DepthAnything3 & SAM3 的笔记
@TOC
Depth Anything 3: Recovering the Visual Space from Any Views (2025)
输入 (Input):
任意数量的RGB图像 (可以是单张图片、多张无序图片或连续视频流)。
(可选) 相机位姿信息 (模型可处理已知位姿,也可处理完全未知的位姿)。
输出 (Output):
每张图像对应的 高精度深度图 (Depth Map)。
每张图像对应的 射线图 (Ray Map) (用于隐式表示相机几何信息)。
(由此导出的) 相机位姿 (Camera Poses) 和统一的 3D点云 (Point Cloud)。
解决的任务 (Task):
全能视觉空间恢复 (All-purpose Visual Space Recovery)。
DA3 旨在统一传统的单目深度估计、多视图立体几何 (MVS) 和相机位姿估计任务。它使用单一的 Transformer 模型,解决了从任意形式的视觉输入(无论是一张图还是多张图)中同时恢复一致的 3D几何结构 和 相机运动轨迹 的问题,且无需复杂的专用架构。
Motivation
背景与痛点: 传统的3D视觉任务(如单目深度估计、多视图立体几何MVS、SLAM、Structure-from-Motion)通常被视为独立的任务,拥有各自专用的模型架构。虽然近期出现了一些尝试统一这些任务的工作(如VGGT, DUSt3R),但它们存在显著局限性:
架构复杂且无法利用预训练模型: 往往需要重新设计复杂的架构,导致无法直接继承大规模预训练模型(如DINOv2)的强大特征提取能力。
训练目标冗余: 为了兼顾多任务,模型往往预测冗余的目标(如同时预测位姿、局部/全局点云、深度),导致优化困难。
数据困境: 真实世界的3D数据(如LiDAR)往往稀疏且充满噪声,难以直接用于训练高质量的几何模型。
DA3 的核心理念: DA3 提出了一种**“极简主义” (Minimalism)** 的策略。它试图回答两个核心问题:
是否需要复杂的专用架构? 答案是否定的。DA3 证明了一个标准的、未经修改的 Vision Transformer (ViT) 加上简单的 Token 重排,就足以处理任意数量的视图。
是否存在最小的预测目标集? 答案是肯定的。DA3 发现,仅预测深度 (Depth) 和 射线 (Ray) 就足以恢复完整的3D空间和相机位姿,无需显式回归复杂的旋转矩阵或冗余的点云图。
Methodology
这是论文最核心的部分,DA3 将“从任意视图恢复几何”定义为一个密集预测任务 (Dense Prediction Task)。
问题定义
输入是一个包含 N 张图像的集合。
如果 N=1,则是单目深度估计。
如果 N>1,则是多视图重建或视频处理。
输入可以是已知相机位姿(Posed),也可以是未知位姿(Unposed)。
模型的目标是为每一张输入图像 Ii,输出像素对齐的:
深度图 (Depth Map) Di
射线图 (Ray Map) Mi
核心创新:深度-射线表示
这是 DA3 能够统一位姿估计和几何重建的关键技术。
为什么要用射线图? 直接预测相机旋转矩阵 R 很难,因为必须满足正交性约束。DA3 选择隐式地通过“逐像素射线”来表示相机位姿。
射线图的定义: 对于图像中的每个像素 p,其对应的相机射线 r 定义为原点 t 和方向 d 的组合:
射线原点: 即相机的中心在世界坐标系下的位置。对于同一张图的所有像素,这个值理论上是相同的。
射线方向: 定义为像素在相机坐标系下的方向旋转到世界坐标系。
d=RK−1p注意: 这里的
d没有归一化。保留其模长是为了保持投影的尺度。
因此,一个像素 p 在世界坐标系下的3D点 P 可以简单地通过以下公式计算:
这种表示法使得模型输出的射线图(前3通道为原点,后3通道为方向)和深度图可以通过简单的元素级运算直接生成一致的点云。
从射线图中解算相机参数
虽然训练时预测的是密集的射线图,但在推理时我们可能需要明确的相机参数 (K,R,t)。DA3 设计了一套基于单应性 (Homography) 的解算方法:
计算相机中心: 直接对预测的密集射线原点求平均。
tc=H×W1h,w∑M(h,w,:3)解算旋转 R 和内参 K:
定义一个“单位相机”(Identity Camera),
其内参KI=I。其射线方向为dI=p。目标相机的射线方向与单位相机射线之间存在线性变换关系:
dcam=KRdI令
H = KR。这是一个单应性矩阵。问题转化为寻找一个矩阵H,使得它能将单位射线映射到模型预测的射线方向上。这是一个标准的最小二乘问题,可以通过 直接线性变换 (DLT) 算法求解。
求出
H*后,由于K是上三角矩阵,R是正交矩阵,可以通过 RQ分解 唯一地分离出K和R。
辅助相机头
尽管上述从射线图解算位姿的方法很精确,但在大规模推理时,对百万级像素进行DLT和SVD分解计算量过大。 因此,DA3 增加了一个轻量级的 Transformer Camera Head。
