较模糊,细节不足。
流模型 (Flow-based Models): 能够精确计算似然度,但模型结构受到可逆性约束,通常在处理高维数据(如高分辨率图像)时表现不如GANs。
自回归模型 (Autoregressive Models): 能够获得非常高的似然度分数,但其串行的生成方式导致采样速度极其缓慢。
扩散模型 (Diffusion Models) 的理论基础在2015年 (Sohl-Dickstein et al.) 就已提出,但一直未受到广泛关注,主要是因为当时其生成样本的质量远不及GANs,且被认为实现和训练复杂。
DDPM这篇论文的核心动机是: 证明经过精心设计和简化的扩散模型,不仅能够克服训练不稳定的问题,还可以在图像生成质量上达到甚至超越顶尖的GANs。作者希望通过建立扩散模型与去噪得分匹配 (denoising score matching) 之间的联系,来简化其训练目标,并最终将其打造为一个强大、稳定且高质量的生成模型框架。
模型核心思想
DDPM将图像生成过程视为一个 逐步去噪 (denoising) 的过程。其核心思想包含两个方向相反的过程:
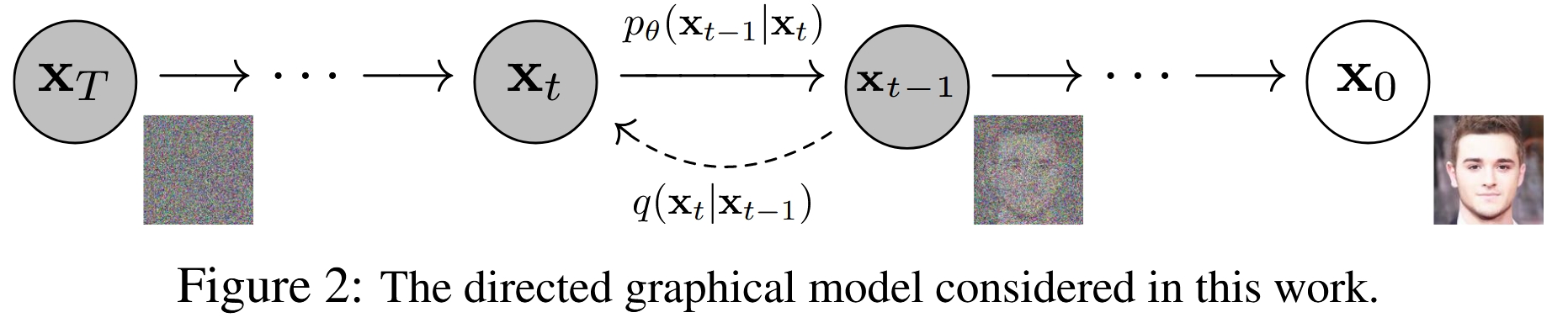
前向过程 (Forward/Diffusion Process): 这是一个固定的、无需学习的马尔可夫链。它从一张真实的、清晰的图像
x_0开始,在T个时间步内,逐步、微量地向图像中添加高斯噪声。每一步添加的噪声量由一个预设的方差表β_t控制。当T足够大时,原始图像x_0最终会变成一个完全符合标准高斯分布的纯噪声图像x_T。这个过程可以看作是对信息的逐步、可控的破坏过程。
反向过程 (Reverse/Denoising Process): 这是模型需要学习的核心部分。它从一个纯噪声
x_T(从标准高斯分布中采样)开始,同样通过一个T步的马尔可夫链,逐步地将噪声去除。在每一步t,一个神经网络会接收当前的噪声图像x_t,并预测出上一步的、稍微干净一点的图像x_{t-1}。经过T步的迭代去噪,模型最终生成一张清晰的图像x_0。这个过程就是生成(采样)过程。
整个模型的训练目标就是让这个学习到的反向过程能够精确地逆转固定的前向过程。
技术细节
前向过程
前向过程的一个关键特性是,我们可以直接从原始图像 x_0 和噪声 ε(ε ~ N(0, I))通过一个闭式解(closed-form solution)得到任意时刻 t 的噪声图像 x_t,而无需迭代计算 t 次。
令 α_t = 1 - β_t 和 α_bar_t = Π_{s=1 to t} α_s,则有:
这个公式至关重要,因为它使得我们可以在训练时随机采样任意一个时间步 t,并直接从 x_0 计算出对应的 x_t,极大地提高了训练效率。
反向过程与损失函数
反向过程的目标是学习一个神经网络 p_θ 来近似真实的后验分布 q(x_{t-1} | x_t)。然而,这个后验分布依赖于 x_0,在生成时 x_0 是未知的。幸运的是,当 x_0 给定时,这个后验分布是可解的:
其中均值 μ_tilde_t 和方差 β_tilde_t 都可以由 β_t 和 α_bar_t 计算得出。
训练的目标是最小化变分下界 (Variational Lower Bound, VLB),经过简化,可以表示为一系列KL散度项的和。其中,最关键的是在每个时间步 t,让模型预测的分布 p_θ(x_{t-1} | x_t) 逼近真实的后验分布 q(x_{t-1} | x_t, x_0)。
核心洞察:从预测图像到预测噪声
直接让神经网络去预测 x_{t-1} 的均值 μ_tilde_t 是可行的,但论文提出了一个更巧妙且效果更好的方法。
通过对 μ_tilde_t 的表达式进行变换,作者发现,预测均值等价于预测在 t 时刻添加到 x_0 上的噪声 ε。具体来说,模型 p_θ(x_{t-1} | x_t) 的均值可以被参数化为:
这里的 ε_θ(x_t, t) 就是一个神经网络,它的输入是噪声图像 x_t 和时间步 t,输出是对原始噪声 ε 的预测。
将这个参数化代入损失函数 L_{t-1} 后,经过一系列化简,损失函数变成了一个非常简洁的形式:
这个损失函数直观地表示:让神经网络 ε_θ 学习去预测它所看到的噪声图像 x_t 中包含的噪声 ε。这本质上是一个 去噪 (denoising) 任务。
简化的训练目标
作者进一步发现,直接使用上面这个简单的均方误差 (MSE) 作为损失函数,并忽略KL散度中的复杂权重项,在实践中能带来更好的样本质量。他们提出了一个最终的简化版训练目标 L_simple:
其中 t 是在 {1, ..., T} 中均匀采样的。这个目标函数非常稳定且易于实现,是这篇论文取得成功的关键之一。
模型架构
网络结构: 论文采用了类似于 PixelCNN++ 的 U-Net 架构。U-Net 的结构非常适合图像到图像的转换任务,其编码器-解码器结构和跳跃连接 (skip connections) 能够很好地保留多尺度的空间信息,这对于去噪任务至关重要。
时间编码: 由于同一个网络需要处理所有时间步
t(从1到T) 的去噪任务,模型需要知道当前处理的是哪个时间步。作者借鉴了 Transformer 中的 正弦位置编码 (sinusoidal position embedding) ,将时间步t转换为一个向量,并将其加入到U-Net的每个残差块中。注意力机制: 在U-Net的低分辨率特征图部分(例如16x16),加入了自注意力 (self-attention) 模块,以帮助模型捕捉全局依赖关系。
实验与结果
SOTA 样本质量: 在无条件 CIFAR10 数据集上,DDPM 取得了 3.17 的 FID 分数 ,在当时超过了绝大多数已发表的GAN模型,首次证明了扩散模型在图像质量上的强大竞争力。
高质量大图生成: 在 256x256 分辨率的 CelebA-HQ 和 LSUN 数据集上,生成的样本质量与当时的顶尖GAN模型 (如ProgressiveGAN) 相当,展示了其良好的可扩展性。
渐进式生成 (Progressive Generation): 论文展示了在采样过程中,模型首先生成图像的粗略轮廓和结构,然后逐步添加细节,这个过程非常有趣,类似于人类绘画。
良好的插值效果: 在隐空间中对两个样本进行插值,可以得到平滑且语义合理的过渡图像。
贡献与影响
DDPM 是深度生成模型发展史上的里程碑式工作,其主要贡献和影响如下:
确立了扩散模型的SOTA地位: 它用无可辩驳的实验结果证明,扩散模型是一种可以生成高质量样本的顶级生成模型,直接引发了后续对扩散模型的研究热潮。
简化了模型设计与训练: 提出了"预测噪声"的参数化方法和
L_simple这一极其简洁有效的训练目标,大大降低了扩散模型的实现门槛,并提高了训练的稳定性和最终效果。建立了与去噪得分匹配的桥梁: 揭示了扩散模型与去噪自编码器、得分匹配和 Langevin 动力学之间的深刻联系,统一了不同领域的思想,为后续的理论创新提供了基础。
开启了新时代: DDPM 的成功直接催生了后续一系列著名的生成模型,如 GLIDE, DALL-E 2, Imagen, 和 Stable Diffusion 等,这些模型大多都基于 DDPM 提出的核心框架进行改进和扩展,彻底改变了AI生成内容(AIGC)领域的格局。
总而言之,DDPM通过巧妙的重新参数化和目标函数简化,将一个理论上优雅但实践中效果不佳的模型类别,成功地转变为一个强大、稳定且效果顶尖的生成框架,为整个领域的发展奠定了坚实的基础。
Diffusion Models Beat GANs on Image Synthesis (NeurIPS 2021)
这篇文章是扩散模型发展历程中的一篇里程碑式的工作,它首次证明了扩散模型在主流图像生成基准上能够超越当时最先进的GAN模型。
输入 (Input):
一个纯噪声向量。
一个目标类别标签 (e.g., '猫', '狗')。
一个引导尺度 (guidance scale)
s,用于控制生成效果。
输出 (Output):
一张清晰的、明确属于输入目标类别的图像。
解决的任务 (Task):
有条件图像生成 (Conditional Image Generation),并实现了保真度-多样性的权衡。通过引入一个在带噪图像上训练的分类器来“引导”生成过程,该模型可以生成特定类别的、质量极高的图像,首次在主流基准上全面超越了GANs。
Motivation
在本文发表之前,生成对抗网络(GANs)是图像生成领域的绝对王者,尤其以StyleGAN和BigGAN为代表的模型,在生成高保真度、高分辨率图像方面取得了SOTA(State-of-the-Art)的成果。然而,GANs也存在一些固有的问题:
训练不稳定:GANs的训练是一个寻找纳什均衡的对抗过程,非常脆弱,容易出现模式崩溃(mode collapse),导致生成样本多样性差。
多样性不足:即使训练成功,GANs也常常无法完整地覆盖整个数据分布,其生成样本的多样性通常不如基于似然的模型(likelihood-based models)。
与此同时,扩散模型(Diffusion Models)作为一种基于似然的模型,展现出了一些优良特性:
训练稳定:其训练目标是固定的,不涉及对抗训练,因此训练过程非常稳定。
高多样性:作为似然模型,它天然地倾向于学习完整的数据分布,生成样本的多样性很好。
然而,在当时,扩散模型在 样本质量(保真度) 上仍然落后于顶级的GANs,并且其 采样速度非常慢 。
作者们认为,扩散模型与GANs之间的性能差距主要源于两个因素:
模型架构:GAN的生成器架构(如StyleGAN的风格化网络)经过了大量研究和精细调优,而扩散模型普遍使用的UNet架构相对来说还有很大的探索和改进空间。
多样性与保真度的权衡(Diversity-Fidelity Trade-off):GANs可以通过一些技巧(如BigGAN的“截断技巧”,truncation trick)来牺牲一部分样本多样性,从而换取更高的样本保真度。而当时的扩散模型缺乏一个类似且有效的机制。
因此,本文的核心动机就是解决这两个问题,通过 改进模型架构和 引入一种新的引导机制,来证明扩散模型不仅能追上,甚至可以超越GANs。
模型架构改进 (Ablated Diffusion Model - ADM)
作者首先对扩散模型的基础架构——UNet进行了一系列的消融实验,以找到最优的配置。他们将改进后的模型称为 ADM (Ablated Diffusion Model)。主要改进点包括:
模型宽度与深度:在固定模型总参数量的情况下,作者发现 增加模型宽度(更多的通道数) 比增加模型深度(更多的残差块)能带来更好的性能和更快的收敛速度。
注意力机制:
增加注意力头数:将注意力机制从单头变为多头(类似Transformer),并发现每个头分配64个通道时效果最好。
在多分辨率上使用注意力:原始的DDPM只在16x16分辨率的特征图上使用注意力。作者发现,在 多个分辨率(如32x32, 16x16, 8x8) 上都使用注意力机制能显著提升模型性能。
Up/Downsampling模块:采用了BigGAN中使用的残差块进行上采样和下采样,这比标准的卷积效果更好。
自适应组归一化 (Adaptive Group Normalization - AdaGN) :这是一个关键的改进。在每个残差块中,模型不再是简单地将时间步(timestep)和类别(class)的嵌入向量加到特征图上,而是利用这个嵌入向量去 预测组归一化(Group Normalization)层的缩放(scale)和偏置(shift)参数。这种方式借鉴了StyleGAN中的AdaIN,使得条件信息(时间和类别)能更有效地控制生成过程。
通过这些架构上的改进,ADM模型在无条件生成任务上(如LSUN数据集)已经能够取得超越StyleGAN2的FID分数。
核心技术:分类器引导 (Classifier Guidance)
这是本文最核心、最具影响力的技术贡献,它为扩散模型提供了一个强大的 多样性-保真度权衡机制。
- 基本思想
在扩散模型的反向去噪过程中,每一步都是从一个较噪声的图像 x_t 预测一个稍干净的图像 x_{t-1}。分类器引导的思想是,在这个预测过程中,不仅依赖扩散模型本身学到的分布 p(x_t|x_{t-1}),还要利用一个 外部的图像分类器 p(y|x_t) 来“引导”生成方向。
具体来说,我们希望生成的样本不仅看起来真实,而且还要明确地属于目标类别 y。分类器可以判断当前的噪声图像 x_t 有多像类别 y,并提供一个梯度信号,告诉模型应该如何调整才能让它“更像”类别 y。
- 技术细节
反向去噪过程的目标是建模条件分布 p(x_{t-1} | x_t, y)。根据贝叶斯定理,这个分布正比于 p(x_{t-1} | x_t) * p(y | x_{t-1}, x_t)。作者将其近似为:
取对数后,条件分布的对数似然是无条件模型和分类器对数似然的和。在采样时,这意味着我们可以通过调整去噪步骤的均值来实现引导。
原始的去噪步骤是从一个均值为 μ,方差为 Σ 的高斯分布中采样。经过引导后,新的均值 μ_guided 变为:
其中:
μ(x_t)是原始扩散模型预测的均值。∇(x_t) log p(y|x_t)是 分类器对数似然关于输入噪声图像x_t的梯度。这个梯度指向了能让分类器最大化地将x_t识别为类别y的方向。s是 引导尺度(guidance scale),一个超参数。s=0时,没有引导。s>1时,会放大分类器的引导效果,迫使模型生成在分类器看来“极其典型”的样本。这会提升保真度(fidelity)但降低多样性(diversity) 。