它只处理每张图对应的 Camera Token(见下文架构部分)。
直接回归预测:视场角 FOV (
f)、旋转四元数 (q)、平移向量 (t)。这在推理时极快,且实验证明其精度与密集射线解算相当。
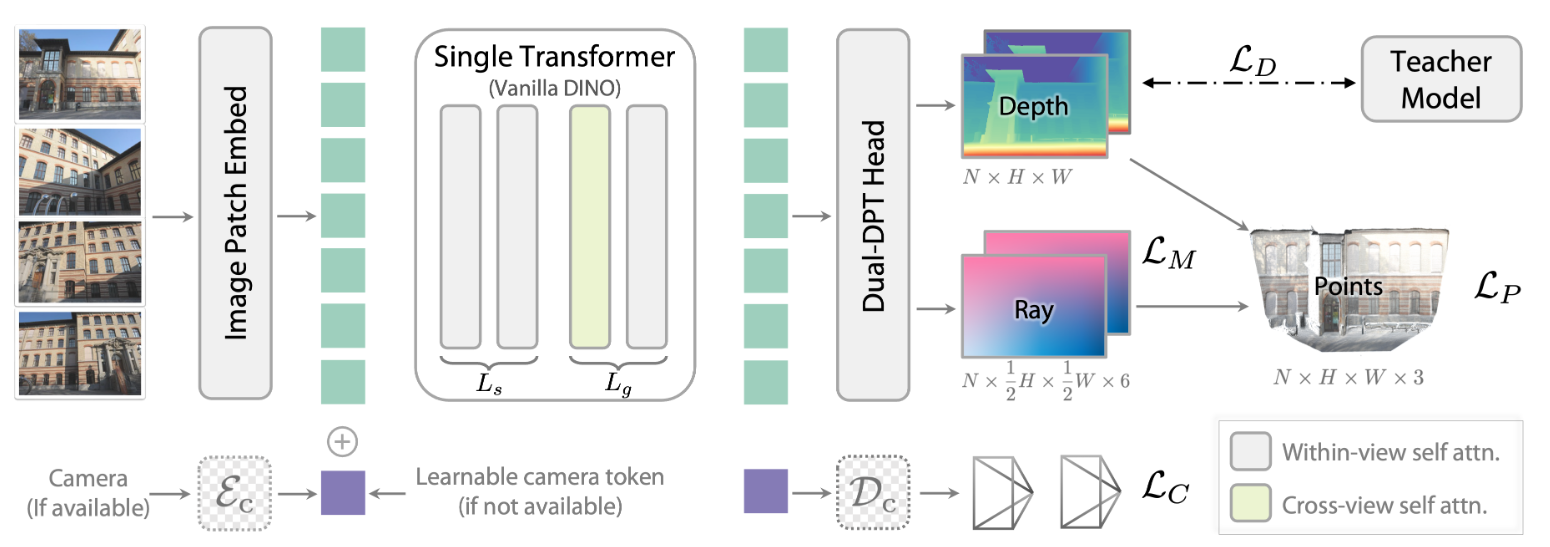
Architecture
DA3 的架构设计极度克制,旨在保持简洁并复用预训练权重。
单一 Transformer 骨干
使用标准的 ViT (如 DINOv2) 作为骨干网络。
不修改模型结构,不增加新的注意力层。
动态跨视图注意力
为了处理多视图之间的信息交互,DA3 并没有引入新的层(如Epipolar Attention),而是通过重排 Token (Rearranging Input Tokens) 来实现:
阶段一 (Within-View): 在前 Ls 层,保持 Token 结构不变,Attention 仅在单张图像内部进行(标准的自注意力)。
阶段二 (Cross-View): 在后 Lg 层,将所有图像的 Token 拼接到一起。此时的 Self-Attention 变成了跨视图注意力,允许不同图片之间的像素进行交互和匹配。
这种设计是“输入自适应”的:如果是单张图片输入,它就自动退化为标准的单目模型,没有额外计算开销。
相机条件注入
为了统一处理“已知位姿”和“未知位姿”的情况:
在每张图片的 Patch Tokens 序列前,插入一个 Camera Token ci。
已知位姿时: 通过一个 MLP 将
K, R, t编码成 embedding 作为 ci。未知位姿时: 使用一个可学习的、共享的 Token 作为 ci。
这个 Token 参与所有的 Attention 运算,充当几何上下文的载体。
双 DPT 头
解码器部分基于 DPT (Dense Prediction Transformer),但做了改进:
共享重组 (Reassemble): 特征图的提取和上采样是共享的。
双分支融合 (Dual Fusion): 在最后阶段分为两个分支,一个输出深度,一个输出射线。
这种设计既保证了两个任务共享底层特征,又避免了输出层的相互干扰。
数据流转
阶段 1:Image Patch Embed (图像块嵌入)
目标:将二维的像素图像转化为 Transformer 可以处理的一维 Token 序列。
输入数据:
假设输入了 N 张图像。
维度:
[N, 3, H, W](N张图,3通道RGB,高H,宽W)。
切块 (Patchify):
将每张图切成 14 x 14 的小方块。
块的数量:h = H/14,w = W/14。总块数 L = h x w。
维度变化:
[N, 3, H, W]→[N, L, 14*14*3]。
线性投影 (Linear Projection):
通过一个卷积层或全连接层,将每个 Patch 的像素值映射为特征向量,维度为 D。
维度变化:→
[N, L, D]。
注入相机 Token (Camera Token):
对于每张图,生成一个代表相机参数的 Token(维度 1 x D)。
将其拼接到 Patch Token 序列的最前面。
最终阶段 1 输出:
[N, L+1, D]。(注:这里的 N 是图片数量,(L+1) 是每张图的序列长度,包含1个相机Token和 L 个图像Patch)
阶段 2:Single Transformer (单一 Transformer 主干)
目标:在特征空间提取几何信息,并进行“图内”和“图间”的信息交互。
这个阶段虽然是一个单一的模型,但在计算 Attention 时有两种模式(通过 Reshape 张量实现,无需改变模型结构):
前半部分层 (Within-View Attention):
逻辑:每张图片只看自己,提取单张图的特征。
操作:保持输入维度不变,将 N 视为 Batch Size。
维度:
[N, L+1, D]→ Self-Attention →[N, L+1, D]。
后半部分层 (Cross-View Attention):
逻辑:模型需要对比不同视角的图片来推断 3D 结构(比如通过视差)。
操作:将所有图片的 Token 拼在一起,形成一个超长的序列。
变形:
[N, L+1, D]→[1, N * (L+1), D]。Attention:现在的 Attention 矩阵允许第 1 张图的 Patch 看到第 2、3 张图的 Patch。
还原:计算完后,再变回原来的形状。
维度:→
[N, L+1, D]。
提取多层特征:
为了做密集预测,DPT 需要用到 Backbone 中不同深度的特征(例如第 5, 11, 17, 23 层的输出)。
我们在输出前移除相机 Token,并将序列 Reshape 回二维特征图。
最终阶段 2 输出:4 个不同尺度的特征图列表。由于 ViT 是柱状结构,出来的特征图大小通常是一样的:
Feature 1:
[N, D, h, w]Feature 2:
[N, D, h, w]...