分类器训练
需要注意的是,这个用于引导的分类器 p(y|x_t) 必须在 加了噪声的图像 上进行训练,这样它才能在去噪过程的任意时间步 t 对噪声图像 x_t 做出准确的判断和引导。
实验结果
作者在多个标准数据集上验证了他们的方法,并取得了突破性成果。
超越GANs:在ImageNet 128x128分辨率上,ADM-G(带引导的ADM)取得了FID 2.97的惊人成绩,远超当时BigGAN-deep的最好结果。在256x256和512x512分辨率上也同样刷新了SOTA记录。
权衡曲线更优:与BigGAN的截断技巧相比,分类器引导在多样性-保真度的权衡上表现得更出色,即在相同的保真度下能实现更高的多样性。
采样速度:虽然采样仍然比GAN慢,但作者展示了使用DDIM采样器,仅需25个采样步骤就能达到与Big-GAN相当的FID,大大缓解了采样慢的问题。
引导与上采样的结合:作者发现,分类器引导和多阶段上采样是两种互补的技术。 引导主要提升精度(Precision),而上采样擅长保持多样性(Recall)。将两者结合——在低分辨率模型上使用引导,然后用上采样模型放大到高分辨率——可以得到 最佳的生成效果 (如ImageNet 512x512上FID达到3.85)。
总结与影响
这篇论文是扩散模型发展的一个转折点。它通过系统性的架构改进和创新的分类器引导技术,解决了扩散模型长期以来在样本质量上不如GANs的问题。
主要贡献:
提出了一套优化的扩散模型架构(ADM),使其在无条件生成任务上达到SOTA。
发明了分类器引导技术,为扩散模型提供了强大的多样性-保真度控制能力,使其在条件生成任务上全面超越GANs。
深远影响:
它确立了扩散模型作为顶级生成模型的地位,引发了后续研究的热潮。
“引导”这一思想被后续工作发扬光大。例如,OpenAI后续的DALL-E 2和Google的Imagen等模型,都采用了 “无分类器引导”(Classifier-Free Guidance) 技术。该技术是本文思想的直接演进,它不再需要一个独立的分类器,而是通过在训练时以一定概率丢弃条件信息,让模型自身同时学习条件和无条件分布,从而在采样时进行自我引导。这使得引导机制变得更加通用和强大,并成为现代文生图模型的标配。
Classifier-Free Diffusion Guidance (NeurIPS 2021 Workshop)
DDPM 只能生成无条件的样本。但在机器人导航中,策略必须是有条件的(例如,以目标图像为条件)。这篇论文提出了一种非常有效且流行的方法,让扩散模型能够根据条件生成样本,而无需额外训练一个分类器。这篇文章是扩散模型发展史上的一个里程碑,它提出了一种高效、简洁且强大的方法来控制生成样本的质量和多样性,并已成为后续所有大规模条件扩散模型(如DALL-E 2, Imagen, Stable Diffusion)的标准技术。
输入 (Input):
一个纯噪声向量。
一个条件信息
c(例如,类别标签或文本描述)。一个引导强度
w。
输出 (Output):
一张与输入条件
c相符的高质量图像。
解决的任务 (Task):
简化版的有条件图像生成。它解决了上一篇工作中需要额外训练一个分类器的问题。通过在训练时以一定概率随机丢弃条件信息,让单个模型同时学会条件生成和无条件生成。在推理时,通过组合这两种预测,实现了无需分类器的“引导”,该技术已成为现代文生图模型的标配。
Summary
本文提出了一种在条件扩散模型中,无需额外训练一个分类器,即可实现“引导(Guidance)”的技术。该技术能够像之前的“分类器引导”方法一样,有效地在生成样本的保真度(Fidelity/Quality)和多样性(Diversity)之间进行权衡。作者通过在一个模型中联合训练一个条件扩散模型和一个无条件扩散模型,并在采样时将两者的分数估计(score estimates)进行线性组合,从而实现了这一目标。这种方法不仅简化了训练流程,也证明了纯粹的生成模型自身就有能力实现高质量的引导生成,而无需依赖外部模型的梯度。
Motivation
在本文之前,Dhariwal & Nichol (2021) 在他们的论文《Diffusion Models Beat GANs on Image Synthesis》中提出了 分类器引导(Classifier Guidance) 技术。这项技术极大地提升了扩散模型生成样本的质量,使其在ImageNet生成任务上首次超越了顶级的GAN模型。
分类器引导的核心思想是:在扩散模型的每一步去噪过程中,不仅使用扩散模型自身预测的噪声,还额外利用一个在带噪图片上训练好的分类器,计算出指向“目标类别”概率增加最快的梯度方向,然后将这个梯度“添加”到去噪方向上,从而“引导”生成过程向着目标类别更明确、特征更显著的方向进行。
然而,分类器引导存在以下几个核心问题,这也是本文的主要动机:
额外的模型和训练成本:需要单独训练一个分类器。更麻烦的是,这个分类器必须能在不同噪声水平的图片上进行准确分类,这意味着它需要在扩散过程中的所有中间带噪样本
z_t上进行训练,这大大增加了训练的复杂性和成本。你不能简单地拿一个在干净图片上预训练好的分类器来用。对“引导”本质的质疑:分类器引导的采样过程,可以被看作是利用分类器的梯度来“攻击”生成样本,使其在分类器眼中看起来更像目标类别。这引出了一个问题:这种方法提升的基于分类器的评估指标(如Inception Score, FID),究竟是因为生成质量真的提高了,还是因为它本质上是一种针对评估系统的“对抗性攻击”?
简化流程的需求:研究者们希望找到一种更“纯粹”、更内生的方法。是否可以不依赖任何外部模型,仅凭扩散模型自身就完成高质量的引导?
因此,本文的目标就是摆脱分类,设计一种分类器无关的引导方法,来解决上述所有问题。
背景知识:扩散模型与分类器引导
要理解本文,首先需要了解两个关键背景。
扩散模型基础
扩散模型通过两个过程进行建模:
前向过程(Forward Process):从一张干净的图片
x_0开始,逐步、多次地向其中添加高斯噪声,直到图片变成纯粹的噪声x_T。这个过程的每一步都是一个固定的、可计算的马尔可夫链。反向过程(Reverse Process):模型学习如何“逆转”这个加噪过程。从纯噪声
x_T出发,模型在每一步预测出应该如何去噪,从而逐步恢复出原始的、干净的图片x_0。
在实践中,模型(通常是一个U-Net架构)在任意时间步 t 接收带噪样本 x_t 和时间步 t 的编码,其任务是预测出添加到 x_0 中以得到 x_t 的原始噪声 ε。这个预测出的噪声我们记为 ε_θ(x_t, t)。对于条件生成,模型还会接收一个条件信息 c(如类别标签),即 ε_θ(x_t, c, t)。
分类器引导 (Classifier Guidance)