阶段 3:Dual-DPT Head (双分支 DPT 解码头)
目标:将提取的高维特征解码为像素级的深度图和射线图。
这里是 DA3 的创新点。DPT (Dense Prediction Transformer) 通常包含“重组(Reassemble)”和“融合(Fusion)”两步。
重组 (Reassemble) - 共享模块:
ViT 输出的特征图通常分辨率是固定的 (1/14)。
Reassemble 模块使用卷积和上/下采样,将那 4 个特征图转化为类似 ResNet 的金字塔结构(分辨率从 1/4 到 1/32 不等,通道数也调整)。
数据:变成了一组多尺度的特征图 {f_1, f_2, f_3, f_4}。
双路融合 (Dual Fusion) - 独立模块:
这里分叉了!虽然输入特征是一样的,但有两套独立的融合路径。
路径 A (Depth):使用一套权重将 {f_1, f_2, f_3, f_4} 从低分辨率逐级上采样并融合到高分辨率。
路径 B (Ray):使用另一套完全独立的权重进行同样的融合操作。
为什么? 因为深度(标量)和射线(向量)的物理意义不同,需要不同的解码参数。
预测头 (Prediction Heads):
Depth Head:
输入:融合后的高分辨率特征。
操作:卷积投影到 1 通道,双线性插值上采样回 H x W。
输出维度:
[N, H, W](每张图每个像素 1 个深度值)。
Ray Head:
输入:融合后的高分辨率特征(Ray 分支的)。
操作:卷积投影到 6 通道(前3通道是射线原点 t,后3通道是射线方向 d),上采样回 H x W。
输出维度:
[N, 6, H, W](每张图每个像素 6 个数值)。
数据维度变化全景
输入
原始图片
[N, 3, H, W]
N张图片
阶段 1
Patch Embedding
[N, h*w, D]
变为一维序列
+ Camera Token
[N, h*w+1, D]
增加1个Token
阶段 2
Transformer
[N, h*w+1, D]
形状保持不变 (内部 reshape 做 Cross-view)
提取特征 (Reshape)
List of [N, D, h, w]
变回二维特征图,移除相机Token
阶段 3
Reassemble
List of Pyramids
变为多尺度特征金字塔
分支 A (Depth)
↓
独立融合
Output A
[N, H, W]
最终深度图
分支 B (Ray)
↓
独立融合
Output B
[N, 6, H, W]
最终射线图
训练策略:教师-学生范式
DA3 的成功在很大程度上归功于其训练数据的处理方式。
为什么要用 Teacher?
真实世界的3D数据(如 ScanNet, 7Scenes)的 Ground Truth (GT) 深度往往是稀疏的、有噪声的,且缺乏高频细节。直接用这些数据训练会导致模型学不到精细的几何结构。
构建 Teacher 模型
训练一个强大的单目深度估计模型作为 Teacher。
数据: 仅使用合成数据(Synthetic Data, 如 Hypersim, TartanAir)训练 Teacher。合成数据的深度是完美、稠密且无噪声的。
预测目标: Teacher 预测的是 Scale-Shift-Invariant 的深度 (Depth)(不同于 DA2 预测视差 Disparity)。对于近处物体,采用指数深度表示以增加区分度。
伪标签对齐
在训练 DA3 (Student) 时,使用真实图片:
Teacher 生成高质量、稠密的相对深度。
数据集提供稀疏、含噪的绝对深度 (Metric Depth)。
RANSAC 对齐: 使用 RANSAC 算法计算线性变换参数(Scale
s和 Shiftt),将 Teacher 的预测对齐到真实的稀疏深度上。Daligned=s⋅Dteacher+tStudent 学习这个对齐后的稠密深度。这既保留了真实世界的度量尺度,又学会了合成数据级别的精细细节。
损失函数
训练目标包含多项 Loss 的加权和:
深度损失 LD: 预测深度与 GT/伪标签的 L1 Loss。
射线损失 LM: 预测射线图与 GT 射线的 L1 Loss。
重投影点云损失 LP: 显式约束生成的 3D 点云
P的一致性。表面法向量损失 (Surface Normal Loss): 这是一个改进点。不仅计算梯度的 Loss,还通过采样邻域点计算几何法向量,强制模型学习平滑且准确的表面细节。
实验与总结
基准测试 (Benchmark): 作者建立了一个新的 Visual Geometry Benchmark,包含相机位姿估计、几何重建精度、新视图合成质量等多个维度。
结果:
位姿估计: DA3 在 ScanNet++ 等数据集上大幅超越 SOTA (如 VGGT, DUSt3R),提升约 35.7%。
几何重建: 重建精度提升约 23.6%。
单目能力: 即使回退到单目模式,其性能也超越了 Depth Anything 2。
应用:前馈 3D Gaussian Splatting (Feed-Forward 3DGS) 作者展示了 DA3 可以作为一个通用的几何基座。通过微调一个轻量级的 Head 来预测 3D 高斯参数,DA3 在新视图合成 (NVS) 任务上也击败了专门设计的模型(如 pixelSplat, MVSplat)。
Depth Anything 3 的核心在于 “去繁就简”。它证明了不需要复杂的几何偏置网络,只需一个强大的预训练 Transformer,配合 “射线图” 这一精巧的表示法和 “教师-学生” 的高质量数据策略,就能统一单目、多目、有姿态、无姿态的各种3D感知任务。这是一篇将 3D Vision Foundation Model 推向实用化的重要论文。
SAM 3: Segment Anything with Concepts (2025)
输入 (Input):
一张 图像 (Image) 或一段 视频 (Video)。
概念提示 (Concept Prompts):主要是 文本(简短的名词短语,如“黄色校车”)或 图像示例(Exemplars,即给一张参考图),也可以是两者的多模态组合。
(可选)传统的视觉提示(点、框),用于交互式地修正结果。
输出 (Output):
图像或视频中 所有 符合该概念对象的 实例分割掩码 (Instance Masks)。
如果在视频中,输出 具有跨帧一致性ID的对象轨迹 (Object Tracks/Masklets)。
解决的任务 (Task):
提示驱动的概念分割 (Promptable Concept Segmentation, PCS)。传统的SAM 1/2只能根据位置提示(点/框)分割单个物体,且不理解语义;SAM 3 能够理解语义概念,自动检测、分割并跟踪场景中符合该概念的所有实例(例如“分割视频里所有的猫”)。
它弥合了开放词汇检测(Open-Vocabulary Detection)与高质量交互式分割(Promptable Segmentation)之间的差距,利用解耦的“识别-定位”架构,在保证掩码质量的同时实现了对任意概念的语义理解和视频跟踪。
Motivation
现有技术的局限性:
SAM 1 & SAM 2 的局限: 之前的SAM系列模型主要专注于Promptable Visual Segmentation (PVS)。用户给一个点或框,模型分割出对应的单个物体。虽然几何分割能力极强,但它们缺乏语义理解。例如,你不能直接告诉SAM 2“分割视频里的所有猫”,你必须手动点击每一只猫。
开放词汇分割(Open-Vocabulary Segmentation)的不足: 现有的开放词汇检测/分割模型(如OWLv2, GroundingDINO等)虽然能理解文本,但在分割的精细度(Mask Quality)和视频跟踪的一致性上,往往不如SAM系列。
识别与定位的冲突: 在开放世界检测中,模型既需要知道“这个物体是不是在这个图里”(识别),又需要知道“它具体在哪里”(定位)。强行让所有的Object Queries同时负责这两件事(特别是在处理负样本短语时)会导致性能下降。
SAM 3 的目标: 提出 Promptable Concept Segmentation (PCS) 任务。给定一个概念提示(文本或图像示例),模型需要:
检测、分割并跟踪输入中符合该概念的所有实例。
保持SAM系列的高质量掩码和交互能力。
能够处理视频中的物体一致性。
核心任务定义
在深入模型之前,必须理解SAM 3定义的PCS任务:
输入: 图像或视频 + 概念提示(Concept Prompt)。
概念提示可以是:短名词短语(如 "yellow school bus")、图像示例(Exemplar)、或者二者的结合。
输出: 所有匹配该概念的对象的实例掩码(Instance Masks)、语义掩码,并在视频中保持ID一致性。
约束: 文本限制为原子性的名词短语,不包含复杂的引用表达(Referring Expressions,如“那个坐在椅子上的男人”)。复杂的推理交由上层的 SAM 3 Agent(结合MLLM)处理。
Method
SAM 3 的架构是 检测器(Detector) 和 跟踪器(Tracker) 的统一体,它们共享同一个视觉编码器。
统一的主干网络
SAM 3 没有使用SAM 2的Hiera(MAE预训练),而是采用了 Perception Encoder (PE)。
原因: SAM 2的MAE骨干几何能力强但语义弱。SAM 3需要理解开放词汇文本,因此需要一个像CLIP一样图文对齐的特征空间。
实现: PE使用对比学习在54亿图文对上进行预训练。SAM 3使用PE的图像编码器处理视频帧,只需提取一次特征,供检测器和跟踪器共用。
图像检测器架构
这是SAM 3的核心创新部分,基于DETR架构但在多个方面进行了针对性改进。
输入编码 (Encoders):
图像编码器: 输出非条件化的图像Embedding。
文本编码器: 编码文本提示。
几何与示例编码器 (Geometry and Exemplar Encoder): 这是一个关键组件。它不仅像SAM 2一样处理点/框提示,还专门用于编码图像示例(Image Exemplars)。如果用户提供一张“参考猫”的图片,该编码器提取其ROI特征和位置嵌入。
融合编码器 (Fusion Encoder): 将图像Embedding与“提示Tokens”(文本+示例)进行交叉注意力(Cross-Attention)融合,输出条件化帧嵌入 (Conditioned Frame-Embeddings)。
解码器 (Decoder):
标准的Transformer解码器,包含6层。
使用 Learned Object Queries(学习到的对象查询向量)。
Queries通过自注意力相互通信,并通过交叉注意力从“提示Tokens”和“条件化帧嵌入”中获取信息。
输出: 边界框(Box)和分类分数。
Presence Head (存在性预测头) —— 核心创新点:
问题: 传统的DETR直接预测 p(queryi matches NP) 这要求每个Query不仅要定位好,还要判断整个图片里到底有没有这个物体(全局上下文)。这对于局部Query很难。
解决方案: 解耦识别(Recognition)与定位(Localization)。
引入一个全局的 Presence Token。
公式分解:
p(queryi matches NP)=p(queryi matches NP∣NP present)⋅p(NP present)实现细节:
Global: Presence Token 经过一个MLP,预测该概念出现在图像中的全局概率 p(NP present)
Local: Object Queries 只需要预测“如果该物体存在,我是不是最佳匹配”。
推理时: 最终得分为两者的乘积。
优势: 极大地提高了对负样本短语(Hard Negatives)的鲁棒性。如果模型确信“图像里没有狗”,Global分数接近0,所有的Query分数都会被压低,从而减少误检。
Ambiguity Head (歧义处理头):
问题: 文本具有多义性。例如 "conductor" 既可以是“列车员”也可以是“导体”。