分类器引导在采样(反向过程)时修改了模型的预测。原本的预测分数(score,与噪声 ε 成正比)是 ε_θ(x_t, c)。分类器引导将其修改为:
这里:
是条件扩散模型的原始噪声预测。
是在带噪图片 x_t 上训练的分类器模型,表示 x_t 属于类别 c 的概率。
是该概率的对数关于输入 x_t 的梯度。这个梯度指向了能让分类器更确信 x_t 属于类别 c 的方向。
w是引导强度(guidance scale/strength),控制着分类器梯度的影响大小。w=0 时即为无引导。
这个公式的直观解释是:在扩散模型原本的去噪方向上,额外叠加一个“让样本更像类别 c”的力。
分类器无关引导 (Classifier-Free Guidance)
这是本文的核心贡献。作者巧妙地利用贝叶斯定理,从数学上推导出了一个等效于分类器引导但不需要分类器的形式。

核心思想与推导
分类器引导的核心是梯度项 ∇ log p(c|x_t)。根据贝叶斯定理:
取对数后得到:
对 x_t 求梯度,log p(c) 是常数项,可以忽略:
这里的关键洞察在于:
∇_{x_t} \log p(x_t|c)正是条件扩散模型要学习的分数(score)。∇_{x_t} \log p(x_t)正是无条件扩散模型要学习的分数。
将这个关系代入分类器引导的公式:
因此,作者提出,我们可以直接训练一个条件模型 ε_θ(x_t, c) 和一个无条件模型 ε_θ(x_t),然后在采样时将它们的预测结果进行组合。
训练细节
如何高效地同时训练条件和无条件模型?作者提出了一个极为简洁的方案,也是该方法广受欢迎的原因之一:
使用单一模型,随机丢弃条件:在训练一个条件扩散模型
ε_θ(x_t, c)时,以一定的概率p_uncond(例如10%或20%)将条件c替换为一个特殊的空标签(null token, 记作 Ø)。当输入为
(x_t, c)时,模型学习的是条件去噪。当输入为
(x_t, Ø)时,模型学习的是无条件去噪。
这样,同一个神经网络 ε_θ 就同时学会了两种能力,而无需增加任何模型参数或复杂的训练流程。这在代码上只是一个简单的随机替换操作。
采样过程
在采样时,每一步都需要进行两次模型前向传播:
一次使用目标条件
c,得到条件预测ε_θ(x_t, c)。一次使用空标签
Ø,得到无条件预测ε_θ(x_t, Ø)。
然后,根据以下公式计算最终的引导后噪声预测:
其中 w 依然是引导强度。这个公式也可以写成更直观的形式:
这个形式的直观解释是:
ε_θ(x_t, Ø)是无条件的预测,代表了生成通用、自然图像的方向。(ε_θ(x_t, c) - ε_θ(x_t, Ø))是条件和无条件预测的差值,可以看作是“从通用图像转向特定类别c”的方向向量。(w+1)控制着向特定类别c靠拢的强度。当w=0时,公式变为ε_θ(x_t, c),即标准的条件生成。注意,本文的公式w从0开始,当w>0时即有引导效果。
通过调整 w,就可以在高质量、低多样性(w 较大)和高多样性、较低质量(w 较小)之间平滑过渡。
实验与结果
IS/FID 权衡曲线:论文在ImageNet 64x64和128x128数据集上进行了实验。结果显示,随着引导强度
w的增加,Inception Score (IS) 显著提高,而FID分数先下降后上升,呈现出经典的“质量-多样性”权衡曲线。这证明了分类器无关引导成功复现了分类器引导的效果。SOTA 性能:在128x128 ImageNet上,该方法取得了当时最先进的(SOTA)结果,其FID分数优于之前的分类器引导方法(ADM-G),并在高引导强度下,IS和FID同时优于BigGAN-deep的最佳IS点。
p_uncond的影响:实验发现,p_uncond取一个较小的值(如0.1或0.2)就足够了。这表明模型不需要花费大量能力去学习无条件生成,就可以提供有效的引导信号。采样步数的影响:和所有扩散模型一样,增加采样步数
T可以提升生成质量,但会增加时间成本。作者发现T=256步就能在速度和质量上取得很好的平衡。
讨论与影响
优点:
简洁性:训练和实现都非常简单,只需在训练时随机丢弃条件即可。
纯粹性:完全摆脱了对外部模型的依赖,证明了扩散模型自身能力的强大。
消除了“对抗性”的疑虑:性能的提升来自于生成模型内部的调整,而非针对外部评估系统的优化。
缺点:
采样速度:由于每一步都需要两次前向传播,采样时间大约是无引导或分类器引导(如果分类器很小)的两倍。这是该方法最主要的代价。
深远影响: 分类器无关引导(Classifier-Free Guidance, CFG)几乎立即成为了条件扩散模型领域的黄金标准。从文本到图像生成的DALL-E 2, Imagen, Stable Diffusion,到各种其他条件的生成任务,CFG都是核心组件之一。它极大地推动了扩散模型在实际应用中的落地和发展,因为它提供了一个可靠、易用且效果拔群的控制旋钮。
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion (2023)
输入 (Input):
机器人当前的观测
O(通常是来自摄像头的连续图像序列)。
输出 (Output):
机器人未来一小段时间的动作序列 (例如,未来1秒内每隔0.1秒的末端执行器目标位姿)。
解决的任务 (Task):
机器人模仿学习 (Robot Imitation Learning)。该模型从专家演示数据中学习一个控制策略。其核心创新在于,它将策略建模为在动作空间上的扩散过程,能够有效处理多模态动作(即在同一状态下有多种合理的动作选择),解决了传统方法中模式崩溃或模式平均的问题,使训练更稳定,策略更鲁棒。
核心思想
这篇论文提出了一种全新的机器人模仿学习框架,名为 Diffusion Policy (扩散策略)。其核心思想是,将机器人策略的构建过程,建模为一个在动作空间上的条件化去噪扩散过程 (conditional denoising diffusion process)。
传统的策略通常直接从观测映射到动作 (显式策略),或者学习一个能量函数来评估动作的好坏 (隐式策略)。而 Diffusion Policy 另辟蹊径,它不直接输出动作,而是学习一个能够指导“噪声动作”逐步“去噪”并最终收敛到专家演示动作的梯度场。在推理时,策略从一个完全随机的噪声动作开始,通过多次迭代优化,沿着学习到的梯度方向,逐步将其精炼成一个高质量、符合任务要求的动作序列。
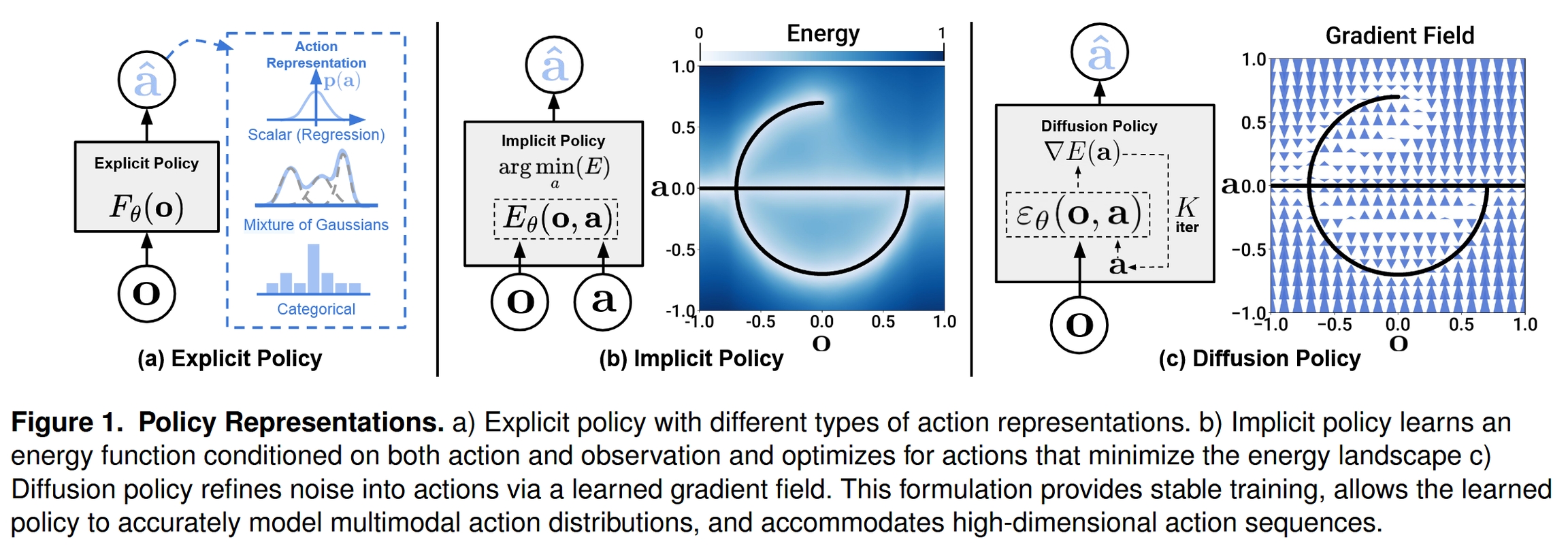
通过这种方式,Diffusion Policy 能够有效继承扩散模型的强大生成能力,从而在处理机器人学习中的经典难题,如 动作多模态、高维动作空间 和 训练不稳定性 等方面,展现出卓越的性能。
研究动机
机器人模仿学习 (Imitation Learning) 旨在让机器人通过观察专家演示来学习技能。尽管想法简单,但在实践中面临诸多挑战,现有方法存在明显瓶颈,这也是本文的主要动机:
无法有效处理多模态分布 (Multimodality):在许多任务中,同一个状态下存在多个同样有效的动作。例如,推动一个T形物块,可以从左侧推,也可以从右侧推。传统的显式策略,如直接回归 (BC) 或高斯混合模型 (GMM),很难精确地表示这种“多选一”的情形,常常导致模式崩溃 (只学会一种方式) 或模式平均 (输出一个无效的中间动作)。
高维动作序列预测困难:为了保证动作的平滑性和时间一致性,预测未来一小段 动作序列 通常比预测单个动作更有效。但这使得输出空间维度急剧增加,给传统方法带来了巨大挑战。例如,隐式策略 (如 IBC) 在高维空间中进行有效的负采样和优化非常困难且不稳定。
训练不稳定:基于能量的模型 (EBMs),如 IBC,虽然理论上能处理多模态,但其训练依赖于 InfoNCE 损失函数。该函数需要进行 负采样 来估计一个难以计算的归一化常数 (配分函数)。不准确或低效的负采样是导致其训练过程非常不稳定、对超参数敏感的主要原因。
Diffusion Policy 正是为了克服以上挑战而设计的。它天然地支持多模odal输出,能够很好地扩展到高维空间,并且通过学习 分数函数 (score function) 的梯度,巧妙地绕过了计算配分函数的难题,从而实现了非常稳定的训练。
模型架构与方法
Diffusion Policy 的核心是学习一个条件化的噪声预测网络 ε_θ(O, A, k),其中 O 是观测,A 是带噪声的动作,k 是去噪的时间步。该网络的目标是预测在动作 A 中添加的噪声。
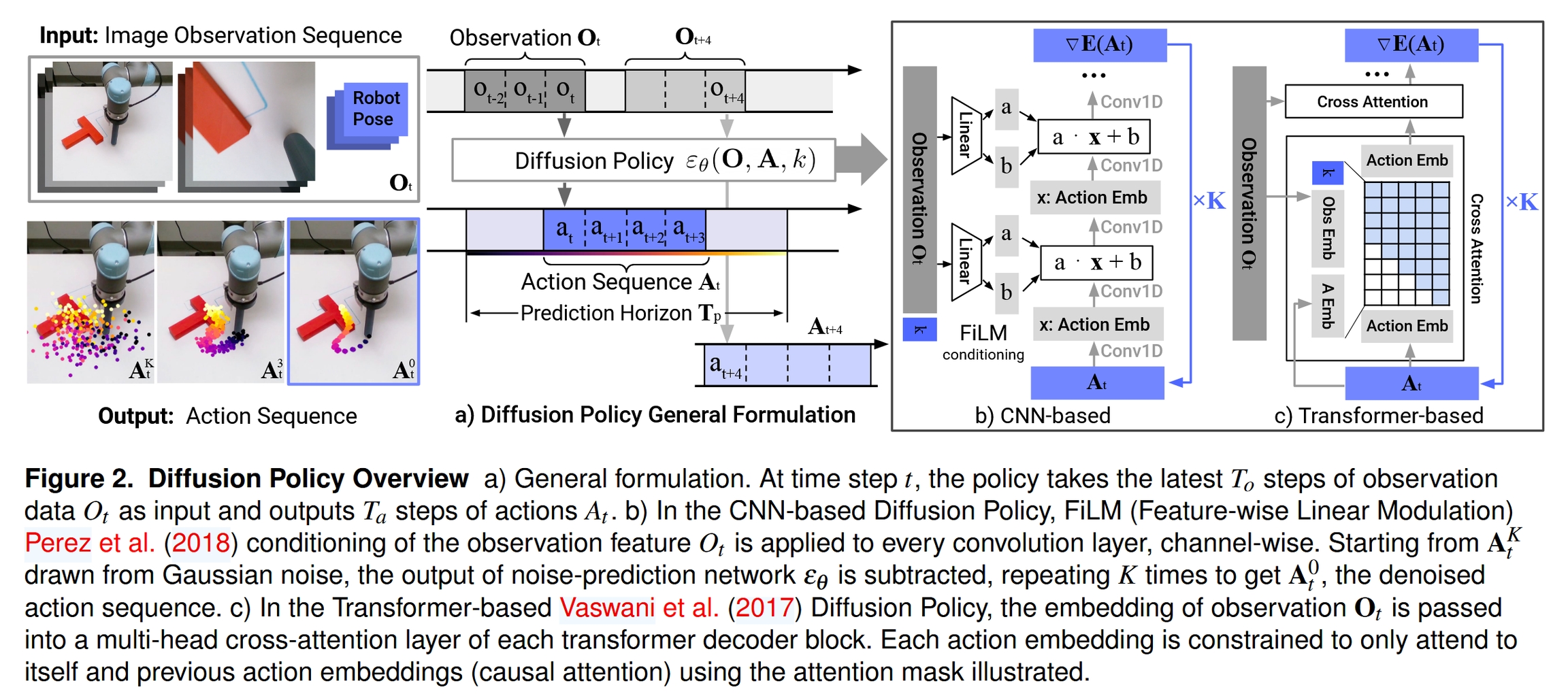
1. 扩散策略的基本框架
训练过程:
从专家数据集中随机采样一个真实的动作序列
A0和对应的观测序列O。随机选择一个扩散时间步
k。从高斯分布中采样一个噪声
ε。将噪声添加到真实动作上,生成带噪动作
Ak = A0 + ε。训练噪声预测网络
ε_θ,使其在给定观测O和带噪动作Ak的条件下,能够预测出原始添加的噪声ε。损失函数为:
推理 (动作生成) 过程:
从一个标准高斯分布中采样一个纯噪声作为初始动作序列
AK。进行
K次迭代,从k=K到k=1。在每一步
k,使用训练好的网络ε_θ预测噪声,并根据以下公式更新动作序列,逐步去噪:这里的函数
f定义了具体的去噪步骤,通常遵循 DDPM 或 DDIM 的更新规则。最终得到的A0就是策略生成的动作序列。
2. 网络架构选项
论文探索了两种主流的神经网络架构来实现噪声预测器 ε_θ:
CNN-based Diffusion Policy (基于CNN的扩散策略):
它采用了一个一维时间卷积网络 (Temporal CNN) 来处理动作序列。
视觉观测
O经过一个视觉编码器 (如 ResNet) 提取特征后,通过 FiLM (Feature-wise Linear Modulation) 层注入到CNN的每一层中。FiLM 动态地调整CNN层的激活值,从而实现对动作生成的条件控制。这种架构计算高效,对于大多数任务效果良好,但其卷积的感应偏差可能使其难以学习高频变化的动作。
Transformer-based Diffusion Policy (基于Transformer的扩散策略):
它将动作序列中的每个动作步视为一个 token。
视觉观测特征通过 交叉注意力 (Cross-Attention) 机制融入到 Transformer Decoder 的每一层中。
动作 token 之间使用 因果自注意力 (Causal Self-Attention),确保在预测某个时间步的动作时,只能关注到它自身和它之前的动作,这符合时序逻辑。
这种架构表达能力更强,尤其擅长处理需要高频控制或复杂时间依赖的任务,但训练起来可能对超参数更敏感。
3. 关键技术贡献
为了将扩散模型成功应用于真实的机器人系统,论文提出了一系列关键的技术设计:
闭环动作序列预测与滚动时域控制 (Closed-loop Action-sequence Prediction & Receding Horizon Control):
策略一次性预测未来
Tp步的动作序列,但只执行其中的前Ta步 (Ta < Tp)。然后,机器人获取新的观测,并基于新观测重新规划下一段动作序列。
这种 滚动时域控制 (Receding Horizon Control) 的方式,既通过序列预测保证了动作的 时间连贯性,又通过闭环重规划保证了策略对环境变化的 鲁棒性和响应性。
高效的视觉条件化 (Visual Conditioning):
论文将视觉观测
O作为 条件 输入,而不是将其与动作A一起作为联合分布的一部分来建模。这意味着在整个去噪过程中,视觉特征只需要提取一次,极大地降低了计算开销,使得实时推理成为可能。
时间序列扩散 Transformer (Time-series Diffusion Transformer):
这是上文提到的基于 Transformer 的架构,专门为处理机器人动作序列设计,有效克服了CNN模型的过平滑问题。
技术细节与关键发现
处理多模态动作分布:
扩散策略的随机性来源有二:1) 初始采样完全随机的噪声
AK;2) 每步去噪过程中可以添加少量随机噪声 (Langevin Dynamics)。这使得推理过程能够探索动作分布的不同模式。例如,对于推物块任务,初始噪声的不同可能导致最终收敛到“从左推”或“从右推”这两条完全不同的有效轨迹上,而不会产生无效的中间动作。
与位置控制的协同作用 (Synergy with Position Control):
论文发现,Diffusion Policy 在使用 位置控制 (预测末端执行器的目标位姿) 时表现远超 速度控制。
这与许多先前工作倾向于使用速度控制的结论相反。作者推测,这是因为位置控制下的动作多模态性更强(例如,在同一位置等待是重复的相同位置指令),而 Diffusion Policy 恰好擅长处理此问题。同时,位置控制受复合误差影响较小,更适合动作序列预测。
训练稳定性:
这是相较于 IBC 等隐式策略的核心优势。IBC 训练需要最小化 InfoNCE 损失:
分母中的求和项需要对大量 负样本
a_neg进行评估,这既耗时又不稳定。Diffusion Policy 学习的是对数概率的梯度,即 分数函数
∇_a log p(a|o)。这个梯度与归一化常数无关:因此,它完全避免了对负样本的依赖和对归一化常数的估计,训练过程因此变得异常稳定。
推理加速:
完整的扩散过程可能需要上百甚至上千步,对于机器人实时控制来说太慢。
论文采用了 DDIM (Denoising Diffusion Implicit Models) 的采样方法,它允许在推理时使用远少于训练的步数(例如,训练100步,推理仅需10-16步),在保证生成质量的同时,将推理延迟降低到 0.1 秒左右,满足了实时控制要求。