解决方案: 混合专家模型(Mixture of Experts, MoE)。
模型并行训练 K 个专家(实验中 K=2 效果最好)。
训练策略 (Winner-Takes-All): 计算所有专家的Loss,只对Loss最小的那个专家进行梯度回传。这样不同的专家会专门负责不同的语义解释。
推理时: 训练一个额外的分类头来预测哪个专家的解释最可能是用户想要的。
Mask Head:
改编自MaskFormer,基于解码器的输出和条件化特征生成最终的分割掩码。
视频跟踪器与推理
SAM 3 的视频处理结合了检测器的强语义能力和SAM 2的强时序传播能力。
架构继承: 跟踪器部分直接继承自SAM 2,拥有记忆库(Memory Bank)、记忆注意力(Memory Attention)和记忆编码器。
跟踪逻辑 (The Loop): 对于视频的每一帧 t:
Step 1: 传播: 跟踪器利用记忆库,将上一帧 t-1 的掩码 $M_{t-1}$ 传播到当前帧,得到预测 $\hat{M}_t$。这处理了物体的运动和形变。
Step 2: 检测: 检测器在当前帧 It 上独立运行,找到所有符合文本提示的新物体 Ot。
Step 3: 匹配与更新:
使用IoU(交并比)作为匹配函数,将跟踪器的预测 $\hat{M}_t$ 与检测器的结果 Ot 进行关联。
未匹配的检测框被视为新出现的物体,初始化新的Tracklet。
已匹配的轨迹利用检测结果进行校准。
时序消歧策略 (Temporal Disambiguation Strategies): 为了解决视频中遮挡、拥挤场景下的ID跳变问题,SAM 3引入了精细的逻辑:
Masklet Detection Score (MDS): 一个轨迹在时间窗口内与检测器结果匹配的一致性得分。如果MDS过低,说明跟踪器可能“跟丢了”或者产生了幻觉,该轨迹会被抑制。
Track Confirmation Delay: 不立即输出新发现的物体,而是延迟 T 帧(例如15帧)。只有当物体在后续帧中持续被检测到,才确认为有效轨迹。这有效过滤了闪烁的误检。
Periodic Re-Prompting (周期性重提示): 每隔 N 帧,或者当跟踪置信度低但检测置信度高时,强制使用检测器的Mask重置跟踪器的状态。这能把跑偏的跟踪拉回来。
数据引擎
SAM 3 的成功很大程度上归功于其构建的庞大、高质量数据集(SA-Co)。这是一个**人机回环(Human-in-the-loop)**的系统。
Phase 1: Human Verification: 使用现有的检测器(如OWLv2)生成伪标签,人类只负责“是/否”的验证。
Phase 2: Human + AI Verification (关键提速):
训练了一个基于Llama的多模态模型作为 AI Verifier。
Mask Verification (MV): AI判断掩码质量好坏。
Exhaustivity Verification (EV): AI判断是否漏检了物体(即掩码是否覆盖了所有实例)。
这一步将标注效率提升了2倍,使模型能够从大规模噪声数据中学习。
Phase 3: Scaling & Domain Expansion:
利用AI挖掘网络上的长尾概念(Long-tail concepts)和困难负样本(Hard Negatives)。
生成合成数据(Synthetic Data),并用AI Verifier清洗。
Phase 4: Video Annotation:
将上述流程扩展到视频,重点标注那些跟踪失败的拥挤场景。
最终产出:
SA-Co-HQ: 5.2M 图片,4M 独特概念,高质量人工/AI验证标注。
SA-Co-SYN: 39M 图片,大规模合成数据。
Experiments
基准测试: 提出了 SA-Co Benchmark,包含207K个独特概念,比现有的LVIS等数据集大50倍以上。
性能对比:
在LVIS上,Zero-shot AP达到 48.8(现有最佳OWLv2为38.5)。
在SA-Co Benchmark上,性能是现有基线的 2倍以上。
视频分割性能也大幅超越现有SOTA。
消融实验: 证明了 Presence Head 和 Hard Negative Training 对性能提升至关重要。
总结
SAM 3 是“分割一切”从几何层面迈向语义层面的关键一步。它的核心技术亮点在于:
统一架构: 使得图像检测和视频跟踪在同一特征空间下无缝协作。
解耦设计 (Presence Head): 巧妙地解决了开放世界检测中“是否存在”与“在哪”的矛盾。
数据引擎: 利用AI辅助标注(LLM as Judge/Verifier)实现了对千万级概念的高质量覆盖,这是模型泛化能力的根本来源。
SAM 3D: 3Dfy Anything in Images (2025)
输入 (Input):
一张单视角的 RGB自然图像 (Real-world image),通常包含复杂的背景或遮挡。
一个指示目标物体的 2D分割掩码 (Segmentation Mask) (通常结合SAM模型生成)。
(可选) 场景的 稀疏深度图/点图 (Pointmap),用于辅助更精确的布局估计。
输出 (Output):
目标物体的 3D几何形状 (Geometry/Shape)。
目标物体的 高保真纹理 (Texture)。
物体在相机坐标系下的 3D布局 (Layout) (包含6D旋转、平移和缩放)。
(最终形式) 可直接用于渲染或编辑的 3D网格 (Mesh) 或 3D高斯 (3D Gaussian Splats)。
解决的任务 (Task):
真实场景下的视觉引导3D物体重建。与以往仅能在去背景的合成图像上工作的模型不同,SAM 3D 能够在复杂、杂乱且存在遮挡的自然图像中,利用上下文信息恢复物体的完整3D结构。
全景3D化 (3Dfy)。不仅仅重建形状,还同时解决“放在哪里”的问题(Pose/Layout),将2D照片中的物体逆向映射回3D空间,实现从单张照片到可组合3D场景的转换。
Motivation
核心痛点:自然场景下的3D重建缺乏数据与鲁棒性。
从“多视图几何”到“视觉认知”的转变: 传统的计算机视觉依赖多视图几何(如SfM, SLAM)来恢复3D结构。但在单张图像中,人类依靠的是“识别”和“先验知识”(Pictorial Cues)。现有的单图转3D模型(如Trellis, LRM等)通常是在去背景的、孤立的合成数据集(如Objaverse)上训练的。
泛化能力差: 当这些模型应用于真实世界的自然图像时,由于复杂的遮挡(Occlusion)、杂乱的背景(Clutter)以及缺乏绝对尺度信息,表现往往很差。
数据壁垒(Data Barrier): 最大的挑战在于缺乏大规模的**“自然图像-3D真值”**成对数据。人类标注员很难凭空为一个自然图像中的物体创建完美的3D模型,也很难精准地标定其在3D空间中的位置。
SAM 3D的解决方案: 通过构建一个 人机回环(Human- and Model-in-the-Loop, MITL) 的数据引擎,结合合成数据预训练(Pretraining)和真实世界对齐(Real-world Alignment),像训练LLM一样训练3D大模型,通过SFT(监督微调)和DPO(直接偏好优化)让模型适应真实世界。
Architecture
SAM 3D 采用了一种两阶段的基于流匹配(Flow Matching)的生成架构,并支持输出 Mesh 或 3D Gaussian Splats。
输入编码
模型利用 DINOv2 作为图像编码器,提取强语义特征。为了兼顾细节和全局上下文,输入包含四组Token:
Cropped Object: 基于Mask裁剪的物体图像特征(提供高分辨率细节)。
Full Image: 全图特征(提供场景上下文、光照、遮挡关系)。
Binary Masks: 对应的物体掩码。
(可选) Pointmap: 粗糙的场景深度/点云图(如果由传感器或深度估计模型提供),用于辅助布局预测。
第一阶段:几何模型
目标: 预测物体的粗糙形状(Coarse Shape) 和 布局(Layout: Rotation
R, Translationt, Scales)。核心架构:Mixture of Transformers (MoT)
为了同时处理高维的形状Token(4096个)和低维的布局Token(1个),模型采用了MoT架构。
双流设计: 包含两个Transformer,一个专注于Shape,一个参数共享但专注于Layout。
交互机制: 通过多模态自注意力层(Multi-Modal Self-Attention)进行信息交互,但保持参数和处理流的独立性。这允许模型在训练时对不同模态(如只微调Layout)进行解耦控制。
生成方式: 基于流匹配(Flow Matching),将噪声去噪为 163 x 8 的潜在体素特征。
第二阶段:纹理与精细化模型
目标: 基于粗糙形状,生成精细几何细节和纹理。
核心架构:Sparse Latent Flow Transformer (SLAT)
它只处理粗糙形状中的“活跃体素”(Active Voxels),通过稀疏注意力机制提高效率。
它以上一阶段的粗糙形状为条件,生成高分辨率的潜在特征。
3D解码器
Depth-Aware VAE (深度感知变分自编码器):
这是本文的一个技术改进点(在Appendix C.6)。
传统的VAE会将图像特征反向投影到所有体素,导致遮挡部分产生伪影(如物体底部变黑)。
改进: 仅将特征投影到当前视角下可见的体素上(利用深度图过滤)。
解码器可以将潜在特征解码为 Mesh(网格) 或 3D Gaussian Splats(高斯泼溅)。
Method
这是文章最精华的部分,SAM 3D 复用了 LLM 的训练范式:Pretraining(预训练) -> Mid-training(中期训练/持续预训练) -> Post-training(后训练/对齐)。
Step 1: 合成数据预训练
数据集 (Iso-3DO): 约270万个来自Objaverse-XL等数据集的合成3D物体。
训练目标: 学习基础的3D形状和纹理先验。
形式: 渲染孤立物体的图像,训练模型从图像重建3D。
规模: 训练了2.5 Trillion (2.5万亿) token。
Step 1.5: 半合成中期训练
为了让模型学会处理“遮挡”和“场景布局”,但又利用合成数据的精确3D真值,作者构建了 RP-3DO (Render-and-Paste) 数据集。
Render-and-Paste (渲染并粘贴) 技术:
Flying Occlusions (FO): 将渲染的3D物体随机粘贴到自然图像上作为遮挡物。这迫使模型学习形状补全(Shape Completion),即不仅重建可见部分,还要推断被遮挡的部分。
Object Swap (OS): 这是一个更高级的策略。
利用2D分割Mask和深度估计,将自然图像中的真实物体“挖掉”。
在原位置“填入”一个形态相似的合成3D物体(保持合理的深度关系)。
目的: 创造出既有真实背景上下文,又有完美3D真值(Layout和Shape)的数据。这让模型学会了Mask-following(遵循掩码)和Layout estimation(布局估计)。
Step 2: 真实世界对齐与数据引擎
这是SAM 3D能够处理真实照片的关键。作者构建了一个 MITL(Model-In-The-Loop) 数据管道,生成了名为 SA-3DAO 的基准和训练集。
数据引擎的工作流 (The Data Flywheel):
Stage 1: 目标选择 (Choosing Target Objects)
从海量自然图像(如SA-1B)中,利用SAM模型和人工筛选,确定要重建的目标物体Mask
M。
Stage 2: 形状与纹理选择 (Object Model Ranking and Selection)
生成/检索: 对于给定的物体,使用当前的SAM 3D模型(或早期的检索模型、其他SOTA模型)生成
N个3D候选模型。人类反馈 (Best-of-N): 标注员从
N个候选中选出最好的一个,并打分。专家介入 (Artist Loop - Art-3DO): 这是一个关键设计。如果模型生成的所有