实验评估
论文在4个不同的机器人操作基准平台、共计15个任务上进行了系统性评估,涵盖了模拟和真实世界、从简到难的各种场景。
模拟实验:在 Robomimic、Push-T 等基准上,无论是基于状态还是基于图像的策略,Diffusion Policy 的性能都 全面超越 了现有的SOTA方法 (如 LSTM-GMM, BET, IBC),平均成功率提升了 46.9%。
真实世界实验:论文在多个真实的机器人任务上展示了其强大的泛化能力和鲁棒性,包括:
Push-T:在复杂的、需要分阶段的真实推物块任务中,成功率高达95%,远超基线。
Mug Flipping (翻杯子):处理复杂的6自由度旋转,成功率90%。
Sauce Pouring/Spreading (倒酱/抹酱):与非刚性物体 (酱料) 交互,并执行周期性动作。
Bimanual Tasks (双手任务):如打蛋、铺垫子、叠衣服等,证明了该框架可以轻松扩展到更复杂的多臂协调场景。
实验结果有力地证明,Diffusion Policy 不仅在理论上具有优越性,在实践中也同样强大和可靠。
结论
Diffusion Policy 成功地将扩散模型的强大生成能力引入到机器人策略学习中,为模仿学习领域提供了一个全新的、性能卓越的范式。它通过将策略建模为条件化去噪过程,优雅地解决了长期困扰机器人学习的 多模态、高维动作和训练稳定性 问题。论文通过全面的实验,不仅验证了模型框架的有效性,还提供了一系列关键的技术洞见(如滚动时域控制、位置控制的优势等),为在真实机器人上部署强大的学习策略铺平了道路。这项工作标志着利用生成模型进行机器人行为学习的一个重要里程碑。
GNM: A General Navigation Model to Drive Any Robot (2023)
输入 (Input):
机器人当前的观测图像 (
Ot)。一个指定导航终点的目标图像 (
OG)。体现上下文 (Embodiment Context): 机器人过去几帧的连续观测图像,用于让模型隐式推断当前机器人的物理特性(如摄像头高度、速度等)。
输出 (Output):
一系列归一化的未来航点 (waypoints),这是一个抽象的、与机器人无关的动作表示。
一个预测的到达目标所需的时间距离。
解决的任务 (Task):
通用的、零样本的机器人视觉导航。通过在一个包含多种机器人、多种环境的异构数据集上进行训练,GNM旨在学习一个“全能策略”,能够直接部署到全新的、未曾见过的机器人上,无需任何微调即可完成导航任务,打破了机器人领域“一个模型对应一个机器人”的碎片化困局。
Motivation
在机器人学领域,尤其是在视觉导航方面,存在一个长期存在的挑战,研究人员称之为 “碎片化” (fragmentation)。具体来说,这个问题体现在以下几个方面:
数据隔离: 绝大多数导航策略(policy)都是为特定的机器人平台、特定的传感器配置和特定的环境而设计的。研究人员通常会为自己的机器人收集一个专属的数据集,并在此基础上训练模型。这导致了大量小型、孤立的数据集,彼此之间难以兼容和复用。
缺乏通用性: 由于模型是在高度特定的数据上训练的,其泛化能力非常有限。当机器人平台更换(例如,从一个轮式机器人换到一个四足机器人)、传感器参数改变(例如,摄像头安装高度或视角不同)或者进入一个全新的环境时,原有的导航策略往往会失效,需要重新收集数据和训练。
阻碍领域发展: 这种“碎片化”的现状阻碍了机器人领域像自然语言处理(NLP)和计算机视觉(CV)那样取得飞速发展。在那些领域,研究人员可以利用像 ImageNet、维基百科这样的大规模、多样化的“一次性收集,多次使用”的数据集来训练强大的基础模型(Foundation Models),例如 ResNet、BERT、GPT 等。这些预训练模型可以作为各种下游任务的通用起点,极大地加速了技术迭代。机器人领域由于缺乏这样的通用数据集和基础模型,进展相对缓慢。
因此,这篇论文的核心动机是 打破这种“碎片化”的困局。作者们希望探索一个问题:我们是否可以像 NLP 和 CV 领域一样,通过 聚合来自多个不同机器人、不同环境的异构数据集,训练一个单一的、通用的导航模型(作者称之为 “omnipolicy”,即全能策略)?
这个全能策略的最终目标是:
能够有效地从多样化的数据中学习到通用的导航知识(例如,如何识别可通行的路径、如何避开障碍物、如何朝向目标前进)。
不仅能在其见过的机器人上表现出色,还能以 零样本 (zero-shot) 的方式直接部署到 全新的、未曾见过的机器人 上,并在各种复杂的环境中成功导航,而无需任何额外的数据收集或微调。
Architecture
为了实现上述目标,作者设计了一个名为 GNM (General Navigation Model) 的模型。其核心架构基于一个目标条件策略(goal-conditioned policy),但为了适应异构数据和多机器人部署,引入了两个关键的设计。
模型的整体架构可以参考论文中的图 2,主要由以下几个部分组成:
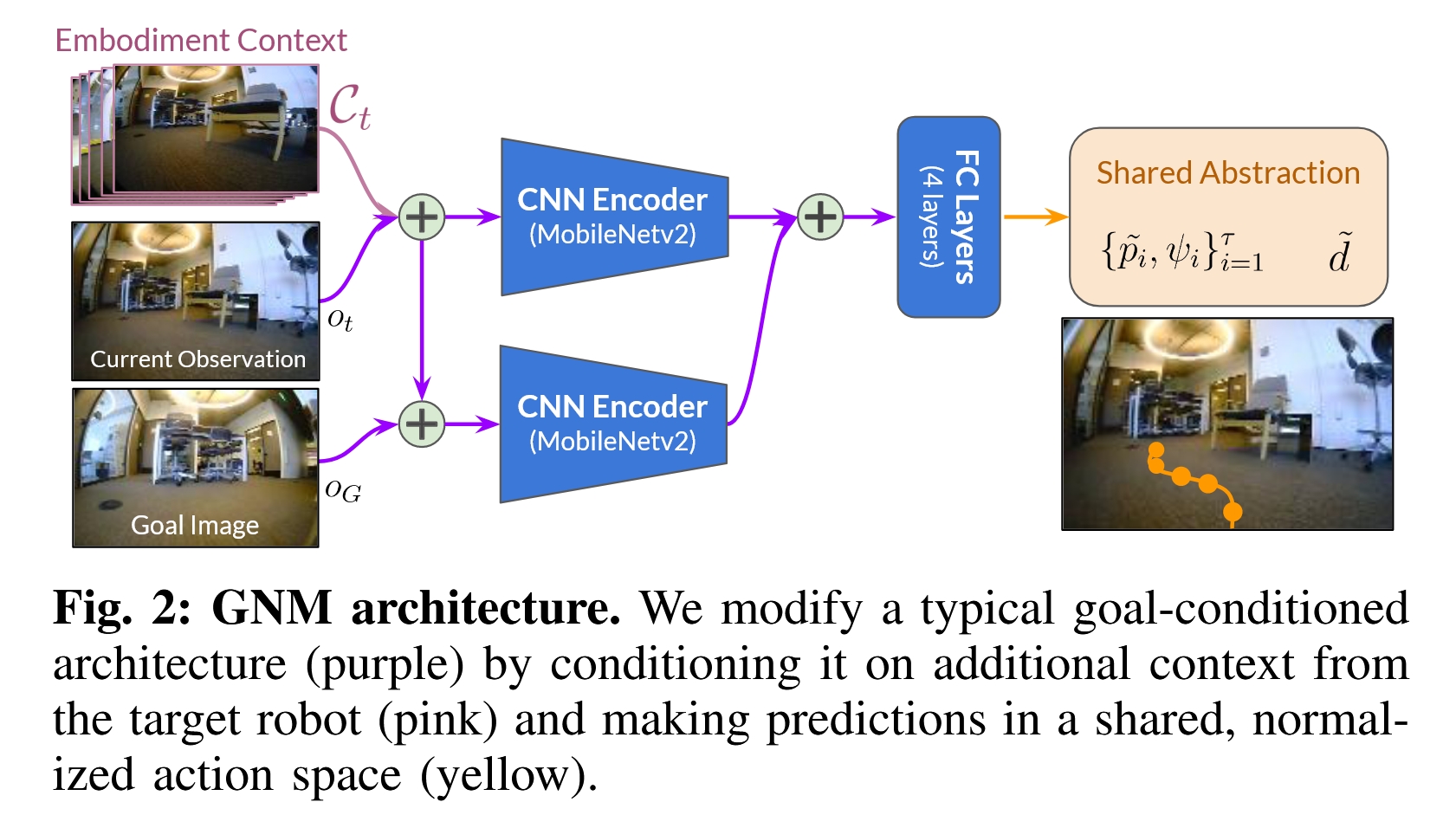
输入 (Inputs):
当前观测 (Current Observation, Ot): 机器人当前视角拍摄的 RGB 图像。
目标图像 (Goal Image, OG): 在目标位置拍摄的一张 RGB 图像,用于指定导航终点。
体现上下文 (Embodiment Context, Ct): 这是 GNM 的一个关键创新。它由机器人过去
k帧的连续观测图像堆叠而成。这个上下文的作用是让模型能够 隐式地推断 出当前所控制的机器人的一些物理属性和动态特性,例如摄像头的安装高度、机器人的转弯半径、移动速度等,而无需手动指定这些参数。
编码器 (Encoders):
模型采用了一种 条件式架构 (conditional architecture)。它使用两个独立的 MobileNetv2 编码器。
一个编码器负责处理“当前状态”,即融合了 当前观测 (Ot) 和 体现上下文 (Ct) 的信息。
另一个编码器负责处理 目标图像 (OG)。
这种分离处理允许模型学习到更具泛化性的表征。
融合与预测 (Fusion and Prediction):
两个编码器输出的特征向量(embeddings)会被拼接(concatenate)在一起。
拼接后的特征向量被送入几层全连接网络(MLP)中。
最后,网络会输出两个预测头(prediction heads)的结果。
输出 (Outputs):
归一化的未来航点 (Normalized Future Waypoints): 模型预测出一系列(例如,未来5个)归一化的航点