N个结果都很差(通常是长尾物体或复杂结构),这些样本会被路由给专业3D艺术家。价值: 艺术家手动创建的高质量Mesh(Art-3DO)是极其宝贵的“种子数据”,用于教会模型它目前完全不会的概念,从而“推平”数据分布的长尾部分。
Stage 3: 场景布局对齐 (Aligning Objects to 2.5D Scene)
标注员在一个交互界面中,将选定/创建的3D物体,放置回原图生成的2.5D点云(由单目深度估计得到)中。
标注员调整
R(旋转),t(平移),s(缩放),使其与点云完美贴合。
后训练策略 (Post-Training Strategy): 利用上述引擎收集的数据(约100万张图像,300万个Mesh),进行两个阶段的训练:
SFT (Supervised Fine-Tuning):
直接在收集的高质量数据(MITL-3DO 和 Art-3DO)上微调模型。这让模型从“合成域”迁移到“真实域”。
DPO (Direct Preference Optimization):
为了进一步对齐人类审美和物理合理性(如对称性、完整性),作者采用了DPO。
数据对: 使用数据引擎Stage 2中产生的“胜者”(Winner, xw)和“败者”(Loser, xl)。
目标函数: 优化模型使得生成 xw 的概率远大于 xl。
核心损失函数与公式
1. 基础流匹配损失 (Conditional Rectified Flow Matching): 模型学习一个速度场 vθ 来拟合从噪声 x0 到数据 x1 的直线轨迹。
其中 m 代表不同的模态(形状、旋转、平移等),c 是条件(图像、Mask)。
2. DPO损失 (针对流匹配的适配): 作者将Diffusion-DPO适配到了Flow Matching中。核心思想是增加Preferred样本的似然,降低Dis-preferred样本的似然。
其中 Δ 是两个样本在模型下的误差差值:
这里省略了参考模型项(Reference Model)以简化理解,实际计算中需要减去参考模型的误差。
3. 模型蒸馏 (Model Distillation - Shortcut Models):
为了加速推理(从25步减少到4步),作者使用了Shortcut Models技术。这不是简单的减少步数,而是训练模型预测“未来一步跨越 d 步”的结果。
这结合了标准流匹配损失和**自一致性(Self-Consistency)**损失。
总结
SAM 3D 是一篇工程与算法并重的工作。
算法上: 它是目前SOTA的基于Flow Matching的3D生成模型,支持多模态(Shape+Layout+Texture)联合生成。
数据上(最重要): 它揭示了如何通过 合成数据 -> 半合成数据(Render-Paste) -> 人机回环真实数据(MITL + Artists) 的路径,解决真实世界3D重建数据匮乏的问题。特别是引入3D艺术家处理长尾困难样本(Art-3DO),并在训练中引入DPO,是其效果大幅超越前人(如Trellis, LRM)的关键原因。
SAM 3D Body: Robust Full-Body Human Mesh Recovery (2025)
输入 (Input):
一张包含人物的 单目RGB图像。
(可选) 用户或系统提供的 提示 (Prompts),如2D关键点、分割掩码 (Masks) 或边界框。
(可选) 手部裁剪图像 (用于增强手部细节)。
输出 (Output):
3D人体网格模型,具体为 Momentum Human Rig (MHR) 参数(包含解耦的骨架结构、身体形状、姿态和相机参数)。
高保真的 全身 (身体+双手) 3D重建结果。
解决的任务 (Task):
鲁棒的单目全身3D人体网格恢复 (Full-Body HMR)。
解决现有模型在“野生”场景(严重遮挡、罕见姿态、非常规视角)下表现不佳的问题。
实现可提示 (Promptable) 的3D重建,允许用户通过交互式提示来引导或修正模型预测,同时在一个统一框架下精确恢复身体整体和手部细节。
Motivation
尽管近年来 3D 人体网格恢复(HMR)取得了显著进展,但在实际应用(如机器人、生物力学)中,现有模型在处理非受控场景图片时仍表现出鲁棒性不足。主要挑战归结为以下几点:
数据稀缺与质量问题:
高质量的“图像-3D网格”配对数据获取昂贵且困难。
现有数据集要么是在实验室环境下采集,缺乏多样性;要么依赖伪标签(pseudo-labeling),导致网格质量低且包含系统性误差。
模型往往在常见姿态上过拟合,而在罕见姿态、严重遮挡或非常规视角下失效。
模型架构的局限性:
现有架构难以同时兼顾身体整体姿态和手部精细姿态的优化。身体和手部在输入分辨率、相机估计和监督目标上存在冲突。
缺乏交互性:大多数模型是“黑盒”预测,无法利用用户的提示(如点击、关键点)来修正模糊或困难的预测。
人体表示模型的缺陷:
大多数工作基于 SMPL 模型。SMPL 将骨架结构(skeleton structure)和软组织形状(shape)纠缠在一起,导致参数的可解释性和可控性较差(例如,改变形状参数可能会意外改变骨骼长度)。
核心解决方案: Meta 提出了 SAM 3D Body (3DB),这是一个**可提示(Promptable)**的 HMR 模型。
新表示:首次使用 Momentum Human Rig (MHR),这种新的参数化模型解耦了骨架结构和表面形状。
新数据引擎:构建了一个基于视觉语言模型(VLM)的数据引擎,挖掘了 700万 张具有挑战性的图像,并通过多阶段标注流水线获取高质量注释。
新架构:采用 Encoder-Decoder 架构,支持辅助提示(如 2D 关键点、掩码),并设计了独立的身体和手部解码器。
Architecture
3DB 的目标是从单张图像中恢复准确、鲁棒且可交互的 3D 人体网格(即预测 MHR 参数)。
总体设计
模型采用 可提示的 Encoder-Decoder 架构(类似于 SAM),包含以下核心组件:
图像编码器 (Image Encoder):提取图像特征。
提示编码器 (Prompt Encoder):处理用户输入的 2D 关键点、掩码等提示。