{p'_i, ψ'_i},其中p'是位置,ψ'是偏航角。这是一个 共享的、抽象的动作空间,是实现跨机器人泛化的核心。到目标的时间距离 (Temporal Distance): 预测一个标量
d,表示从当前位置到达目标位置所需的时间。这个值可以被上层规划器用作路径成本的估计。
技术细节
为了让 GNM 能够成功地从异构数据中学习并泛化到新机器人上,作者采用了一系列关键的技术细节。
异构导航数据集 (Heterogeneous Navigation Dataset)
GNM 的成功离不开一个大规模、多样化的数据集。作者聚合了来自 6 种完全不同的机器人 的导航数据,总时长超过 60 小时。
这些机器人形态各异,包括:TurtleBot2(差分驱动轮式机器人)、Clearpath Jackal/Spot(四足/轮式机器人)、RC Car(遥控赛车)、ATV(全地形车)等。
它们的动态特性差异巨大,最高速度从 0.5m/s 到 10m/s 不等。
数据采集环境也极其多样,涵盖了办公室、走廊、市郊、野外小径、大学校园等室内外场景。
这种数据的 异构性 (heterogeneity) 是训练出通用模型的关键,它迫使模型学习机器人和环境背后共通的导航原理,而不是去过拟合某个特定平台的特性。
共享的抽象动作空间 (A Shared Abstraction Across Robots)
直接让模型输出底层控制指令(如轮速、转向角)是极其困难的,因为不同机器人的指令空间和动态范围天差地别。
GNM 的解决方案是预测一个 归一化的中层动作表示,即未来航点。
归一化: 模型预测的航点
p'是被一个机器人专属的缩放因子α(通常是该机器人的最大速度)归一化后的结果。这样,无论对于慢速的 TurtleBot 还是高速的 ATV,模型学习的目标范围都是一致的,降低了学习难度。解耦: 在部署时,一个简单的、机器人专属的底层控制器(如 PID 或 MPPI)负责将这些归一化的航点 “反归一化”,并将其转换为机器人可以执行的底层电机指令。这成功地将 高层的视觉导航决策 与 底层的平台专属控制 解耦开来。
体现上下文 (Embodiment Context)
当 GNM 部署到一个新机器人上时,它需要一种方式来“感知”自己正在控制一个什么样的机器人。
“体现上下文” (
Ct) 正是为此设计的。通过观察过去几帧的图像序列,模型可以推断出很多信息。例如:如果图像在转弯时变化剧烈,说明机器人转弯半径小。
如果地面纹理移动得很快,说明机器人速度快。
如果物体的透视变化明显,可以推断出摄像头的高度。
实验证明,使用连续的 时间上下文 (temporal context) 比使用一组固定的 静态上下文 (static context) 效果更好,因为它包含了动态信息。
训练与部署 (Training and Deployment)
训练: 模型采用监督学习的方式进行训练。训练数据对通过在同一条轨迹中采样“正样本”(可达的目标)和在不同轨迹中采样“负样本”(不可达的目标)来构建。动作头只在正样本上训练,而距离头在所有样本上训练,使用 L2 回归损失。
部署: 在实际应用中,GNM 策略通常与一个 拓扑地图 系统(如 ViNG)结合使用。系统会构建一个由过往观测图像为节点的图。GNM 预测的时间距离
d用来估计图中节点间的边权重(通行成本)。当给定一个目标图像时,系统使用 Dijkstra 等图搜索算法在拓扑地图上规划一系列子目标,然后 GNM 策略负责驱动机器人依次导航到这些子目标。
实验与结果 (Experiments and Results)
零样本泛化: GNM 在 4 种不同的机器人 上进行了测试,其中包括 2 个全新的机器人(一个基于 Roomba 的 Vizbot 和一个大疆 Tello 无人机),并且 没有进行任何微调。结果显示,单一的 GNM 模型在所有平台上都取得了优异的性能,显著超过了仅在单一数据集上训练的策略。尤其值得注意的是,尽管 GNM 从未见过任何来自空中机器人的数据,它依然能成功控制无人机进行水平面导航。
数据多样性的价值: 实验表明,随着训练数据集中机器人类型的增加(从 2 种增加到 4 种,再到 6 种),GNM 在未见过的机器人和环境中的导航成功率也随之稳步提升。这有力地证明了 数据异构性对于提升泛化能力至关重要。
鲁棒性: GNM 对机器人的物理和传感器退化表现出很强的鲁棒性。在模拟轮胎损坏(影响动力学)、摄像头位置被扰动、转向能力被限制等场景下,GNM 能够通过调整路径来补偿这些退化,而单一领域的模型则很容易失败。
总而言之,GNM 通过聚合异构数据集,并巧妙地设计了 共享的抽象动作空间 和 体现上下文 这两个关键模块,成功训练出了一个具有强大零样本泛化能力的通用视觉导航模型。这项工作为机器人领域构建可复用的、大规模数据集和通用的预训练导航模型提供了一个切实可行的方向和范例。
NoMaD: Goal Masking Diffusion Policies for Navigation and Exploration (2023)
输入 (Input):
机器人当前的观测 (连续图像序列)。
一个可选的目标图像。
一个目标掩码 (Goal Mask),用于控制模型是否使用目标图像。
输出 (Output):
机器人未来一小段时间的动作序列。
解决的任务 (Task):
统一的机器人导航与探索。NoMaD通过“目标掩码”技术,将两种核心的机器人行为集成到一个单一模型中:
当提供目标图像时,它执行目标导向导航。
当不提供目标图像(或掩码生效)时,它执行自主探索。
它结合了Diffusion Policy的多模态能力,创建了一个既高效又能在多种任务模式间无缝切换的强大导航框架。
核心思想
这篇论文的核心贡献在于提出了一个名为 NoMaD 的 单一、统一的 机器人导航模型。该模型首次将 目标掩码 (Goal Masking) 技术与 扩散策略 (Diffusion Policy) 相结合,使其能够在一个模型内同时处理两种截然不同的任务:
目标导向导航 (Goal-Conditioned Navigation): 当给定一个目标图片时,机器人能够高效地规划路径并到达该目的地。
无向探索 (Undirected Exploration): 当没有明确目标时,机器人能够在未知环境中自主、安全地进行探索,发现新区域。
通过这种统一的框架,NoMaD 不仅在性能上超越了以往那些需要多个独立模型(例如,一个用于生成子目标,另一个用于导航)的复杂系统,而且模型更小、计算效率更高,可以直接部署在算力有限的机器人上。
研究动机
在现实世界的机器人应用中,尤其是在陌生环境下,机器人导航面临一个根本性的挑战:它既需要 探索未知 的能力,又需要 到达已知目标 的能力。
传统方法的局限性:
分离式系统 (Separate Systems): 过去的方法通常采用分离式设计。例如,使用一个生成模型(如 VAE 或 Diffusion Model)来提出可能的探索子目标(subgoal),然后再由一个独立的目标导向导航策略去执行。这种方法流程复杂,需要训练和协调多个模型,并且生成高维数据(如图片)作为子目标非常耗时且计算量大。
表达能力不足: 传统的确定性策略(例如,直接回归动作)难以对复杂的、多模态的动作分布进行建模。比如,在一个十字路口,向左、向右、向前直行都可能是合理的探索行为,一个好的策略应该能同时表示这些可能性。确定性策略往往只能输出这些可能动作的平均值,导致机器人行为犹豫不决或在路口卡住。
泛化性问题: 在仿真中训练的探索策略往往难以迁移到真实世界,而基于传统几何方法(如Frontier-based exploration)的探索又依赖于高质量的地图构建,在视觉信息不可靠时效果不佳。
NoMaD 的出发点: 作者认为,一个设计精良、表达能力足够强的单一模型,应该能够同时学习到这两种行为模式。目标导向和无向探索在底层行为(如避障、沿走廊行进)上有很多共性。通过在一个统一的模型中联合训练这两种任务,模型可以学习到更鲁棒、更泛化的导航先验知识。
模型架构与技术细节
NoMaD 的模型架构如论文图 2 所示,它主要由视觉编码器、目标掩码模块和扩散策略解码器三部分组成。
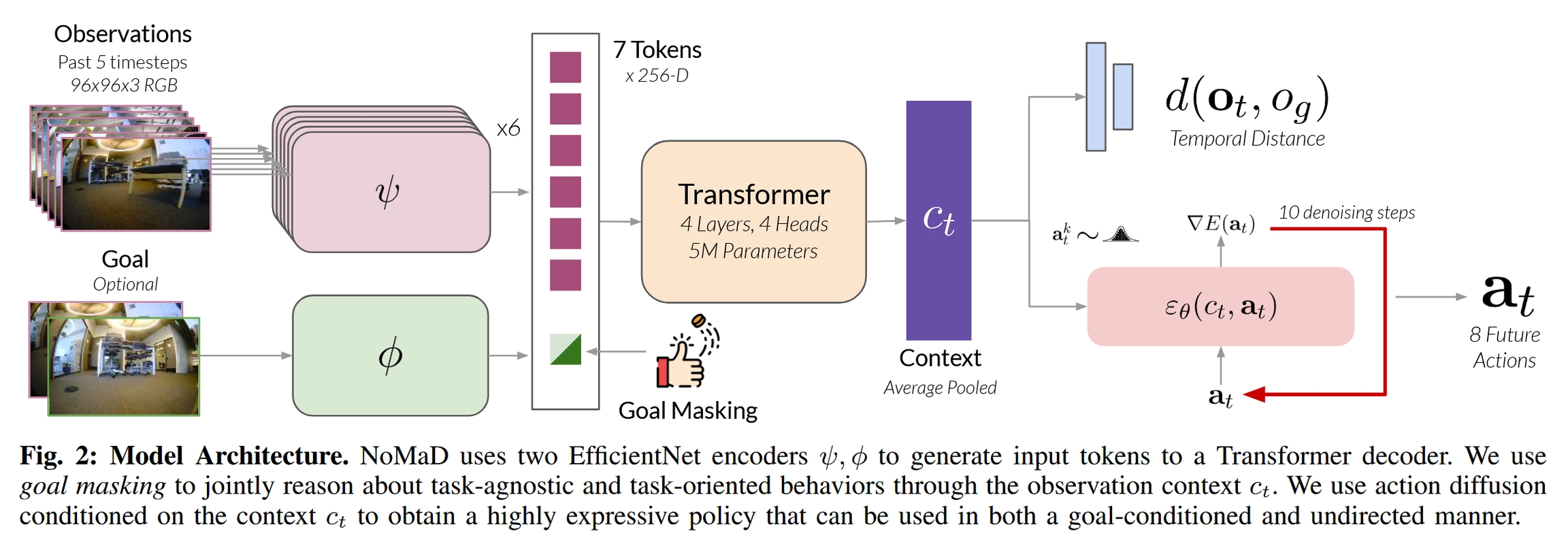
1. 视觉编码器 (Visual Encoder Backbone):
模型采用了 ViNT (Visual Navigation Transformer) 作为其主干网络。ViNT 本身就是一个强大的视觉导航模型。
它使用 EfficientNet 分别对机器人当前的连续观测图像序列 (过去5帧) 和可选的目标图像进行编码,将每张图片转换成一个特征向量(token)。
这样,输入就被转换成了一组 token:多个代表历史观测的 token,和一个代表目标的 token。
2. 核心机制 1:目标掩码 (Goal Masking): 这是 NoMaD 实现任务切换的关键。
原理: 它通过一个简单的二进制掩码
m来控制 Transformer 的注意力机制是否“看到”目标 token。具体实现:
当需要进行 目标导向导航 时,设置掩码
m = 0。此时,Transformer 的自注意力层可以正常处理包括目标 token 在内的所有输入 token。模型会综合历史观测和目标信息,生成一个导向目标的上下文向量c_t。当需要进行 无向探索 时,设置掩码
m = 1。这个掩码会阻止注意力机制访问目标 token。因此,模型生成的上下文向量c_t只依赖于历史观测,与任何特定目标无关,从而驱动机器人进行探索行为。
训练: 在训练过程中,以 50% 的概率随机选择使用或不使用目标掩码 (即
p_m = 0.5)。这使得模型被强制学习在两种模式下都能做出合理的决策,从而实现了两种能力的联合训练。
3. 核心机制 2:扩散策略 (Diffusion Policy): 这是 NoMaD 能够生成复杂、多模态动作分布的关键。
为什么用扩散模型: 传统的回归模型输出一个确定的动作序列,无法表示多模态性。而扩散模型通过一个迭代的去噪过程,可以从一个简单的噪声分布中恢复出复杂的数据分布。在这里,它被用来建模给定上下文
c_t后,未来动作序列a_t的条件概率分布p(a_t|c_t)。去噪过程: 模型的核心是一个噪声预测网络
ε_θ。该网络输入带有噪声的动作序列a_t^k、当前的去噪步数k以及之前从 Transformer 获得的上下文向量c_t,然后预测出施加在该动作序列上的噪声。去噪过程遵循以下迭代公式:
其中
a_t^k是第k步的带噪动作,ε_θ是噪声预测网络,c_t是条件信息。通过K步(论文中为10步)迭代,就可以从一个纯高斯噪声a_t^K中采样得到一个干净、合理的未来动作序列a_t^0。优势: 这个过程允许模型在探索模式下(例如在路口),从动作分布中采样出多个不同的、但都合理的轨迹(如左转或右转),从而实现了真正的多模态行为预测。
4. 训练损失 (Training Loss): 模型是端到端训练的,其损失函数包含两部分:
第一项 (扩散损失): 这是标准的扩散模型损失,即预测的噪声
ε_θ与真实添加的噪声ε_k之间的均方误差(MSE)。第二项 (距离预测损失): 类似于 ViNT,模型还预测当前观测与目标图像之间的时间距离(即需要多少步才能到达),并与真实距离计算均方误差。这个辅助任务有助于模型更好地理解目标和当前状态的关系。
λ是一个超参数,用于平衡两个损失。
实验与结果
论文通过在6个真实世界的室内外环境中进行的大量实验,验证了 NoMaD 的性能。
主要发现:
探索性能显著提升 (Table I): 在无向探索任务中,NoMaD 的成功率达到了 98%,远超之前的 SOTA 模型 Subgoal Diffusion (77%)。同时,它的碰撞率极低 (0.2),而 Subgoal Diffusion 的碰撞率是 1.7。这表明 NoMaD 的探索行为既高效又安全。
模型轻量高效: NoMaD 的模型参数量 (19M) 远小于 Subgoal Diffusion (335M),相差超过 15倍。这使得 NoMaD 能够轻松地在机器人板载计算机(如 NVIDIA Jetson Orin)上实时运行,而后者需要强大的云端或桌面级 GPU 支持。
统一模型性能不妥协 (Table II): 实验证明,统一训练的 NoMaD 模型,在执行探索任务时,其性能与专门为探索训练的扩散策略模型相当;在执行导航任务时,其性能也与专门为导航训练的 ViNT 模型相当。这证明了联合训练不仅没有损害各自任务的性能,反而可能因为共享表征而带来了好处。
多模态行为的可视化 (Figure 5): 论文可视化了不同模型在路口的动作预测。结果显示,只有 NoMaD 能够清晰地预测出两个分离的、有效的路径(左转和右转)。而其他模型,如 Autoregressive 模型,虽然理论上可以表示多模态,但实际上预测的仍然是单一的、模糊的平均动作。这直观地证明了扩散策略在建模复杂动作分布上的优越性。
总结与未来展望
NoMaD 是一个里程碑式的工作,它成功地将目标掩码和扩散策略结合,创建了一个既能探索又能导航的单一统一模型。它不仅在性能和安全性上超越了现有方法,还极大地降低了模型的复杂度和计算需求,为机器人在真实、未知环境中的自主导航提供了更实用、更强大的解决方案。
作者也指出了未来的改进方向:
更多样的目标模态: 目前目标仅限于图像,未来可以扩展到支持语言指令、GPS坐标等更多样的目标形式。
更智能的探索策略: 目前的高层探索策略仍然是基于传统的“前沿点探索”(frontier-based),未来可以结合语义信息或先验知识,进行更智能、更有目的性的探索。
Last updated
Was this helpful?