双解码器 (Dual Decoders):包含 Body Decoder 和 Hand Decoder,分别负责全身和手部的预测。
人体表示:Momentum Human Rig (MHR)
与 SMPL 不同,MHR 显式地解耦了 骨架结构 (Skeletal Structure) 和 身体形状 (Body Shape)。模型预测的参数集合为 θ={P,S,C,Sk}
P:姿态 (Pose)
S:形状 (Shape)
C:相机参数 (Camera pose)
Sk:骨架参数 (Skeleton)
Method详细拆解
输入处理与编码
输入图像
I经过归一化和裁剪。使用视觉骨干网络(如 ViT-H 或 DINOv3)生成密集特征图
F。可选的手部裁剪:如果提供手部裁剪图像 Ihand,同样通过编码器提取手部特征图 Fhand。
F=ImgEncoder(I),Fhand=ImgEncoder(Ihand)
解码器 Token 设计
解码器通过查询 Token(Query Tokens)来预测参数。3DB 设计了四种类型的 Token,这种设计赋予了模型极强的灵活性和交互能力。
MHR+Camera Token:
这是用于预测核心 MHR 参数和相机参数的 Token。
它是一个可学习的嵌入向量
E经过编码后的结果。
Tpose=RigEncoder(Einit)∈R1×D2D Keypoint Prompt Tokens:
这是实现“可提示”功能的关键。如果用户或检测器提供了 2D 关键点
K,模型会将其编码为 Token。每个关键点包含 (x, y, label)。
Tprompt=PromptEncoder(K)∈RN×DHand Position Tokens:
用于在身体解码器中定位手部位置。这是一个可选 Token,即使没有它,身体解码器也能输出含手部的全身结果。
Thand∈R2×DAuxiliary Keypoint Tokens:
为了增强模型对特定关节的推理能力和交互性,引入了针对所有 2D 和 3D 关键点的可学习 Token。
这些 Token 允许模型显式地推理每个关节的位置,不仅限于回归最终网格参数。
Tkeypoint2D∈RJ2D×D,Tkeypoint3D∈RJ3D×D
解码器 (MHR Decoder) 工作流
所有的 Token 被拼接在一起形成完整的查询集合 T:
Body Decoder(身体解码器):
利用交叉注意力机制(Cross-Attention),让查询 Token
T与全图特征F进行交互。输出 O=Decoder(T,F)
输出中的第一个 Token 经过一个 MLP 层,直接回归出最终的 MHR 网格参数 θ。
Hand Decoder(手部解码器 - 可选):
这是一个专门的设计,为了解决手部在全图分辨率下特征不清晰的问题。
它接收同样的提示信息,但与手部裁剪特征 Fhand 进行交互。
输出 Ohand,用于计算更精细的手部 MHR 参数。
融合策略:在推理时,可以将手部解码器的预测结果与身体解码器的结果合并,以获得更高保真度的手部细节。
训练损失函数
3DB 使用多任务损失函数进行训练: Ltrain=∑iλiLi
2D/3D Keypoint Loss:
使用 L1 损失监督关节位置。
引入了可学习的**每关节不确定性(per-joint uncertainty)**来调节损失权重(置信度越低,权重越小)。
归一化:在计算损失前,以骨盆(针对身体)和手腕(针对手部)为中心进行归一化。
提示一致性:如果用户提供了关键点提示,会增加该点的损失权重,强制模型输出与提示一致。
Parameter Losses:
对 MHR 参数(姿态、形状)使用 L2 回归损失。
关节限制惩罚:防止生成解剖学上不可能的姿态。
Hand Detection Loss:
模型内置了一个手部检测器。使用 GIoU 损失和 L1 损失来监督手部边界框的回归。
如果在推理时检测到手部被遮挡,模型会自动关闭手部解码器。
推理策略
默认模式:使用身体解码器的输出。
增强模式:如果检测到手部,且未被遮挡,则运行手部解码器。
融合(Merge):利用手腕和手肘的关键点作为“锚点”,将手部解码器的高精细度预测对齐并拼接到全身网格上。
数据引擎
为了解决数据多样性问题,作者开发了一个基于 VLM 的数据挖掘和标注引擎。
VLM 驱动的挖掘策略
不依赖随机采样,而是利用 VLM(视觉语言模型)来寻找高价值、高难度的图像。
失败分析闭环:
在当前数据上运行 3DB。
找到预测失败(误差大)的样本。
人工用简短文字描述这些失败案例(例如:“做倒立的人”、“被部分遮挡的舞者”)。
将这些描述作为提示词输入 VLM,在海量图库中检索相似的困难图像。
将新挖掘的图像送入标注流水线。
覆盖场景:遮挡、罕见姿态(杂技)、人与物体交互、极端尺度、低能见度等。
多阶段标注流水线
如何为这些“野生”图片获取高质量 3D 真值?
人工标注 (Manual Annotation):人工修正 2D 关键点,并标记可见性(遮挡处理)。
单图网格拟合 (Single-Image Mesh Fitting):
使用高容量的检测器预测密集 2D 关键点。
使用 3DB 的当前版本初始化 MHR 参数。
优化:通过梯度下降优化 MHR 参数,最小化投影误差。
约束:引入了几何约束、参数先验(防止漂移)和正则化项。
多视角网格拟合 (Multi-View Mesh Fitting):
对于视频或多视角数据,利用时空一致性。
先三角化生成稀疏 3D 关键点,再结合时间平滑性(Temporal Smoothness Loss)进行联合优化。
最终构建了包含 700万 张带有高质量标注的图像数据集,并在新的 SA1B-Hard 基准上进行了评估。
总结
SAM 3D Body 的核心贡献在于:
全能性:统一了身体和手部的高精度恢复。
可控性:通过 Promptable 架构(Token机制)实现了用户交互。
鲁棒性:通过 VLM 数据引擎专门攻克“长尾”和困难样本。
解耦性:使用 MHR 替代 SMPL,实现了骨架与形状的解耦。
最后更新于